c++ 实现https网页上的图片爬取
2021-07-10 21:06
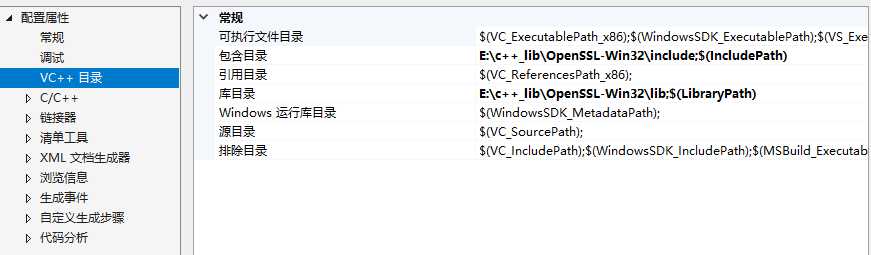
标签:object chart gecko else using pop 技术分享 tin iterator 一.主要的原理 我们通过发送一个http请求,获得目标网页的html源代码,然后通过正则表达式获取到图片的URL,把该网页的所有的图片都保存到一个文件夹,这就是整个软件的流程。 二.具体的实践 现在很多的网站都是https协议但是有一部分还是http协议,其实https就是http协议的安全版本,相当于http+ssl,SSL是介于HTTP应用层和TCP传输层,和HTTP相比HTTPS发送数据需要SSL加密,然后发送。所以说我们想通过https协议发送数据给服务器,需要经历一下这几个步骤: 首先我们先和服务器进行socket连接,然后将SSL和创建的socket套接字进行绑定,之后我们发送数据都是通过SSL发送即可,下面介绍一下具体的流程: 首先我们先进行socket连接: HTTPS=HTTP + SSL,因此利用OpenSSL发送请求给HTTPS站点和第二章的SOCKET发送HTTP是非常相似的,只不过要在原生的套接字上套上SSL层,基本流程如下: a. WSAStartup对Winsock服务进行初始化 b. 建立socket套接字 c. connect连接服务端 d. 建立SSL上下文 e. 建立SSL f. 将SSL与前面建立的socket套接字绑定 g. SSL_write()发送数据 h. SSL_read()接收数据 三.遇到的问题 1.首先VS控制台的编码方式是GBK的方式,但是有的网页就是UTF-8所以我们要进行这方面的转换 2.OPENSSL的安装 网上有很多自己下载源码然后自己编译的,但是在这个项目中我们可以直接使用别人编译好的库不用自己进行编译,直接在VS的项目目录中添加即可 3.还有就是图片的下载,是这种LPCWSTR数据类型的,我们通过string转换成LPCWSTR(不知道为什么URLDownloadToFile里面的两个都要这样进行转换不能用其他的函数) 这是完整的下载的代码: 四.完整代码 下面是头文件: c++ 实现https网页上的图片爬取 标签:object chart gecko else using pop 技术分享 tin iterator 原文地址:https://www.cnblogs.com/yskn/p/9552981.html//建立TCP连接
bool Connect()
{
//初始化套接字
WSADATA wsadata;
if (0 != WSAStartup(MAKEWORD(2, 2), &wsadata)) return false;
//创建套接字
g_sock = socket(AF_INET, SOCK_STREAM, 0);
if (g_sock == INVALID_SOCKET) return false;
//将域名转换为IP地址
hostent *p = gethostbyname(g_Host);
if (p == NULL) return false;
sockaddr_in sa;
memcpy(&sa.sin_addr, p->h_addr, 4);
sa.sin_family = AF_INET;
sa.sin_port = htons(443);
if (SOCKET_ERROR == connect(g_sock, (sockaddr*)&sa, sizeof(sockaddr))) return false;
return true;
}
bool SSL_Connect()
{
// Register the error strings for libcrypto & libssl
ERR_load_BIO_strings();
// SSl库的初始化,载入SSL的所有算法,载入所有的SSL错误信息
SSL_library_init();
OpenSSL_add_all_algorithms();
SSL_load_error_strings();
// New context saying we are a client, and using SSL 2 or 3
sslContext = SSL_CTX_new(SSLv23_client_method());
if (sslContext == NULL)
{
ERR_print_errors_fp(stderr);
return false;
}
// Create an SSL struct for the connection
sslHandle = SSL_new(sslContext);
if (sslHandle == NULL)
{
ERR_print_errors_fp(stderr);
return false;
}
// Connect the SSL struct to our connection
if (!SSL_set_fd(sslHandle, g_sock))
{
ERR_print_errors_fp(stderr);
return false;
}
// Initiate SSL handshake
if (SSL_connect(sslHandle) != 1)
{
ERR_print_errors_fp(stderr);
return false;
}
return true;
}
string UtfToGbk(const char* utf8)
{
int len = MultiByteToWideChar(CP_UTF8, 0, utf8, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_UTF8, 0, utf8, -1, wstr, len);
len = WideCharToMultiByte(CP_ACP, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wstr, -1, str, len, NULL, NULL);
if (wstr) delete[] wstr;
return str;
}
string savepath = "E:\\c++_file\\网络爬虫1\\网络爬虫\\网络爬虫\\img\\"+to_string(i)+".jpg";
size_t len1 = savepath.length();
wchar_t* imgsavepath = new wchar_t[len1];
int nmlen1 = MultiByteToWideChar(CP_ACP, 0, savepath.c_str(), len1 + 1, imgsavepath, len1);
//URL生成
per = mat[1].str();
size_t len = per.length();//获取字符串长度
int nmlen = MultiByteToWideChar(CP_ACP, 0, per.c_str(), len + 1, NULL, 0);//如果函数运行成功,并且cchWideChar为零 //返回值是接收到待转换字符串的缓冲区所需求的宽字符数大小。
wchar_t* buffer = new wchar_t[nmlen];
MultiByteToWideChar(CP_ACP, 0, per.c_str(), len + 1, buffer, nmlen);
