python告诉你ti8 dota2英雄bp
2021-07-14 13:06
标签:创建 ict 情况 2tp image read style json blog 文章链接:https://mp.weixin.qq.com/s/phJzZEQojndY-iNe77RF_w 恭喜OG成为ti8冠军,很可惜这次偶数年ti8中国队LGD与冠军失之交臂。 上学那会儿还是个dota的玩家,现在已经不玩了,对于这种国际性的赛事还是会比较关注的,这篇文章就是爬取ti8期间,bp英雄的统计(b是ban的简称:禁止一个英雄上场;p是pick的简称:挑选英雄上场)。 python爬虫之前写过几篇文章的,都是用requests+ BeautifulSoup 进行页面解析获取数据的。 python itchat 爬取微信好友信息 python爬虫学习:爬虫QQ说说并生成词云图,回忆满满 一如既往的,找到这样的页面,但是却解析不到这些数据。 再仔细一看,原来这些数据是js动态加载渲染的,可以看到是接口请求来的数据,庆幸的是这个接口不需要cookie之类的验证信息的,直接get请求可以拿到数据,这样处理起来就方便的,对照页面可以知道json格式的各字段名。 数据来源是接口,直接 通过json.loads 去解析string类型的数据,主要数据格式如下: 每个item含radiant、dire ,其中 这里是用循环不断去请求获取的,每次的数据是20条,可以改变size改变条数。 每项里面的bans、picks数据都要处理,每个英雄是一条记录,重复的就+1,所以给每个英雄count 的属性,记录次数。 每条英雄数据是个键值对字典,键是name 属性即英文名字,值就是bans、picks里的各项英雄数据,顺便加上了count 属性。每个英雄数据存在dict() 分别获取两只队伍bp数据存放 也可以统计所有英雄的出场次数,非搬即选bp_list。 以上数据我们得到的是字典,里面有各英雄的bp次数,现在要对这些数据进行排序,按次数从大到小排序,这里就用到 得到的是数组,生成表格在之前这篇文章中有过使用,这里使用的是 第一行是表头,对应的每一列填充数据 excel 表格生成,还可以插入柱状图。 效果图: 这里只是简单的对数据进行筛选展示,这些数据还是可以用来做更多的数据分析的,数据来源:刀魔数据。 最后放上lgd的图片,希望他们明年能在ti9上再干回来 欢迎关注我的博客:https://blog.manjiexiang.cn/ 有个「佛系码农圈」,欢迎大家加入畅聊,开心就好! python告诉你ti8 dota2英雄bp 标签:创建 ict 情况 2tp image read style json blog 原文地址:https://www.cnblogs.com/taixiang/p/9538476.html
json结构分析
response = requests.get(url)
data = json.loads(response.text){
total: 402,
data: [{
match_id: 4080856812,
radiant: {
team_id: 15,
name: "PSG.LGD",
tag: "PSG.LGD",
country_code: "CN",
score: 34,
bans: [{ //每个英雄数据
name: "spectre",
name_cn: "幽鬼",
id: 67
}, ...],
picks: [{
name: "earthshaker",
name_cn: "撼地者",
id: 7
}, ...]
},
dire: {
team_id: 2586976,
name: "OG",
tag: "OG",
country_code: "US",
score: 35,
bans: [{
name: "tiny",
name_cn: "小小",
id: 19
}, ...],
picks: [{
name: "furion",
name_cn: "先知",
id: 53
}, ...]
},
radiant_win: 0,
end_time: "2018-08-26 10:51"
}, ...]
