爬虫学习——URL管理器和实现方法
2021-07-02 00:04
阅读:714
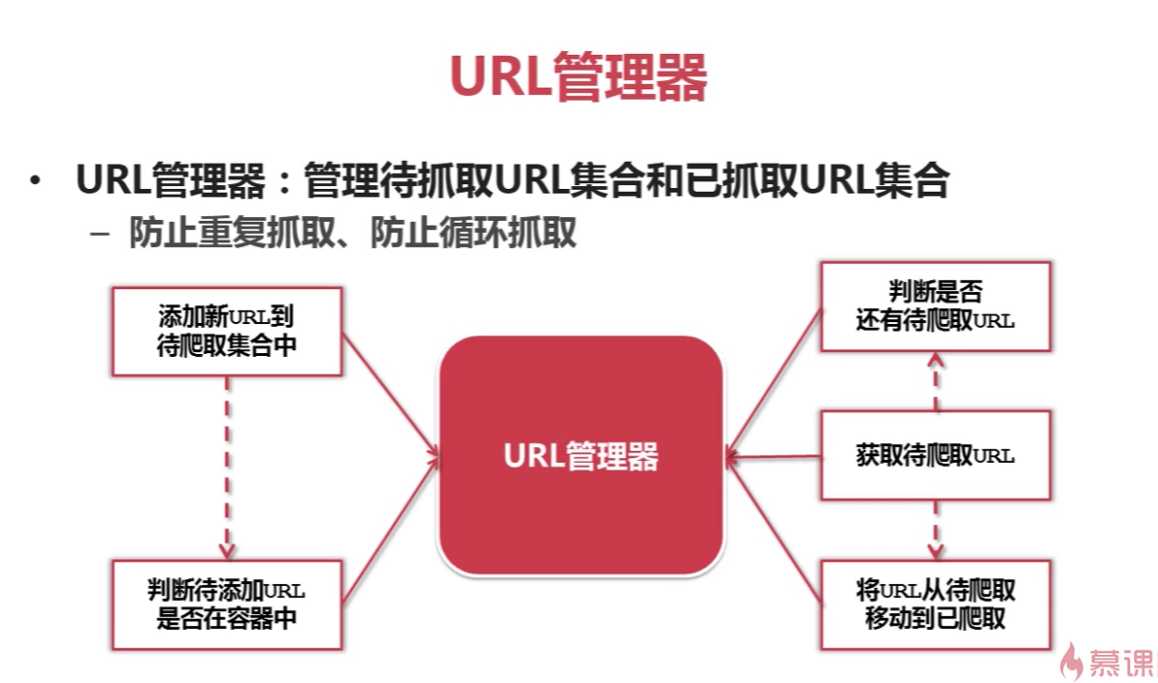
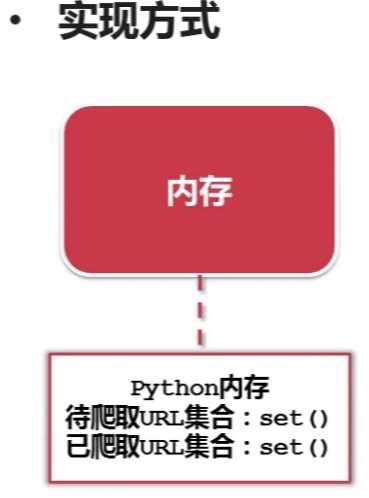
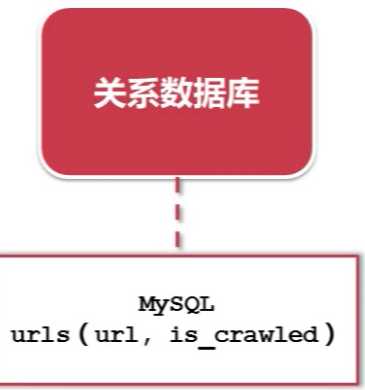
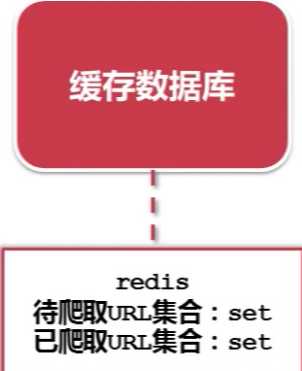
标签:重复 http img mysql image 关系 技术 学习 爬取 url管理器一共有三种实现方法,作为个人,我们应当选择哪种实现方法呢?答案就在下面 爬虫的简单架构 一、URL管理器 实现方式:有三种 1.内存中 python中set()可以直接去除重复的元素 2.关系数据库中 比如:mysql中的urls(url,is_crawled) 建立一个urls表包含两个字段url(待爬取)和is_crawled(已爬取)。 3.缓存数据库 比如:redis 本身就包含set关系型数据结构 缓存数据库具有高性能:大公司首选 个人和小公司可用python内存作为存储, 存储不足,想要永久存储可选用关系型数据库 爬虫学习——URL管理器和实现方法 标签:重复 http img mysql image 关系 技术 学习 爬取 原文地址:http://www.cnblogs.com/ryuuku/p/7131053.html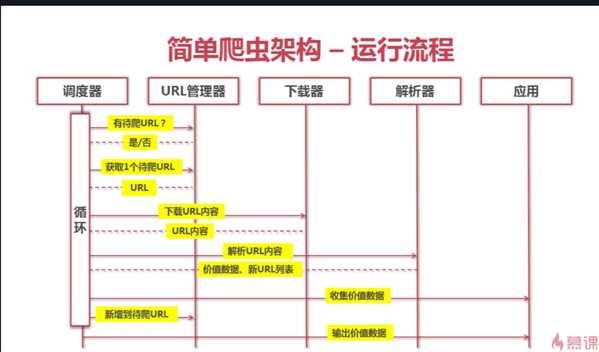
文章来自:搜素材网的编程语言模块,转载请注明文章出处。
文章标题:爬虫学习——URL管理器和实现方法
文章链接:http://soscw.com/index.php/essay/100538.html
文章标题:爬虫学习——URL管理器和实现方法
文章链接:http://soscw.com/index.php/essay/100538.html
评论
亲,登录后才可以留言!