//保存路径
string savepath = "E:\\c++_file\\网络爬虫1\\网络爬虫\\网络爬虫\\img\\"+to_string(i)+".jpg";
size_t len1 = savepath.length();
wchar_t* imgsavepath = new wchar_t[len1];
int nmlen1 = MultiByteToWideChar(CP_ACP, 0, savepath.c_str(), len1 + 1, imgsavepath, len1);
cout
#include "spider.h"
int main()
{
cout q;
q.push(startUrl);
while (!q.empty())
{
string cururl = q.front();
q.pop();
//解析URL
if (false == Analyse(cururl))
{
cout h_addr, 4);
sa.sin_family = AF_INET;
sa.sin_port = htons(443);
if (SOCKET_ERROR == connect(g_sock, (sockaddr*)&sa, sizeof(sockaddr))) return false;
return true;
}
bool SSL_Connect()
{
// Register the error strings for libcrypto & libssl
ERR_load_BIO_strings();
// SSl库的初始化,载入SSL的所有算法,载入所有的SSL错误信息
SSL_library_init();
OpenSSL_add_all_algorithms();
SSL_load_error_strings();
// New context saying we are a client, and using SSL 2 or 3
sslContext = SSL_CTX_new(SSLv23_client_method());
if (sslContext == NULL)
{
ERR_print_errors_fp(stderr);
return false;
}
// Create an SSL struct for the connection
sslHandle = SSL_new(sslContext);
if (sslHandle == NULL)
{
ERR_print_errors_fp(stderr);
return false;
}
// Connect the SSL struct to our connection
if (!SSL_set_fd(sslHandle, g_sock))
{
ERR_print_errors_fp(stderr);
return false;
}
// Initiate SSL handshake
if (SSL_connect(sslHandle) != 1)
{
ERR_print_errors_fp(stderr);
return false;
}
return true;
}
bool Gethtml(string & html)
{
char temp1[100];
sprintf(temp1, "%d", 166);
string c_get;
c_get = c_get
+ "GET " + g_Object + " HTTP/1.1\r\n"
+ "Host: " + g_Host + "\r\n"
+ "Content-Type: text/html; charset=UTF-8\r\n"
//+ "Content-Length:" + temp1 + "\r\n"
//+ "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299\r\n"
+ "Connection:Close\r\n\r\n";
//+ temp;
SSL_write(sslHandle, c_get.c_str(), c_get.length());
char buff[101];
int nreal = 0;
while ((nreal = SSL_read(sslHandle, buff, 100)) > 0)
{
buff[nreal] = ‘\0‘;
html += UtfToGbk(buff);
//printf("%s\n", buff);
memset(buff, 0, sizeof(buff));
}
//printf("%s\n", html);
return true;
}
string UtfToGbk(const char* utf8)
{
int len = MultiByteToWideChar(CP_UTF8, 0, utf8, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_UTF8, 0, utf8, -1, wstr, len);
len = WideCharToMultiByte(CP_ACP, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wstr, -1, str, len, NULL, NULL);
if (wstr) delete[] wstr;
return str;
}
bool RegexIamage(string & html)
{
smatch mat;
regex rgx("src=\"(.*(png|svg|jpg))\"");
string::const_iterator start = html.begin();
string::const_iterator end = html.end();
string per;
int i = 1;
while (regex_search(start, end, mat, rgx))
{
//URL生成
per = mat[1].str();
size_t len = per.length();//获取字符串长度
int nmlen = MultiByteToWideChar(CP_ACP, 0, per.c_str(), len + 1, NULL, 0);//如果函数运行成功,并且cchWideChar为零 //返回值是接收到待转换字符串的缓冲区所需求的宽字符数大小。
wchar_t* buffer = new wchar_t[nmlen];
MultiByteToWideChar(CP_ACP, 0, per.c_str(), len + 1, buffer, nmlen);
//保存路径
string savepath = "E:\\c++_file\\网络爬虫1\\网络爬虫\\网络爬虫\\img\\"+to_string(i)+".jpg";
size_t len1 = savepath.length();
wchar_t* imgsavepath = new wchar_t[len1];
int nmlen1 = MultiByteToWideChar(CP_ACP, 0, savepath.c_str(), len1 + 1, imgsavepath, len1);
cout
#pragma once
#include
文章标题:c++ 实现https网页上的图片爬取
文章链接:http://soscw.com/index.php/essay/103402.html