Python 利用 BeautifulSoup 爬取网站获取新闻流
2021-07-09 11:21
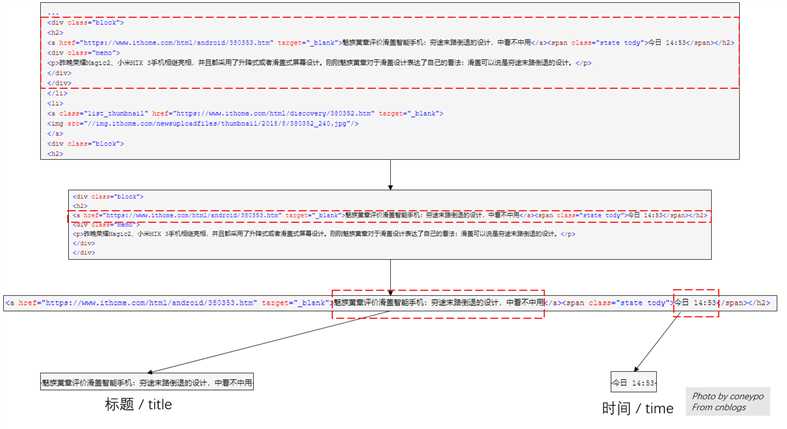
标签:发送请求 discover 充电 俄罗斯 骁龙 位置 需要 log enter 0. 引言 介绍下 Python 用 Beautiful Soup 周期性爬取 xxx 网站获取新闻流; 图 1 项目介绍 1. 开发环境 Python: 3.6.3 BeautifulSoup: 4.2.0 , 是一个可以从HTML或XML文件中提取数据的Python库* ( BeautifulSoup 的中文官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ ) 2. 代码介绍 实现主要分为三个模块: 1. 计时 / second cnt 因为是周期性爬取,所以需要计时器来控制; 2. 设置代理 / set proxy 为了应对网站的反爬虫机制,需要切换代理; 3. 爬虫 / web spider 利用 requests 请求网站内容,然后 beautifulsoup 提取出所需信息; 利用 requests.get() 向服务器发送请求 >>> 拿到 html 内容 >>> 交由 beautifulsoup 用来解析提取数据; 先看一个 requests 和 beautifulsoup 拿数据的简单例子: requests 发送请求给网站,然后 get 到返回的 html,然后再转换为 beautifulsoup 的对象; ( headers 和 proxies 是可选项 / optional ) 本文以爬取 https://www.ithome.com/blog/ 为例,把页面上的新闻爬取下来,过滤掉多余信息,拿到 新闻时间 & 新闻标题 ; 图 2 网站界面 拿到网站的 html 代码之后,如何剥离出自己想要的数据,参考图 3 的流程: 图 3 从 html 中 剥离数据的流程 首先看看 bsObj = BeautifulSoup(resp.content, "lxml") 拿到的 目标网站 ( https://www.ithome.com/blog/ ) 的 HTML 代码: 需要一层层剥出数据,首先定位到 接下来就是要提取出 新闻标题 title 和 新闻时间 time; 对于单个的 block: 提取新闻时间: 然后 得到 time 内容: 然后 得到 title 内容: 这样就可以拿到了 新闻标题 titile 和 新闻时间 time了; 3. 代码实现 1. 计时器 这里是一个秒数计数功能模块,利用 datetime 这个库,获取当前时间的秒位,和开始时间的秒位进行比对,如果发生变化,sec_cnt 就 +=1; sec_cnt 输出 1,2,3,4,5,6...是记录的秒数,可以由此控制抓包时间; second_cnt.py: 2. get_proxy / 获取代理 这个网站可以提供一些国内的代理地址: http://www.xicidaili.com/nn/ ; 因为现在网站可能会有反爬虫机制,如果同一个 IP 如果短时间内大量访问该站点,就会被拦截; 所以我们需要设置代理,拿到的 proxy 地址传给 requests.get 的 proxies 参数: get_proxy.py : 3. get_news_from_xxx / 爬虫 由计时器的 sec_cnt 控制爬虫的周期,每次先去代理网站拿代理,然后交给 requests 去拿数据,拿到 HTML 之后交给 beautiful 对象,然后过滤出新闻流: get_news_from_xxx.py 完整的代码: 最终的输出 log: 你就可以每隔 10s 刷新下该网站上面的新闻流; 刷新周期在 line 87: # 请尊重他人劳动成果,转载或者使用源码请注明出处:http://www.cnblogs.com/AdaminXie # 请不要利用爬虫从事恶意攻击或者违法活动 Python 利用 BeautifulSoup 爬取网站获取新闻流 标签:发送请求 discover 充电 俄罗斯 骁龙 位置 需要 log enter 原文地址:https://www.cnblogs.com/AdaminXie/p/9565488.html
1 from bs4 import BeautifulSoup
2 import requests
3 html = "https://www.xxx.com"
4 headers = {
5 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36‘
6 }
7 proxies = "114.231.xx.xx:xxxx"
8
9 resp = requests.get(html, headers=headers, proxies=proxies)
10 resp.encoding = ‘utf-8‘
11
12 bsObj = BeautifulSoup(resp.content, "lxml")
...