}radiant_win: 1,代表radiant 获胜,0 则代表dire 获胜。bans里面的是ban的英雄数据列表,picks里面是pick的英雄数据列表。page = 1
while True:
url = "https://www.dotamore.com/api/v1/league/matchlist?league_id=9870&page=%d&size=20" % page
response = requests.get(url)
data = json.loads(response.text)
page += 1
for item in data["data"]:
# 比赛从8月16开始,小于这个时间生成excel,跳出循环
if item["end_time"] bp数据
# item 指radiant 或dire 的bans、picks列表数据
def bp(item, bp_dict):
if item is None:
return
# 遍历bans 或picks 数据
for i, bp in enumerate(item):
key = bp["name"]
# 如果这个英雄已存在,count+1
if key in bp_dict.keys():
bp_dict[key]["count"] = bp_dict[key]["count"] + 1
else: # 不存在就记录一条数据
bp_dict[key] = copy.deepcopy(bp)
bp_dict[key].update(count=1)
return bp_dict{ //每条英雄数据
name: "tiny",
name_cn: "小小",
id: 19,
count:1
}b_dict = dict()
p_dict = dict()
# ban的数据
bp(item["radiant"]["bans"], b_dict)
bp(item["dire"]["bans"], b_dict)
# pick的数据
bp(item["radiant"]["picks"], p_dict)
bp(item["dire"]["picks"], p_dict)
还可以获取冠军队伍的bp情况,team_id 即队伍的id。if item["radiant_win"] == 0:
if item["dire"]["team_id"] == "2586976":
bp(item["dire"]["bans"], b_win_dict)
bp(item["dire"]["picks"], p_win_dict)
else:
if item["radiant"]["team_id"] == "2586976":
bp(item["radiant"]["bans"], b_win_dict)
bp(item["radiant"]["picks"], p_win_dict)生成excel
sorted()方法# x[0]是根据键排序,x[1]是根据值,这里的值是字典,取["count"]项排序,得到的是元祖的list
new_b_dict = sorted(b_dict.items(), key=lambda x: x[1]["count"], reverse=True)xlsxwriter三方库来操作excel 表格的。# 创建excel表格
file = xlsxwriter.Workbook("dota.xlsx")
# 创建工作表1
sheet1 = file.add_worksheet("sheet1")
# 创建表头
headers = ["图片", "英雄", "ban", "", "图片", "英雄", "pick", "", "图片", "英雄", "bp_all"]
for i, header in enumerate(headers):
# 第一行为表头
sheet1.write(0, i, header)def insert_data(sheet1, headers, bp_list, col1, col2, col3):
for row in range(len(bp_list)): # 行
# 设置行高
sheet1.set_row(row + 1, 30)
for col in range(len(headers)): # 列
if col == col1: # 英雄图片,根据id获取
url = "http://cdn.dotamore.com/heros_id_62_35/%d.png" % bp_list[row][1]["id"]
image_data = BytesIO(urlopen(url).read())
sheet1.insert_image(row + 1, col, url, {"image_data": image_data})
if col == col2: # 英雄名
name = bp_list[row][1]["name_cn"]
sheet1.write(row + 1, col, name)
if col == col3: # 统计次数
count = bp_list[row][1]["count"]
sheet1.write(row + 1, col, count)def insert_chart(file, sheet1, bp_list, name, M, col_x, col_y):
chart = file.add_chart({"type": "column"}) # 柱状图
chart.add_series({
"categories": ["sheet1", 1, col_x, len(bp_list), col_x], # 图表类别标签范围,x轴,这里取英雄的名字,即英雄名字那一列,行数根据数据列表确定
"values": ["sheet1", 1, col_y, len(bp_list), col_y], # 图表数据范围,y轴,即次数那一列,行数根据数据列表确定
"data_labels": {"value": True},
})
chart.set_title({"name": name}) # 图表标题
chart.set_size({"width": 2000, "height": 400})
chart.set_x_axis({‘name‘: ‘英雄‘}) # x轴描述
chart.set_y_axis({‘name‘: ‘次数‘}) # y轴描述
chart.set_style(3) # 直方图类型
sheet1.insert_chart(M, chart) # 在表格M处插入柱状图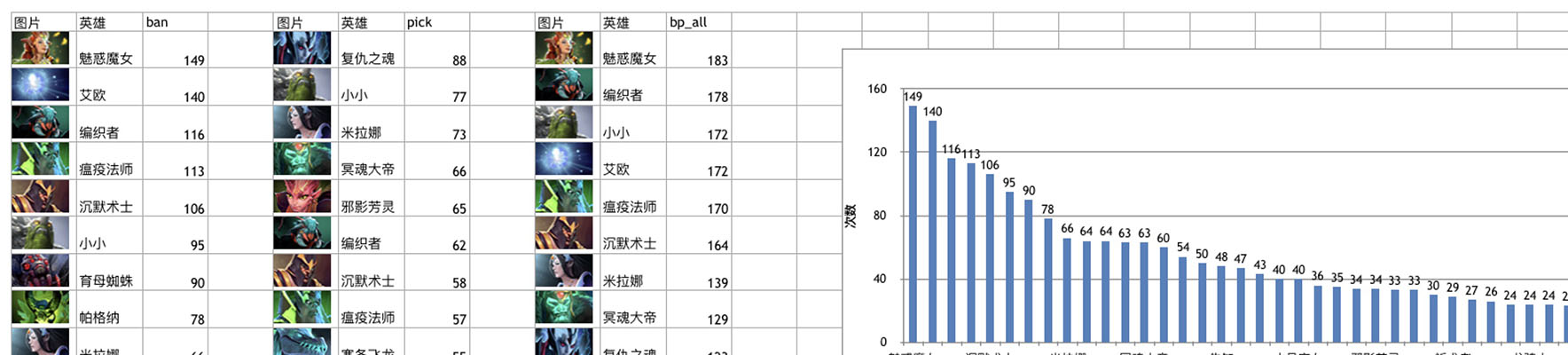
github地址:https://github.com/taixiang/py_dota

更多精彩欢迎关注微信号:春风十里不如认识你

过期了,可加我微信 tx467220125 拉你入群。
下一篇:Playrix Codescapes Cup (Codeforces Round #413, rated, Div. 1 + Div. 2) C. Fountains 【树状数组维护区间最大值】
文章标题:python告诉你ti8 dota2英雄bp
文章链接:http://soscw.com/index.php/essay/105116.html