python+selenium面试题
2021-07-13 07:05
selenium中如何判断元素是否存在?
selenium中没有提供原生的方法判断元素是否存在,一般我们可以通过定位元素+异常捕获的方式判断。
# 判断元素是否存在
try:
dr.find_element_by_id(‘none‘)
except NoSuchElementException:
print ‘element does not exist‘
selenium中hidden或者是display = none的元素是否可以定位到?
不可以,selenium不能定位不可见的元素。display=none的元素实际上是不可见元素。
selenium中如何保证操作元素的成功率?也就是说如何保证我点击的元素一定是可以点击的?
- 当网速不好的情况下,使用合适的等待时间
- 被点击的元素一定要占一定的空间,因为selenium默认会去点这个元素的中心点,不占空间的元素算不出来中心点;
- 被点击的元素不能被其他元素遮挡;
- 被点击的元素不能在viewport之外,也就是说如果元素必须是可见的或者通过滚动条操作使得元素可见;
- 判断元素是否是可以被点击的
如何提高selenium脚本的执行速度?
- 使用更高配置的电脑和选择更快的网络环境
- 使用效率更高的语言,比如java执行速度就快过python
- 优化代码
- 不要盲目的加
sleep,尽量使用显式等待 - 对于firefox,考虑使用测试专用的profile,因为每次启动浏览器的时候firefox会创建1个新的profile,对于这个新的profile,所有的静态资源都是从服务器直接下载,而不是从缓存里加载,这就导致网络不好的时候用例运行速度特别慢的问题
- chrome浏览器和safari浏览器的执行速度看上去是最快的
- 可以考虑分布式执行或者使用selenium grid
用例在运行过程中经常会出现不稳定的情况,也就是说这次可以通过,下次就没办法通过了,如何去提升用例的稳定性?
- 测试专属profile,尽量让静态资源缓存
- 尽量使用显式等待
- 尽量使用测试专用环境,避免其他类型的测试同时进行,对数据造成干扰
你的自动化用例的执行策略是什么?
- 每日执行:比如每天晚上在主干执行一次
- 周期执行:每隔2小时在开发分之执行一次
- 动态执行:每次代码有提交就执行
自动化测试的时候是不是需要连接数据库做数据校验?
一般不需要,因为这是单元测试层做的事情,在自动化测试层尽量不要为单元测试层没做的工作还债。
id,name,clas,xpath, css selector这些属性,你最偏爱哪一种,为什么?
xpath和css最为灵活,所以其他的答案都不够完美。
如何去定位页面上动态加载的元素?
显式等待
如何去定位属性动态变化的元素?
找出属性动态变化的规律,然后根据上下文生成动态属性。
点击链接以后,selenium是否会自动等待该页面加载完毕?
java binding在点击链接后会自动等待页面加载完毕。
selenium的原理是什么?
selenium的原理涉及到3个部分,分别是
- 浏览器
- driver: 一般我们都会下载driver
- client: 也就是我们写的代码
client其实并不知道浏览器是怎么工作的,但是driver知道,在selenium启动以后,driver其实充当了服务器的角色,跟client和浏览器通信,client根据webdriver协议发送请求给driver,driver解析请求,并在浏览器上执行相应的操作,并把执行结果返回给client。这就是selenium工作的大致原理。
webdriver的协议是什么?
client与driver之间的约定,无论client是使用java实现还是c#实现,只要通过这个约定,client就可以准确的告诉drier它要做什么以及怎么做。
webdriver协议本身是http协议,数据传输使用json。
这里有webdriver协议的所有endpoint,稍微看一眼就知道这些endpoints涵盖了selenium的所有功能。
启动浏览器的时候用到的是哪个webdriver协议?
New Session,如果创建成功,返回sessionId和capabilities。
什么是page object设计模式?
官方介绍,简单来说就是用class去表示被测页面。在class中定义页面上的元素和一些该页面上专属的方法。
例子
public class LoginPage {
private final WebDriver driver;
public LoginPage(WebDriver driver) {
this.driver = driver;
// Check that we‘re on the right page.
if (!"Login".equals(driver.getTitle())) {
// Alternatively, we could navigate to the login page, perhaps logging out first
throw new IllegalStateException("This is not the login page");
}
}
// The login page contains several HTML elements that will be represented as WebElements.
// The locators for these elements should only be defined once.
By usernameLocator = By.id("username");
By passwordLocator = By.id("passwd");
By loginButtonLocator = By.id("login");
// The login page allows the user to type their username into the username field
public LoginPage typeUsername(String username) {
// This is the only place that "knows" how to enter a username
driver.findElement(usernameLocator).sendKeys(username);
// Return the current page object as this action doesn‘t navigate to a page represented by another PageObject
return this;
}
// The login page allows the user to type their password into the password field
public LoginPage typePassword(String password) {
// This is the only place that "knows" how to enter a password
driver.findElement(passwordLocator).sendKeys(password);
// Return the current page object as this action doesn‘t navigate to a page represented by another PageObject
return this;
}
// The login page allows the user to submit the login form
public HomePage submitLogin() {
// This is the only place that submits the login form and expects the destination to be the home page.
