nodejs 爬虫笔记
2021-07-03 12:05
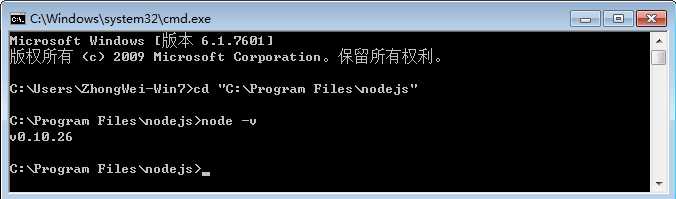
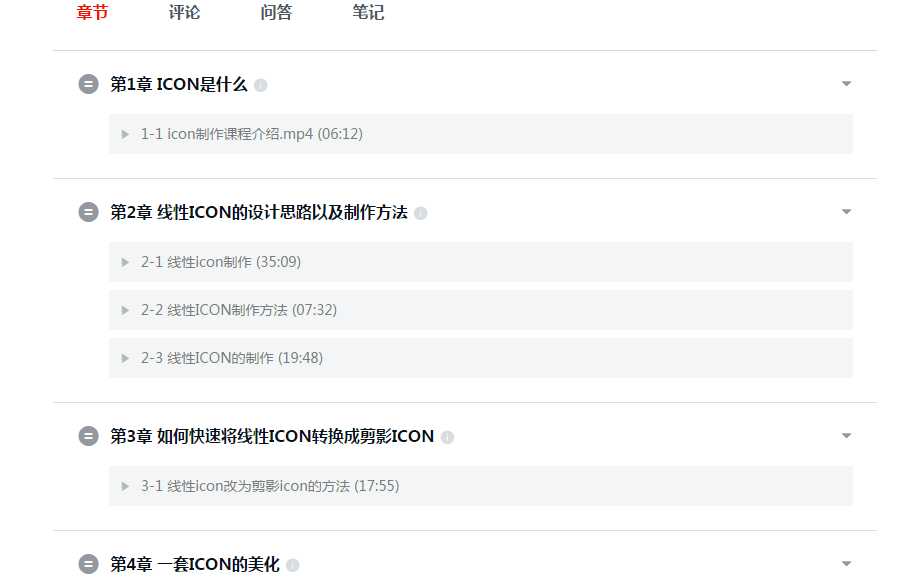
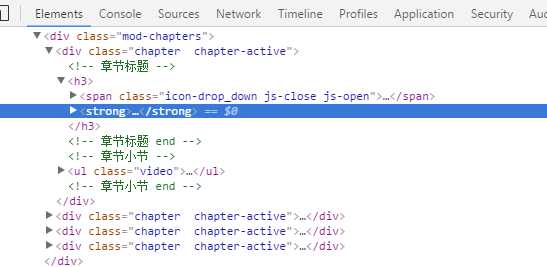
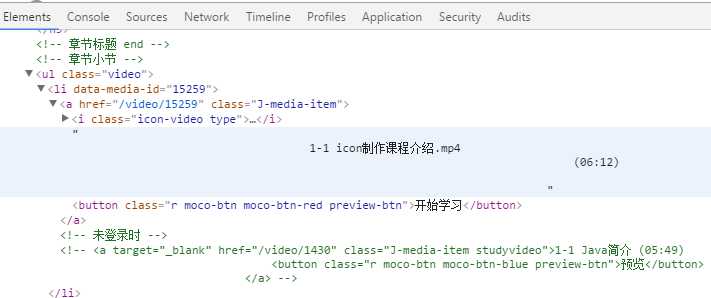
标签:点击 tab 数据表 检查 ges 3.0 span duration cti 目标:爬取慕课网里面一个教程的视频信息,并将其存入mysql数据库。以http://www.imooc.com/learn/857为例。 1.安装nodejs:(操作系统环境:WiN 7 64位) 在Windows环境下安装相对简单(ps:其他版本我也不太清楚,可以问度娘) http://nodejs.org/download/ 链接中下载对应操作系统安装文件(安装最新版本就行) 按照提示,一路下一步直到安装成功后,在默认安装路径下可以看到(C:\Program Files\nodejs),默认路径在安装的时候可以修改。 安装成功后,在“命令提示符中”输入:node -v 查看安装版本,输出版本即安装成功 2.编码工具: WebStorm下载地址: http://www.jetbrains.com/webstorm/,Webstorm用起来很方便,但是我电脑比较卡,我最终还是选择了Sublime,可以在各平台下保持个统一个开发工具,配置方法网上有很多(软件无需注册,使用过程中时不时会弹出需要注册的窗口,取消即可) Sublime下载地址: http://www.sublimetext.com/ Sublime配置nodejs环境可参考http://www.cnblogs.com/zhongweiv/p/nodejs_environment.html request 是一个用来简化 HTTP 请求操作的模块,其功能强大而且使用方法简单,以下 是一个通过 GET 方法来获取某个URL的内容的例子: 如果是其他的请求方法,或者需要指定请求头等信息,可以在第一个参数中传入一个对象来 指定,比如: 本文中仅用到了 request 模块很少的部分,其具体的使用方法可以浏览该模块的主页来获取详细的使用说明:https://npmjs.org/package/request。 cheerio 是一个 jQuery Core 的子集,其实现了 jQuery Core 中浏览器无关的 DOM 操作 API,以下是一个简单的示例: 简单来说,cheerio就是服务器端的jQuery,去掉了jQuery的一些效果类和请求类等等功能后,仅保留核心对dom操作的部分,因此能够对dom进行和jQuery一样方便的操作。它是我们筛选数据的利器——把多余的html标签去掉,只留下我们想要的内容的重要工具。需要注意的是,cheerio 并不支持所有 jQuery 的查询语法,比如 cheerio 模块的详细使用方法可以访问该模块的主要来获取: https://npmjs.org/package/cheerio。 我使用的是mysql连接池,具体的使用方法可以参考https://github.com/felixge/node-mysql mysql 模块内置了连接池机制,以下是一个简单的使用示例: async 是一个使用比较广泛的 JavaScript 异步流程控制模块,除了可以在 Node.js 上运行外,其还可以在浏览器端运行。 async模块提供了约 20 多个实用的函数来 帮助我们理清在使用 Node.js 过程中各种复杂回调。 可以参考:http://blog.csdn.net/zzwwjjdj1/article/details/51857959, 关于 async 模块的详细使用方法可以访问该模块的主页来获取: https://npmjs.org/package/async. 1、初始化项目 在喜欢的目录下创建一个文件夹,我在D盘创建文件夹并命名为crawler;在DOS下cd到该目录,运行npm init 初始化,此时需要填写一些项目信息,你可以根据情况填写,当然也可以一路回车。创建完项目后,会生成一个package.json的文件。该文件包含了项目的基本信息。然后安装第三方包: –save的目的是将项目对该包的依赖写入到package.json文件中。此时,package.json文件如下: 2、分析页面 打开http://www.imooc.com/learn/857,可以发现课程如下: 我习惯使用Google浏览器,打开网页后点击检查,可以查看该网页相关部分的html代码如下: 3、获取视频信息 我们需要从这段HTML中获取视频的名称name,id,url,时长duration以及所属章节title。