Python爬取QQ空间好友说说并生成词云(超详细)
2021-07-04 20:10
标签:google cimage content with hit nis 模式 交流 ack 先看效果图: 1.确认访问的URL 1.确认访问的URL 2.我们在请求的时候会遇到模拟登录,也就是要通过Selenium+浏览器登录你的QQ号后才能访问你好友的QQ空间 需要强调是 driver.switch_to_default_content() ,表示跳出当前的frame,这步很关键,因为你登录后还要切刀另一个frame。不写的话会出现下面的错误: 3.第三部分我分几个点来说: (2)切换到说说的frame,这个大家都会找吧 (3)下拉滚动条 (4)爬取说说数据,这就简单了吧?我用的xpath获取的说说的title,感兴趣的朋友可以把时间等数据一起获取 (5).翻页 (6).txt数据写入,不用多说,爬取到title了直接写入 4.生成词云,这只是普通的模式,想具体了解可以看我以前文章或者Google 由于时间问题,此篇文章只支持输入一个好友的QQ号,你要是想爬取你的所有的QQ好友的说说,可以现在QQ邮箱获取你所有好友的QQ号,然后生成一个数组,依次获取就可以了。 Python爬取QQ空间好友说说并生成词云(超详细) 标签:google cimage content with hit nis 模式 交流 ack 原文地址:https://www.cnblogs.com/Python6359/p/9601070.html
前言

思路
2.模拟登录你的QQ号
3.判断好友空间是否加了权限,切换到说说的frame,爬取当前页面数据,下拉滚动条,翻页继续获取 爬取的内容写入本地TXT文件中
4.爬取到最后一页,读取TXT文件从而生成词云具体分析
这就很简单了,我们通过观察发现,QQ空间好友的URL:
https://user.qzone.qq.com/{好友QQ号}/311
下面是模拟登录的代码: 1 file = ‘C:/Users/Administrator/Desktop/{}.txt‘.format(qq)
2 driver = webdriver.Firefox()
3 driver.maximize_window() #窗口最大化
4
5 driver.get(‘https://user.qzone.qq.com/{}/311‘.format(qq)) #URL
6 driver.implicitly_wait(10) # 隐示等待,为了等待充分加载好网址
7 driver.find_element_by_id(‘login_div‘)
8 driver.switch_to_frame(‘login_frame‘) #切到输入账号密码的frame
9 driver.find_element_by_id(‘switcher_plogin‘).click()##点击‘账号密码登录’
10 driver.find_element_by_id(‘u‘).clear() ##清空账号栏
11 driver.find_element_by_id(‘u‘).send_keys(‘你的QQ账号‘)#输入账号
12 driver.find_element_by_id(‘p‘).clear()#清空密码栏
13 driver.find_element_by_id(‘p‘).send_keys(‘你的QQ密码‘)#输入密码
14 driver.find_element_by_id(‘login_button‘).click()#点击‘登录’
15 driver.switch_to_default_content() #跳出当前的frame,这步很关键,不写会报错的,因为你登录后还要切刀另一个frame
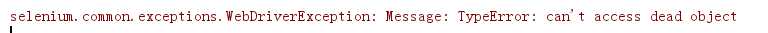
(1).判断空间是否加了权限1 try:
2 driver.find_element_by_id(‘QM_OwnerInfo_Icon‘)#判断是否QQ空间加了权限
3 b = True
4 except:
5 b = False
下拉滚动条是为了点击‘下一页’,下拉到可见视图。下拉滚动条要注意一点:
一定要对应它的frame,不要在爬取说说的frame下拉。1 #分4此下拉,确保能下拉到底部
2 for j in range(1, 5):
3 driver.execute_script("window.scrollBy(0,5000)")
4 time.sleep(2)
1 selector = etree.HTML(driver.page_source)
2 title = selector.xpath(‘//li/div/div/pre/text()‘)
直接点击‘下一页’即可。1 driver.find_element_by_link_text(u‘下一页‘).click()
1 for i in title:
2 if not os.path.exists(file):
3 print(‘创建TXT成功‘)
4
5 with open(file, ‘a+‘) as f:
6 f.write(i + ‘\n\n‘)
7 f.close()
1 def get_wordcloud(file):
2
3
4 f = open(file, ‘r‘, encoding=‘gbk‘).read()
5
6 # 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云
7 cut_text = " ".join(jieba.cut(f))
8
9 wordcloud = WordCloud(
10 # 设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的
11 font_path="C:/Windows/Fonts/simfang.ttf",
12 # 设置了背景,宽高
13 background_color="white", width=2000, height=1380).generate(cut_text)
14
15 plt.imshow(wordcloud, interpolation="bilinear")
16 plt.axis("off")
17 plt.show()
18#Python学习交流群:548377875
文章标题:Python爬取QQ空间好友说说并生成词云(超详细)
文章链接:http://soscw.com/index.php/essay/101858.html