// A seperate method should be created for the instance of clicking login whilst expecting a login failure.
driver.findElement(loginButtonLocator).submit();
// Return a new page object representing the destination. Should the login page ever
// go somewhere else (for example, a legal disclaimer) then changing the method signature
// for this method will mean that all tests that rely on this behaviour won‘t compile.
return new HomePage(driver);
}
// The login page allows the user to submit the login form knowing that an invalid username and / or password were entered
public LoginPage submitLoginExpectingFailure() {
// This is the only place that submits the login form and expects the destination to be the login page due to login failure.
driver.findElement(loginButtonLocator).submit();
// Return a new page object representing the destination. Should the user ever be navigated to the home page after submiting a login with credentials
// expected to fail login, the script will fail when it attempts to instantiate the LoginPage PageObject.
return new LoginPage(driver);
}
// Conceptually, the login page offers the user the service of being able to "log into"
// the application using a user name and password.
public HomePage loginAs(String username, String password) {
// The PageObject methods that enter username, password & submit login have already defined and should not be repeated here.
typeUsername(username);
typePassword(password);
return submitLogin();
}
}
什么是page factory?
Page Factory实际上是官方给出的java page object的工厂模式实现。
怎样去选择一个下拉框中的value=xx的option?
使用select类,具体看这里
如何在定位元素后高亮元素(以调试为目的)?
使用javascript将元素的border或者背景改成黄色就可以了。
什么是断言?
可以简单理解为检查点,就是预期和实际的比较
- 如果预期等于实际,断言通过,测试报告上记录pass
- 如果预期不等于实际,断言失败,测试报告上记录fail
如果你进行自动化测试方案的选型,你会选择哪种语言,java,js,python还是ruby?
- 哪个熟悉用哪个
- 如果都不会,团队用哪种语言就用那种
page object设置模式中,是否需要在page里定位的方法中加上断言?
一般不要,除非是要判断页面是否正确加载。
Generally don’t make assertions
page object设计模式中,如何实现页面的跳转?
返回另一个页面的实例可以代表页面跳转。
// The login page allows the user to submit the login form
public HomePage submitLogin() {
// This is the only place that submits the login form and expects the destination to be the home page.
// A seperate method should be created for the instance of clicking login whilst expecting a login failure.
driver.findElement(loginButtonLocator).submit();
// Return a new page object representing the destination. Should the login page ever
// go somewhere else (for example, a legal disclaimer) then changing the method signature
// for this method will mean that all tests that rely on this behaviour won‘t compile.
return new HomePage(driver);
}
自动化测试用例从哪里来?
手工用例的子集,尽量
- 简单而且需要反复回归
- 稳定,也就是不要经常变来变去
- 核心,优先覆盖核心功能
你觉得自动化测试最大的缺陷是什么?
- 实现成本高
- 运行速度较慢
- 需要一定的代码能力才能及时维护
什么是分层测试?
画给他/她看。
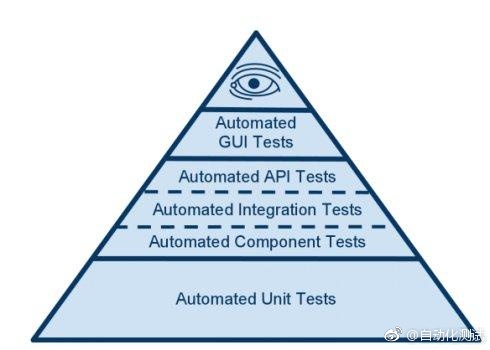
webdriver可以用来做接口测试吗?
不用纠结,不可以。
selenium 是否可以调用js来对dom对象进行操作?
是
selenium 是否可以向页面发送鼠标滚轮操作?
不能
selenium 是否可以模拟拖拽操作?
可以
selenium 对下拉列表的中的选项进行选择操作时,需要被操作对象的标签是什么?
select
selenium 上传文件操作,需要被操作对象的type属性是什么?
file
1. 什么是页面加载超时
Selenium中有一个 Page Load wait的方法,有时候,我们执行脚本的速度太快,但是网页程序还有一部分页面没有完全加载出来,就会遇到元素不可见或者元素找不到的异常。为了解决问题,让脚本流畅的运行,我们可以通过设置页面加载超时时间。具体代码是这个:driver.manage().timeouts().pageLoadTimeout(10,TimeUnit.SECONDS);
这行作用就是,如果页面加载超过10秒还没有完成,就抛出页面加载超时的异常。
2.什么是JavaScript Executor,你什么时候会用到这个?
