Python读取文件,使用split进行分割时,出现\ufeff
2021-07-10 12:04
标签:list 文档 unicode template 参考 targe 解决办法 连续 函数 1.问题 使用python3.6对文件读取时,按照正常套路处理,文件内容类似以下: 啊啊啊 || AAA 不不不 || BBB 当使用utf-8读取文档并且使用split函数分割时,发现第一行字符分割后,莫名多了一个\ufeff。 因为这个原因,导致后续使用 == 或者 x in list 操作时,涉及到第一行的数据时,出错。 Debug第一行见下图(第二行以后是没问题的) 2.原因 参考1: The Unicode character U+FEFF is the byte order mark, or BOM, and is used to tell the difference between big- and little-endian UTF-16 encoding 参考2 \ufeff是一个特殊的标识,表明编码方式, 字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序,在几乎所有的机器上,多字节对象都被存储为连续的字节序列,根据信息在连续内存中的存储顺序,字节序被分为大端序(Big Endian) 与 小端序(Little Endian)两类。( 然后就牵涉出两大CPU派系:一派如PowerPC 970等处理器采用 Big Endian方式存储数据,另一派如x86系列等处理器采用Little Endian方式存储数据)。其中大端序和小端序解释如下: 对其作用及更多内容见参考 3.解决方法 一种方法: 通过utf-8对字符串进行encode成byte数组,然后再对该byte数组使用utf-8-sig进行decode,即: 另一种方法,直接使用‘utf-8-sig’打开文件: 4.总结 写文档或者读文档是python经常用到的操作,如使用open(‘test.txt‘,encoding=‘utf-8‘)的方式打开文档,当在处理第一行数据的时候可能由于自己忽略导致问题。 本文对出错的原因及解决办法进行了说明。 参考: https://stackoverflow.com/questions/17912307/u-ufeff-in-python-string https://songlee24.github.io/2015/05/02/endianess/ Python读取文件,使用split进行分割时,出现\ufeff 标签:list 文档 unicode template 参考 targe 解决办法 连续 函数 原文地址:https://www.cnblogs.com/rocly/p/9561585.html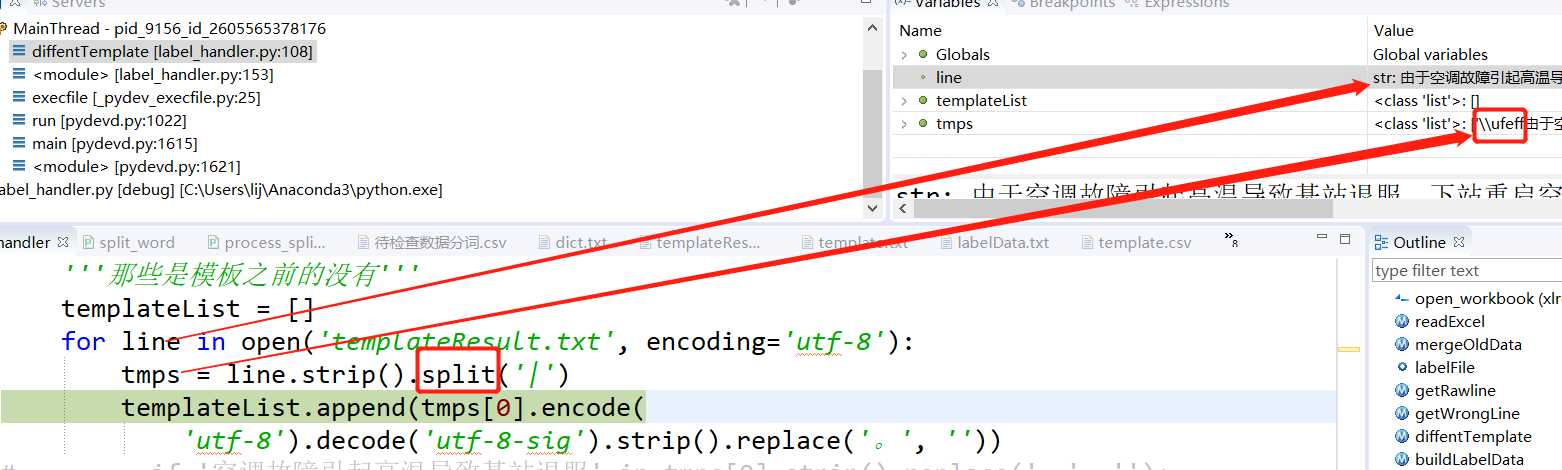
u = u‘ABC‘
e8 = u.encode(‘utf-8‘) # encode without BOM(没考虑BOM)
e8s = u.encode(‘utf-8-sig‘) # encode with BOM(考虑了BOM)
e16 = u.encode(‘utf-16‘) # encode with BOM
e16le = u.encode(‘utf-16le‘) # encode without BOM
e16be = u.encode(‘utf-16be‘) # encode without BOM
templateList = []
for line in open(‘templateResult.txt‘, encoding=‘utf-8‘):
tmps = line.strip().split(‘|‘)
templateList.append(tmps[0].encode(
‘utf-8‘).decode(‘utf-8-sig‘).strip().replace(‘。‘, ‘‘))
templateList = []
for line in open(‘templateResult.txt‘, encoding=‘utf-8-sig‘):
tmps = line.strip().split(‘|‘)
templateList.append(tmps[0].strip().replace(‘。‘, ‘‘))
上一篇:Java 包(package)
下一篇:Java 封装
文章标题:Python读取文件,使用split进行分割时,出现\ufeff
文章链接:http://soscw.com/index.php/essay/103215.html