div class="block">
h2>
a href="https://www.ithome.com/html/android/380353.htm" target="_blank">魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用a>span class="state tody">今日 14:53span>h2>
div class="memo">
p>昨晚荣耀Magic2、小米MIX 3手机相继亮相,并且都采用了升降式或者滑盖式屏幕设计。刚刚魅族黄章对于滑盖设计表达了自己的看法:滑盖可以说是穷途末路倒退的设计。p>
div>
div>
li>
li>
a class="list_thumbnail" href="https://www.ithome.com/html/discovery/380352.htm" target="_blank">
img src="//img.ithome.com/newsuploadfiles/thumbnail/2018/8/380352_240.jpg"/>
a>
div class="block">
h2>
a href="https://www.ithome.com/html/discovery/380352.htm" target="_blank">俄罗斯计划“世界级”研究中心,拟克隆猛犸象a>span class="state tody">今日 14:48span>h2>
div class="memo">
p>俄罗斯科学家计划用保存的冰河时代遗骸的DNA,在一个耗资450万英镑的新侏罗纪公园中心克隆猛犸象p>
div>
div>
li>
li>
a class="list_thumbnail" href="https://lapin.ithome.com/html/digi/380351.htm" target="_blank">
img src="//img.ithome.com/newsuploadfiles/thumbnail/2018/8/380351_240.jpg"/>
a>
div class="block">
h2>
...>>> block = bsObj.find_all("div", {"class": "block"})
div class="block">
h2>
a href="https://www.ithome.com/html/android/380353.htm" target="_blank"> 魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用a>
span class="state tody">今日 14:53span>
h2>
div class="memo">
p>昨晚荣耀Magic2、小米MIX 3手机相继亮相,并且都采用了升降式或者滑盖式屏幕设计。刚刚魅族黄章对于滑盖设计表达了自己的看法:滑盖可以说是穷途末路倒退的设计。p>
div>>>> block.find(‘span‘, {‘class‘: "state tody"})
span class="state tody">今日 14:53span>
>> block.find(‘span‘, {‘class‘: "state tody"}).get_text()
今日 14:53
提取新闻标题:>>> block[i].find(‘a‘, {‘target‘: "_blank"})
a href="https://www.ithome.com/html/android/380353.htm" target="_blank">魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用a>
>> block.find(‘a‘, {‘target‘: "_blank"}).get_text()
魅族黄章评价滑盖智能手机:穷途末路倒退的设计,中看不中用
>>> time = datetime.datetime.now() # 获取当前的时间,比如:2018-08-31 14:32:54.440831
>>> time.second() # 获取时间的秒位 1 # Author: coneypo
2 # Created: 08.31
3
4 import datetime
5
6 # 开始时间
7 start_time = datetime.datetime.now()
8 tmp = 0
9 # 记录的秒数
10 sec_cnt = 0
11
12 while 1:
13 current_time = datetime.datetime.now()
14
15 # second 是以60为周期
16 # 将开始时间的秒 second / 当前时间的秒 second 进行对比;
17 # 如果发生变化则 sec_cnt+=1;
18 if current_time.second >= start_time.second:
19 if tmp != current_time.second - start_time.second:
20 # print("
>>> requests.get(html, headers=headers, proxies=proxies)
1 # Author: coneypo
2 # Created: 08.31
3 # set proxy
4
5 from bs4 import BeautifulSoup
6 import requests
7 import random
8
9
10 def get_proxy():
11 headers = {
12 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36‘
13 }
14 proxy_url = ‘http://www.xicidaili.com/nn/‘
15 resp = requests.get(proxy_url, headers=headers)
16 soup = BeautifulSoup(resp.text, ‘lxml‘)
17 ips = soup.find_all(‘tr‘)
18 proxy_list = []
19
20 for i in range(1, len(ips)):
21 ip_info = ips[i]
22 tds = ip_info.find_all(‘td‘)
23 proxy_list.append(tds[1].text + ‘:‘ + tds[2].text)
24
25 proxy = proxy_list[random.randint(0, len(proxy_list))]
26
27 print(proxy)
28 return proxy
1 # Author: coneypo
2 # Created: 08.31
