爬虫学习——网页解析器Beautiful Soup
2021-06-30 21:04
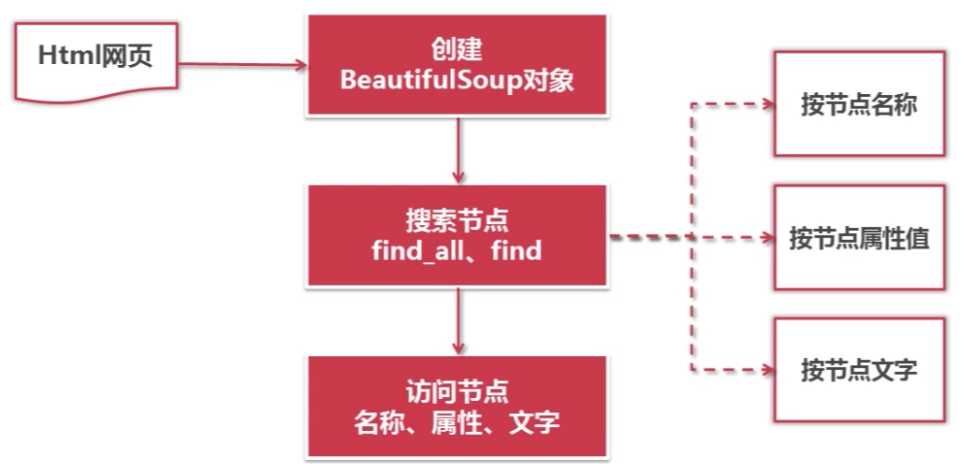
标签:匹配 输入 名称 ext htm 官方 rom 情况 模块 一.Beautiful Soup的安装与测试 官方网站:https://www.crummy.com/software/BeautifulSoup/ Beautiful Soup安装与使用文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ 1.首先测试一下bs4模块是否已经存在,若不存在再安装即可,我用的是kali测试发现bs4模块已经存在,下面介绍如何测试与安装 新建python文档输入以下代码 显示一下结果即说明bs4模块已经存在,其他情况则需要安装 安装代码如下 之后再进行测试即可 就会显示出来这时就说明 Beautiful Soup 安装已经完成 二、Beautiful Soup的语法 find_all:搜索出满足要求的所有节点 find:搜索出满足要求的第一个节点 二者的参数是一样的 2.按照节点名称、属性值、文字进行的搜索 3.创建Beautiful Soup对象相应的代码 4.搜索节点(find_all,find) find_all(name节点名称,attrs节点属性,string节点文字) 5.得到节点后访问节点信息 通过以上创建bs4对象,搜索DOM树,访问节点的内容,就可以实现对整个下载好的网页 所有节点的解析和访问。下一篇博文将给一个完整的示例代码 爬虫学习——网页解析器Beautiful Soup 标签:匹配 输入 名称 ext htm 官方 rom 情况 模块 原文地址:http://www.cnblogs.com/ryuuku/p/7134492.html
1 import bs4
2 print bs4

1 sudo apt-get install python-pip2
3 sudo pip install beautifulsoup4
1 from bs4 import BeautifulSoup
2
3 #根据HTML网页字符串创建BreautifulSoup对象
4 soup = BeautifulSoup(
5 html_doc, #HTML文档字符串
6 ‘html.parser‘ #HTML解析器
7 from_encoding=‘utf-8‘ #HTML文档的编码
8 )
1 # 方法:find_all(name,attrs,string)
2
3 #查找所有标签为a的节点
4 soup.find_all(‘a‘)
5
6 #查找所有标签为a,链接符合/view/123.html形式的节点
7 soup.find_all(‘a‘,href=‘/view/123.html‘)
8 soup.find_all(‘a‘,href=re.compile(r‘/view/\d+\.htm‘)) #bs中可以在find方法中的名称和属性上使用正则表达式来匹配对应的内容
9
10 #查找所有标签为div,class为abc,文字为python的节点
11 soup.find_all(‘div‘,class_=‘abc‘,string=‘python‘)
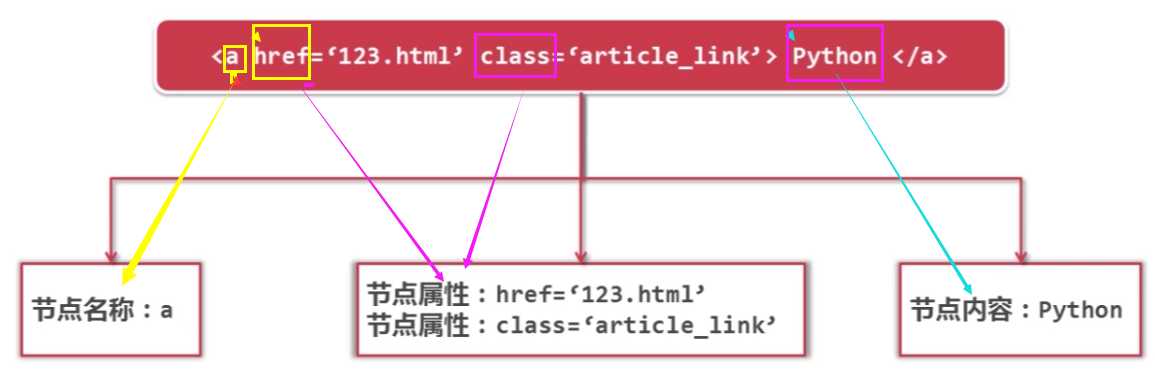
1 #假如得到节点:python
2
3 #获取查找到的a节点的href属性
4 node.name
5
6 #获取查找到的a节点的href属性,以字典的形式访问到a节点所有的属性
7 node[‘href‘]
8
9 #获取查找到的a节点的链接文字
10 node.get_text()
文章标题:爬虫学习——网页解析器Beautiful Soup
文章链接:http://soscw.com/index.php/essay/100011.html