JavaScript Executor是一个接口,给driver对象提供一个执行javaScript并访问和修改前端元素属性和值。
还是有比较多的场景,我们可能或者需要借助javaScript来实现:
1.元素通过现有定位表达式不能够实现点击
2.前端页面试用了ck-editor这个插件
3.处理时间日期插件(可能)
4.生成一个alert弹窗
5.拖拽滚动条
基本语法:
JavascriptExecutor js =(JavascriptExecutor) driver;
js.executeScript(Script,Arguments);
相关具体例子:http://blog.csdn.net/u011541946/article/details/73751252
http://blog.csdn.net/u011541946/article/details/73656609
3.在Selenium中如何实现截图,如何实现用例执行失败才截图
在Selenium中提供了一个TakeScreenShot这么一个接口,这个接口提供了一个getScreenshotAs()方法可以实现全屏截图。然后我们通过java中的FileUtils来实现把这个截图拷贝到保存截图的路径。
代码举例:
File src=((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
try {
// 拷贝到我们实际保存图片的路径
FileUtils.copyFile(src,new File("C:/selenium/error.png"));
}
catch (IOException e)
{
System.out.println(e.getMessage());
}
如果要实现执行用例发现失败就自动截图,那么我们需要把这个截图方法进行封装。然后在测试代码中的catch代码块去调用这个截图方法。这个我们在POM的框架中一般是把截图方法封装到BasePage这个文件中。
4.在Selenium中如何实现拖拽滚动条?
在Selenium中通过元素定位会自动帮你拖拽到对应位置,所以是没有自带的scoll方法。但是这个是有限制,例如当前页面高度太长,默认是页上半部分,你定位的元素在页尾,这个时候可能就会报元素不可见的异常。我们就需要利用javaScript来实现拖拽页面滚动条。
我们一般可以两个方法去拖拽,一个是根据拖拽的坐标(像素单位),另外一个是根据拖拽到一个参考元素附件。
代码举例(根据元素坐标拖拽):
JavascriptExecutor jse= (JavascriptExecutor)driver;
jse.executeScript("window.scrollBy(0,250)", "");
相关拖拽文章:http://blog.csdn.net/u011541946/article/details/73656609
5.如何实现文件上传?
我们在web页面实现文件上传过程中,可以直接把文件在磁盘完整路径,通过sendKeys方法实现上传。如果这种方法不能实现上传,我们就可能需要借助第三方工具,我用过一个第三方工具叫autoIT.
参考博客文章:http://blog.csdn.net/u011541946/article/details/74359517
还有一个方法是利用robot类:
http://blog.csdn.net/u011541946/article/details/74332938
6.如何处理“不受信任的证书”的问题?
例如,在登录12306网站的时候,如果你没有下载和安装过这个网站的根证书,那么你就会遇到打开12306网站提示证书不受信任的拦截页面。
下面举例火狐和谷歌上处理这个问题的基本代码
火狐:
// 创建firefoxprofile
FirefoxProfile profile=new FirefoxProfile();
// 点击继续浏览不安全的网站
profile.setAcceptUntrustedCertificates(true);
// 使用带条件的profile去创建一个driver对象
WebDriver driver=new FirefoxDriver(profile);
Chrome:
// 创建类DesiredCapabilities的对象
DesiredCapabilities cap=DesiredCapabilities.chrome();
// 设置ACCEPT_SSL_CERTS 变量值为true
cap.setCapability(CapabilityType.ACCEPT_SSL_CERTS, true);
// 新建一个带capability的chromedriver对象
WebDriver driver=new ChromeDriver(cap);
相关博客文章:http://blog.csdn.net/u011541946/article/details/74013466
7.什么是Firefox Profile?
Profile是一组文件,主要用来记录用户在火狐浏览器上的私人信息,例如书签,密码,用户首选项,下载文件夹保存路径等。简单来说,你打开火狐浏览器输入about://config,这个页面有些设置选项是可以通过profile来实现修改的。
在我博客中BrowserEngine.java中,就有profile的简单使用,主要是用来设置下载文件的保存路径。http://blog.csdn.net/u011541946/article/details/76598441
8.如何实现鼠标悬停,键盘事件和拖拽动作?
在Webdriver中,处理键盘事件和鼠标事件,一般使用Actions类提供的方法,包括鼠标悬停,拖拽和组合键输入。
这里介绍几个方法
方法:clickAndHold()
使用场景:找到一个元素,点击鼠标左键,不放手。自己可以点击鼠标不松开试试这个场景。
方法:contentClick()
使用场景:模拟鼠标右键点击,一般右键会带出菜单来。
方法:doubelClick()
使用场景:模拟鼠标双击
方法:dragAndDrop(source,target)
使用场景:模拟从source这个位置,拖拽一个元素到target位置
键盘事件方法:keyDown(keys.ALT), keyUp(keys.SHIFT)
使用场景:点击键盘事件,分为两个动作,一个点击键盘,第二个动作是释放点击(松开)
相关博客文章:http://blog.csdn.net/u011541946/article/details/74043595
上一篇:python中函数和方法的区别
下一篇:js删除数组的某个元素
文章标题:python+selenium面试题
文章链接:http://soscw.com/index.php/essay/104524.html