Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
2021-07-04 20:10
标签:1.7 爬取 无限 循环 ext 西默 set page 调用 本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 标签:1.7 爬取 无限 循环 ext 西默 set page 调用 原文地址:https://www.cnblogs.com/xpwi/p/9601050.htmlPython爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
Settings 中配置 USER_AGENTS
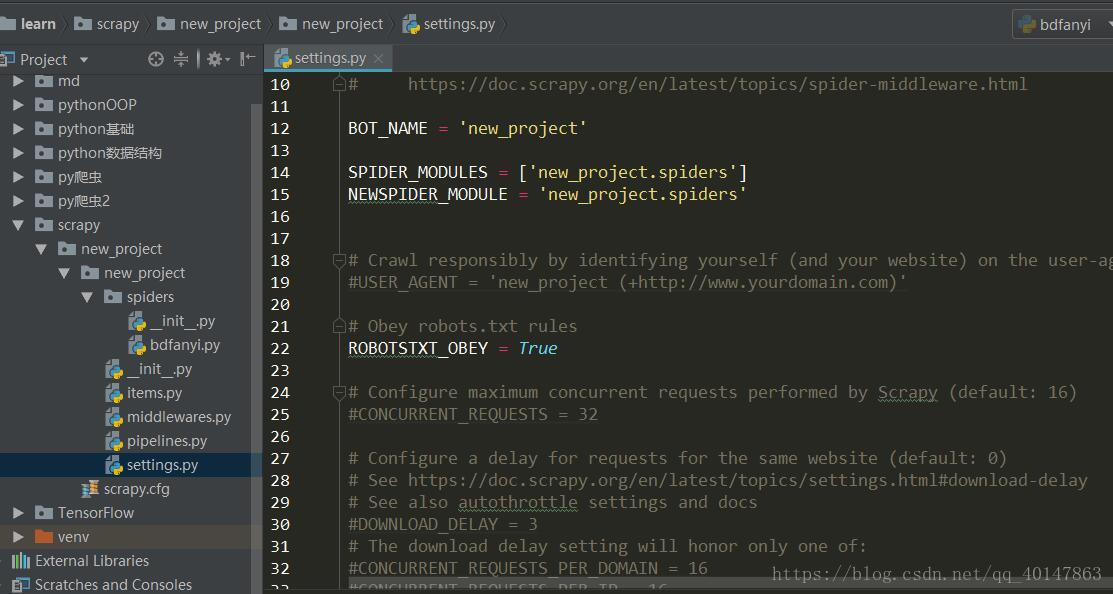

USER_AGENTS = [
"Mozilla/5.0 (compatible; MISE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.5.727; Media Center PC 6.0)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 ",
"Opera/8.0 (Windows NT 5.1; U; en) ",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50 ",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400) ",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
]Settings 中配置 PROXIES
# IP 有效期一般20天,请自行到上述网站获取最新 IP
PROXIES = [
{‘ip_port‘: ‘177.136.120.174:80‘, ‘user_passwd‘: ‘user1:pass1‘},
{‘ip_port‘: ‘218.60.8.99:3129‘, ‘user_passwd‘: ‘user2:pass2‘},
{‘ip_port‘: ‘206.189.204.62:8080‘, ‘user_passwd‘: ‘user3:pass3‘},
{‘ip_port‘: ‘125.62.26.197:3128‘, ‘user_passwd‘: ‘user4:pass4‘}
]
关于去重
myspider(scrapy.Spider):
def parse (...):
...
yield scrapy.Request(url = url, callback = self.parse, dont_filter = False)
class MyMiddleWare(object):
def process_request(...):
driver = webdriver.Chrome()
html = driver.page_source
driver.quit()
return HtmlResponse(url = request.url, encoding = ‘utf-8‘, body = html ,request = requeset
文章标题:Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
文章链接:http://soscw.com/index.php/essay/101855.html