利用jQuery的方法,可以通过$(‘.video li a‘)来获取所有视频的a标签,然后从中提取name,duration,url和id,所属章节的话要转到a标签的曾祖父。在crawler目录下新建video.js,在sublime-text中编辑程序如下: 配置好node.js环境后(配置参考http://www.cnblogs.com/zhongweiv/p/nodejs_environment.html), 点击ctrl+s进行保存,再点击ctrl+b运行(也可以在DOS下输入node video运行)显示如下: 我们已经得到了视频相关信息,接下来我们将其存入mysql。 4、数据存入mysql 新建数据库muke,然后新建数据表video,在DOS下输入use muke后,创建数据库表: 然后在crawler文件夹下新建save.js,先利用sublime编辑代码如下: 运行后输出如下图,其中content是muke数据库下的另外一个表。 此时说明数据库已经连接成功。接下来继续编辑save.js如下: 修改video.js如下 然后在crawler目录下新建index.js文件,编辑代码如下: 点击运行后会输出 ‘’完成‘’。然后利用可视化工具Navicat 查看video数据表可以看到信息已经存入。 通过训练,对request、cheerio、async、mysql等模块有了初步的了解,也熟悉了下node爬虫的基本过程,但保存数据时,存入数据库还需判断数据是否存在、去重等问题。 欢迎评论,转载请注明地址。 nodejs 爬虫笔记 标签:点击 tab 数据表 检查 ges 3.0 span duration cti 原文地址:http://www.cnblogs.com/xiaxuexiaoab/p/7124956.html一、工具
二、相关模块
1、使用 request 模块来获取网页内容
var request = require(‘request‘);
// 通过 GET 请求来读取 http://cnodejs.org/ 的内容
request(‘http://cnodejs.org/‘, function (error, response, body) {
if (!error && response.statusCode == 200) {
// 输出网页内容
console.log(body);
}
});
var request = require(‘request‘);
request({
url: ‘http://cnodejs.org/‘, // 请求的URL
method: ‘GET‘, // 请求方法
headers: { // 指定请求头
‘Accept-Language‘: ‘zh-CN,zh;q=0.8‘, // 指定 Accept-Language
‘Cookie‘: ‘__utma=4454.11221.455353.21.143;‘ // 指定 Cookie
}
}, function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body) // 输出网页内容
}
});
2、使用 cheerio 模块来提取网页中的数据
var cheerio = require(‘cheerio‘);
// 通过 load 方法把 HTML 代码转换成一个 jQuery 对象
var $ = cheerio.load(‘
Hello world
‘);
// 可以使用与 jQuery 一样的语法来操作
$(‘h2.title‘).text(‘Hello there!‘);
$(‘h2‘).addClass(‘welcome‘);
console.log($.html());
// 将输出 Hello there!
$(‘a:first‘) 会报错 ,只能写成 $(‘a‘).first() ,在使用的时候需要注意。jQuery的相关选择器可以参考http://www.cnblogs.com/xiaxuexiaoab/p/7091527.html3、使用 mysql 模块来将数据储存到数据库
var mysql = require(‘mysql‘);
// 创建数据库连接池
var pool = mysql.createPool({
host: ‘localhost‘, // 数据库地址
user: ‘root‘, // 数据库用户
password: ‘‘, // 对应的密码
