使用idea在windows上连接远程hadoop开发
2021-07-15 12:14
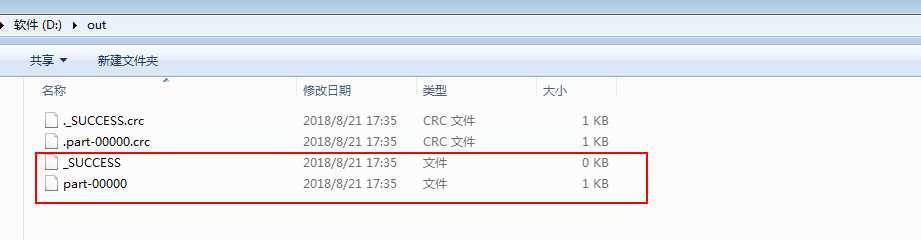
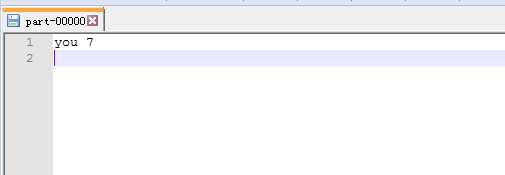
标签:throws equal miss not ima 配置 his ice ted 一.前置环境准备 1.下载一份hadoop本地解压,配置HADOOP_HOME的环境变量 idea运行时会读这个环境变量然后找到他里面的bin文件,其实不需要启动 只要有bin这个目录就行,不然会报错 找不到HADOOP_HOME这个环境变量 2.bin里面缺少了winutils.exe和hadoop.dll 需要额外下载 https://github.com/steveloughran/winutils 也可以不下载hadoop直接下载这个bin把环境变量配置成这个bin的上一级目录 3.将hadoop.dll 复制到C:\Windows\System32中 否则 会报 Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z 二.构建项目 1.导入jar 2.拷贝源码中WordCount.java 位置在 hadoop-3.1.0-src\hadoop-mapreduce-project\hadoop-mapreduce-client\hadoop-mapreduce-client-jobclient\src\test\java\org\apache\hadoop\mapred目录中 我这个稍有改动 运行可能会报权限不足的问题 ,编辑服务器etc/hadoop/hdfs-site.xml 将 dfs.permissions修改为false 重启即可 好啦 现在运行 控制台没有任何报错 去D盘看看 D盘已经生成了out文件夹 打开out 发现里面有四个文件 比服务器本地执行多了两个.crc文件 我们先看看part-00000 已经出来统计结果了 。idea本地调用远程hadoop服务成功! eclipse应该也差不多 ,之前百度大多是eclipse的教程,而且好像还要有什么插件,但是今天就弄了几个文件就好了,不知道是不是hadoop3对windows方面做了升级。 刚刚也打开了crc文件里面是乱码 百度了一下说是hadoop数据校验文件 大家有兴趣可以看看这篇博客 了解crc文件更多知识 (我是只看了前面 是不是太没耐心了 。。。) https://www.cnblogs.com/gpcuster/archive/2011/01/26/1945363.html 还在一个人摸爬滚打学习hadoop 大家有兴趣可以一起交流 使用idea在windows上连接远程hadoop开发 标签:throws equal miss not ima 配置 his ice ted 原文地址:https://www.cnblogs.com/xingluo/p/9512961.htmldependency>
groupId>org.apache.hadoopgroupId>
artifactId>hadoop-commonartifactId>
version>3.1.0version>
dependency>
dependency>
groupId>org.apache.hadoopgroupId>
artifactId>hadoop-hdfsartifactId>
version>3.1.0version>
dependency>
dependency>
groupId>org.apache.hadoopgroupId>
artifactId>hadoop-mapreduce-client-coreartifactId>
version>3.1.0version>
dependency>
dependency>
groupId>org.apache.hadoopgroupId>
artifactId>hadoop-mapreduce-client-jobclientartifactId>
version>3.1.0version>
dependency>
dependency>
groupId>org.apache.hadoopgroupId>
artifactId>hadoop-mapreduce-client-commonartifactId>
version>3.1.0version>
dependency>
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* This is an example Hadoop Map/Reduce application.
* It reads the text input files, breaks each line into words
* and counts them. The output is a locally sorted list of words and the
* count of how often they occurred.
*
* To run: bin/hadoop jar build/hadoop-examples.jar wordcount
* [-m maps] [-r reduces] in-dir out-dir
*/
public class WordCount extends Configured implements Tool {
/**
* Counts the words in each line.
* For each line of input, break the line into words and emit them as
* (word, 1).
*/
public static class MapClass extends MapReduceBase
implements Mapper
property>
name>dfs.permissionsname>
value>falsevalue>
property>
文章标题:使用idea在windows上连接远程hadoop开发
文章链接:http://soscw.com/index.php/essay/105570.html