3 # web spider for xxx.com
4
5 from bs4 import BeautifulSoup
6 import requests
7 import random
8 import datetime
9
10 headers = {
11 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36‘
12 }
13
14
15 # 设置代理
16 def get_proxy():
17 proxy_url = ‘http://www.xicidaili.com/nn/‘
18 resp = requests.get(proxy_url, headers=headers)
19 soup = BeautifulSoup(resp.text, ‘lxml‘)
20 ips = soup.find_all(‘tr‘)
21 proxy_list = []
22
23 for i in range(1, len(ips)):
24 ip_info = ips[i]
25 tds = ip_info.find_all(‘td‘)
26 proxy_list.append(tds[1].text + ‘:‘ + tds[2].text)
27
28 proxy = proxy_list[random.randint(0, len(proxy_list))]
29
30 print("Proxy:", proxy)
31 return proxy
32
33
34 # 爬取网站
35 def get_news():
36 html = "https://www.ithome.com/blog/"
37 resp = requests.get(html, headers=headers, proxies=get_proxy())
38 resp.encoding = ‘utf-8‘
39
40 # 网页内容
41 bsObj = BeautifulSoup(resp.content, "lxml")
42 #print(bsObj)
43
44 # 分析
45 block = bsObj.find_all("div", {"class": "block"})
46 #print(block)
47
48 current_titles = []
49 current_times = []
50
51 # analysis every block
52 for i in range(len(block)):
53 # get Time
54 time_classes = ["state tody", "state other"]
55 for time_class in time_classes:
56 tmp = block[i].find_all(‘span‘, {‘class‘: time_class})
57 if tmp:
58 current_time = (block[i].find(‘span‘, {‘class‘: time_class})).get_text()
59 current_times.append(current_time)
60
61 # get Title
62 if block[i].find_all(‘a‘, {‘target‘: "_blank"}):
63 current_title = (block[i].find(‘a‘, {‘target‘: "_blank"})).get_text()
64 current_titles.append(current_title)
65
66 for i in range(len(current_times)):
67 print(current_times[i], current_titles[i])
68 return current_times, current_titles
69
70 get_news()
71
72 # 计时
73 start_time = datetime.datetime.now()
74 tmp = 0
75 sec_cnt = 0
76
77 while 1:
78 current_time = datetime.datetime.now()
79
80 # second 是以60为周期
81 # 将开始时间的秒second / 当前时间的秒second 进行对比
82 if current_time.second >= start_time.second:
83 if tmp != current_time.second - start_time.second:
84 # print("
Time_cnt: 1
Time_cnt: 2
Time_cnt: 3
Time_cnt: 4
Time_cnt: 5
Time_cnt: 6
Time_cnt: 7
Time_cnt: 8
Time_cnt: 9
Time_cnt: 10
Proxies: {‘http‘: ‘http://106.110.198.18:25295‘}
今日 14:02 《漫威蜘蛛侠》否认画面缩水:只是改变了太阳位置
今日 13:52 巴菲特:天天发Twitter对马斯克没好处
今日 13:48 网游总量调控:大厂的一时之痛 VS 小厂的灭顶之灾
今日 13:38 1.2m至2m均价,浩岚旗舰店磨毛床品四件套59元
今日 13:37 索尼或于9月14日发布新款A7SIII全幅微单相机
今日 13:35 谷歌AI助理Google Assistant大升级:同时双语识别
今日 13:12 小米工程师:年前见到了小米MIX 3工程机,产量充足
今日 12:56 小米无线充电器(通用快充版)发布:10W快充,69元
今日 12:53 《古墓丽影:暗影》要登WeGame?腾讯发布问卷调查
今日 12:37 疑似湖畔大学学员回应“心疼柳青”:我们不教语文和逻辑
今日 12:27 拼多多首份财报:营收27亿元翻25倍,亏损翻65倍
08月29日 哆啦A梦正版授权,网易云音乐苹果iPhone 6/7/8/X系列手机壳19元
今日 12:26 B站“血小板吧反串黑”公告:永封相关账号,诉诸法律
今日 12:22 手机淘宝迎重大更新:“猜你喜欢”跃至首页二屏
今日 12:19 “初音未来”主题机械键鼠公布,葱娘键盘约860元
今日 12:13 《生化危机2:重制版》PS4 Pro版演示:场景刻画细节精美
今日 12:06 遭特朗普炮轰,谷歌回应称指责“不属实”
今日 12:03 英特尔为Windows 10设备推出新驱动,修复一系列重大问题
今日 11:51 双星旗舰店网面运动鞋69→39元、啄木鸟弹力牛仔裤109→59元
今日 11:42 亚运会《英雄联盟》中韩决赛回放:并未遭下架,暂无官方直播
今日 11:23 工信部:7月全国共查处“伪基站”违法犯罪案件21起
今日 11:19 《堡垒之夜》官方澄清:虚幻4神秘新平台代号并非索尼PS5!
