二分查找算法(JAVA)
2021-07-05 14:06
标签:while main 大小 sys div end nbsp 存储 关键字 1.二分查找又称折半查找,它是一种效率较高的查找方法。 2.二分查找要求:(1)必须采用顺序存储结构 (2).必须按关键字大小有序排列 3.原理:将数组分为三部分,依次是中值(所谓的中值就是数组中间位置的那个值)前,中值,中值后;将要查找的值和数组的中值进行比较,若小于中值则在中值前 面找,若大于中值则在中值后面找,等于中值时直接返回。然后依次是一个递归过程,将前半部分或者后半部分继续分解为三部分。 其查找的基本思路:首先将给定值K,与表中中间位置元素的关键字比较,若相等,返回该元素的存储位置;若不等,这所需查找的元素只能在中间数据以外的前半部分或后半部分中。然后在缩小的范围中继续进行同样的查找。如此反复直到找到为止。 4.实现:二分查找的实现用递归和循环两种方式 5.代码: 因为二分查找需要方便地定位查找区域,所以适合二分查找的存储结构必须具有随机存储的特性。 因此,该查找方法仅适合于线性表的顺序存储结构,不适合链式存储结构,且要求元素按关键字有序排列。 判定树(及二叉树): 二分查找的过程可以用下图表示,称为判定树,(二叉树)。树中每个圆形节点表示一个纪录,节点中的值表示为该记录的关键字值:树中最下面叶节点都是方形的,它表示查找不成功的情况。从判定树中可以看出,查找成功时查找的查找长度为从根节点到目的节点的路径上的节点数,而查找不成功时的查找长度为从根节点到对应失败节点的父节点的父节点路径上的节点数;每个节点值均大于其左子节点值,且均小于右子节点值。若有序序列有n个元素,这对应的判定树有n个圆形的非叶节点和n+1个方形的叶节点。 上图中,n个圆形节点(代表有序序列有n个元素)构成的树的深度与n个节点完全二叉树的深度(高度)相等,均为⌊log2n⌋+1或⌈log2(n+1)⌉ 二分查找的时间复杂度为O(log2N),比顺序查找的效率高。 由上述分析可知,用二分查找到给定值或查找失败的比较次数最多不会超过树的高度。查找成功与不成功,最坏的情况下,都需要比较⌊log2n⌋+1次。 注意事项: 折半查找是一棵二叉排序树,每个根结点的值都大于左子树的所有结点的值,小于右子树所有结点的值。 具体的可百度下 判断树 二分查找算法(JAVA) 标签:while main 大小 sys div end nbsp 存储 关键字 原文地址:https://www.cnblogs.com/hanxue53/p/9597139.html 1 package other;
2
3 public class BinarySearch {
4 /*
5 * 循环实现二分查找算法arr 已排好序的数组x 需要查找的数-1 无法查到数据
6 */
7 public static int binarySearch(int[] arr, int x) {
8 int low = 0;
9 int high = arr.length-1;
10 while(low high) {
11 int middle = (low + high)/2;
12 if(x == arr[middle]) {
13 return middle;
14 }else if(x arr[middle]) {
15 high = middle - 1;
16 }else {
17 low = middle + 1;
18 }
19 }
20 return -1;
21 }
22 //递归实现二分查找
23 public static int binarySearch(int[] dataset,int data,int beginIndex,int endIndex){
24 int midIndex = (beginIndex+endIndex)/2;
25 if(data
System.out.println("循环查找:" + binarySearch(arr, 87)); //循环查找:3--这个3代表的是数组的索引值
40 System.out.println("递归查找"+binarySearch(arr,87,3,arr.length-1)); //递归查找3 --这个3代表的是数组的索引值
41 }
42 } 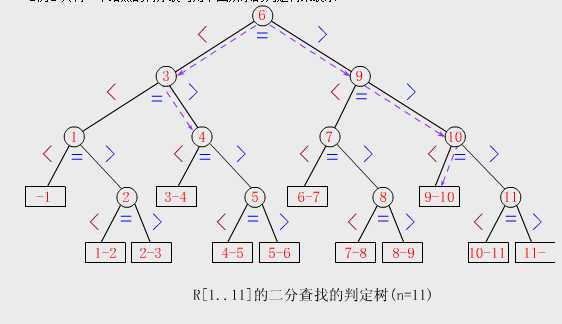
二分查找的优点和缺点
虽然二分查找的效率高,但是要将表按关键字排序。而排序本身是一种很费时的运算。既使采用高效率的排序方法也要花费O(nlgn)的时间。
二分查找只适用顺序存储结构。为保持表的有序性,在顺序结构里插入和删除都必须移动大量的结点。因此,二分查找特别适用于那种一经建立就很少改动、而又经常需要查找的线性表。
对那些查找少而又经常需要改动的线性表,可采用链表作存储结构,进行顺序查找。链表上无法实现二分查找。