database: ‘example‘, // 数据库名称
connectionLimit: 10 // 最大连接数,默认为10
});
// 在使用 SQL 查询前,需要调用 pool.getConnection() 来取得一个连接
pool.getConnection(function(err, connection) {
if (err) throw err;
// connection 即为当前一个可用的数据库连接
});
4、使用 async 模块来简化异步流程控制
三、开始爬虫
npm install request cheerio mysql async -save
{
"name": "crawler",
"version": "1.0.0",
"description": "crawler and mysql",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"async": "^2.5.0",
"cheerio": "^1.0.0-rc.1",
"mysql": "^2.13.0",
"request": "^2.81.0"
}
}
var request = require(‘request‘);
var cheerio = require(‘cheerio‘);
var url = ‘http://www.imooc.com/learn/857‘;
function videocrawler(url,callback){
//获取页面
request(url,function(err,res){
if(err){
callback(err);
}
var $ = cheerio.load(res.body.toString()); //利用cheerio对页面进行解析
var videoList = [];
$(‘.video li a‘).each(function(){
var $title = $(this).parent().parent().parent().text().trim();
var title = $title.split(‘\n‘);
var text = $(this).text().trim();
text = text.split(‘\n‘);
//console.log(text);
var time = text[1].match(/\((\d+\:\d+)\)/);
var item={
title : title[0],
url : ‘http://www.imooc.com‘+$(this).attr(‘href‘),
name : text[0],
duration : time[1]
};
var s = item.url.match(/video\/(\d+)/);
//console.log(s);
if(Array.isArray(s)){
item.id = s[1];
videoList.push(item);
}
});
callback(null,videoList);
});
}
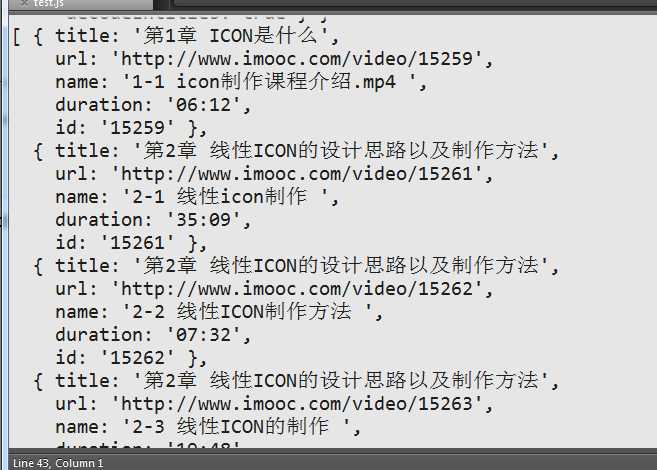
videocrawler(url,function(err,videoList){
if(err){
return console.log(err);
}
console.log(videoList);
});
CREATE TABLE `video` (
`id` int(11) NOT NULL,
`title` varchar(255) NOT NULL,
`url` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
`duration` varchar(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
var mysql = require(‘mysql‘);
var async = require(‘async‘);
var pool = mysql.createPool({
host : ‘localhost‘,
user : ‘root‘,
password : ‘z2457098495924‘,
database : ‘muke‘
});
pool.getConnection(function(err,connection){
if(err){
console.log(err);
}
connection.query(‘show tables‘,function(err,result){
if(err){