今日 11:12 R星Steam周末特惠:《侠盗猎车》全系列低至3折!
今日 11:03 滴滴之过
今日 11:00 苹果秋季新品发布会信息汇总:中国特供双卡iPhone XS,iOS 12拯救老机型
今日 10:55 苹果iOS 12最新公测版遇Bug,解锁或下拉菜单提醒升级
今日 10:50 营养暴下饭,仲景旗舰店招牌原味香菇酱10袋480g19.9元
今日 10:40 荣耀Magic2突现,华为要拿麒麟980抢苹果高通风头
今日 10:40 华为做电视,背后的物联网战略才是重点?
今日 10:31 微软京东超级新品日:今日购Surface Go可享6期免最高补贴500元
今日 10:29 微信朋友圈八月十大谣言:使用@符号会被人工监控
今日 10:26 HB商店喜加一:特别好评游戏《战锤星际战士》免费领
今日 10:16 “贵”族8848的没落之路
今日 10:11 飞船裂缝导致国际空间站“漏气”,NASA:不威胁人员安全
今日 10:08 苹果要求重审专利侵权案遭美法官否决:赔偿5亿美元
今日 9:58 “我是开滴滴顺风车的斗鱼主播”
今日 9:57 叫卖华住开房信息,暗网为何如此嚣张?
今日 9:55 可双肩/斜挎/手提,卡拉羊拉杆插件防盗三用包39元
今日 9:47 《战地5》跳票后EA股价下跌8%,Origin高级会员可提前11天进入游戏
今日 9:46 雷军评价小米MIX 3:新一代全面屏,滑盖形式的
今日 9:44 联想Yoga Book C930双屏笔电发布:电子墨水屏取代实体键盘
今日 9:38 1798元起,锤子坚果Pro2S手机10点再次开启抢购
今日 9:35 武汉:网约车须加装卫星定位和一键报警
今日 9:29 滑盖新机曝光网友不敢相信直呼小米Note4,小米有品:MIX 3真机在此
08月26日 宽松休闲,凡客诚品旗舰店男士纯棉日式牛津纺衬衫64元
今日 9:25 消息称三星将向OPPO和小米提供可折叠手机屏幕
今日 9:15 这些价值上亿美元的网站,背后居然都只有一个程序员
今日 9:08 荣耀、小米:滑盖不解决一切问题
今日 9:07 10点开抢,小米8透明探索版今日再次发售
今日 9:04 联想发布全球首款骁龙850笔记本Yoga C630:续航25小时
Time_cnt: 11
Time_cnt: 12
Time_cnt: 13
Time_cnt: 14
Time_cnt: 15
Time_cnt: 16
Time_cnt: 17
Time_cnt: 18
Time_cnt: 19
Time_cnt: 20
Proxies: {‘http‘: ‘http://118.190.95.43:9001‘}
今日 14:02 《漫威蜘蛛侠》否认画面缩水:只是改变了太阳位置
今日 13:52 巴菲特:天天发Twitter对马斯克没好处
今日 13:48 网游总量调控:大厂的一时之痛 VS 小厂的灭顶之灾
今日 13:38 1.2m至2m均价,浩岚旗舰店磨毛床品四件套59元
今日 13:37 索尼或于9月14日发布新款A7SIII全幅微单相机
今日 13:35 谷歌AI助理Google Assistant大升级:同时双语识别
今日 13:12 小米工程师:年前见到了小米MIX 3工程机,产量充足
今日 12:56 小米无线充电器(通用快充版)发布:10W快充,69元
今日 12:53 《古墓丽影:暗影》要登WeGame?腾讯发布问卷调查
今日 12:37 疑似湖畔大学学员回应“心疼柳青”:我们不教语文和逻辑
今日 12:27 拼多多首份财报:营收27亿元翻25倍,亏损翻65倍