return console.log(‘show tables error:‘+err.message);
}
return console.log(result);
});
connection.release();
});

var mysql = require(‘mysql‘);
var async = require(‘async‘);
var pool = mysql.createPool({
host : ‘localhost‘,
user : ‘root‘,
password : ‘z2457098495924‘,
database : ‘muke‘
});
exports.videoSave = function(list,callback){
pool.getConnection(function(err,connection){
if(err){
return callback(err);
}
var insertsql = ‘insert into video(id,title,url,name,duration) values(?,?,?,?,?)‘;
async.eachSeries(list,function(item,next){
connection.query(insertsql,[item.id,item.title,item.url,item.name,item.duration],next);
},callback);
connection.release();
});
};
var request = require(‘request‘);
var cheerio = require(‘cheerio‘);
exports.videocrawler = function(url,callback){
request(url,function(err,res){
if(err){
callback(err);
}
var $ = cheerio.load(res.body.toString());
var videoList = [];
$(‘.video li a‘).each(function(){
var $title = $(this).parent().parent().parent().text().trim();
var title = $title.split(‘\n‘);
var text = $(this).text().trim();
text = text.split(‘\n‘);
//console.log(text);
var time = text[1].match(/\((\d+\:\d+)\)/);
var item={
title : title[0],
url : ‘http://www.imooc.com‘+$(this).attr(‘href‘),
name : text[0],
duration : time[1]
};
var s = item.url.match(/video\/(\d+)/);
//console.log(s);
if(Array.isArray(s)){
item.id = s[1];
videoList.push(item);
}
});
callback(null,videoList);
});
}
var async = require(‘async‘);var video = require(‘./video‘);
var save = require(‘./save‘);
var url = ‘http://www.imooc.com/learn/857‘;
var videolist;
async.series([
//获取视频信息
function(done){
video.videocrawler(url,function(err,list){
videolist = list;
done(err);
});
},
//保存视频信息
function(done){
save.videoSave(videolist,done);
},
],function(err){
if(err){
console.log(err);
}
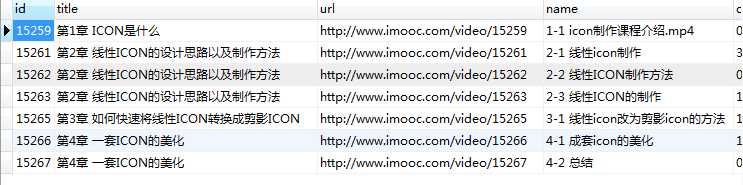
console.log(‘完成‘);
process.exit(0);
})
四、总结
上一篇:(转)基于MVC4+EasyUI的Web开发框架形成之旅--总体介绍
下一篇:真机调试报错error ==Error Domain=NSURLErrorDomain Code=-1009 "似乎已断开与互联网的连接。"