08月29日 哆啦A梦正版授权,网易云音乐苹果iPhone 6/7/8/X系列手机壳19元
今日 12:26 B站“血小板吧反串黑”公告:永封相关账号,诉诸法律
今日 12:22 手机淘宝迎重大更新:“猜你喜欢”跃至首页二屏
今日 12:19 “初音未来”主题机械键鼠公布,葱娘键盘约860元
今日 12:13 《生化危机2:重制版》PS4 Pro版演示:场景刻画细节精美
今日 12:06 遭特朗普炮轰,谷歌回应称指责“不属实”
今日 12:03 英特尔为Windows 10设备推出新驱动,修复一系列重大问题
今日 11:51 双星旗舰店网面运动鞋69→39元、啄木鸟弹力牛仔裤109→59元
今日 11:42 亚运会《英雄联盟》中韩决赛回放:并未遭下架,暂无官方直播
今日 11:23 工信部:7月全国共查处“伪基站”违法犯罪案件21起
今日 11:19 《堡垒之夜》官方澄清:虚幻4神秘新平台代号并非索尼PS5!
今日 11:12 R星Steam周末特惠:《侠盗猎车》全系列低至3折!
今日 11:03 滴滴之过
今日 11:00 苹果秋季新品发布会信息汇总:中国特供双卡iPhone XS,iOS 12拯救老机型
今日 10:55 苹果iOS 12最新公测版遇Bug,解锁或下拉菜单提醒升级
今日 10:50 营养暴下饭,仲景旗舰店招牌原味香菇酱10袋480g19.9元
今日 10:40 荣耀Magic2突现,华为要拿麒麟980抢苹果高通风头
今日 10:40 华为做电视,背后的物联网战略才是重点?
今日 10:31 微软京东超级新品日:今日购Surface Go可享6期免最高补贴500元
今日 10:29 微信朋友圈八月十大谣言:使用@符号会被人工监控
今日 10:26 HB商店喜加一:特别好评游戏《战锤星际战士》免费领
今日 10:16 “贵”族8848的没落之路
今日 10:11 飞船裂缝导致国际空间站“漏气”,NASA:不威胁人员安全
今日 10:08 苹果要求重审专利侵权案遭美法官否决:赔偿5亿美元
今日 9:58 “我是开滴滴顺风车的斗鱼主播”
今日 9:57 叫卖华住开房信息,暗网为何如此嚣张?
今日 9:55 可双肩/斜挎/手提,卡拉羊拉杆插件防盗三用包39元
今日 9:47 《战地5》跳票后EA股价下跌8%,Origin高级会员可提前11天进入游戏
今日 9:46 雷军评价小米MIX 3:新一代全面屏,滑盖形式的
今日 9:44 联想Yoga Book C930双屏笔电发布:电子墨水屏取代实体键盘
今日 9:38 1798元起,锤子坚果Pro2S手机10点再次开启抢购
今日 9:35 武汉:网约车须加装卫星定位和一键报警
今日 9:29 滑盖新机曝光网友不敢相信直呼小米Note4,小米有品:MIX 3真机在此
08月26日 宽松休闲,凡客诚品旗舰店男士纯棉日式牛津纺衬衫64元
今日 9:25 消息称三星将向OPPO和小米提供可折叠手机屏幕
今日 9:15 这些价值上亿美元的网站,背后居然都只有一个程序员
今日 9:08 荣耀、小米:滑盖不解决一切问题
今日 9:07 10点开抢,小米8透明探索版今日再次发售
今日 9:04 联想发布全球首款骁龙850笔记本Yoga C630:续航25小时
>>> if sec_cnt % 10 == 0:
下一篇:Python基础语法(二)
文章标题:Python 利用 BeautifulSoup 爬取网站获取新闻流
文章链接:http://soscw.com/index.php/essay/102759.html