易百教程人工智能python修正-人工智能监督学习(回归)
2021-07-16 10:07
标签:变化 如何 link square ring jpg point cti 可视化 回归是最重要的统计和机器学习工具之一。 我们认为机器学习的旅程从回归开始并不是错的。 它可以被定义为使我们能够根据数据做出决定的参数化技术,或者换言之,允许通过学习输入和输出变量之间的关系来基于数据做出预测。 这里,依赖于输入变量的输出变量是连续值的实数。 在回归中,输入和输出变量之间的关系很重要,它有助于我们理解输出变量的值随输入变量的变化而变化。 回归常用于预测价格,经济,变化等。 在本节中,我们将学习如何构建单一以及多变量回归器。 线性回归器/单变量回归器 让我们重点介绍一些必需的软件包 - 现在,我们需要提供输入数据,并将数据保存在名为 下一步将是培训模型。下面给出培训和测试样本。 现在,我们需要创建一个线性回归器对象。 现在绘制并可视化数据。 执行上面示例代码,输出以下结果 - 现在,我们可以计算线性回归的性能如下 - 在上面的代码中,我们使用了这些小数据源。 如果想要处理一些大的数据集,那么可以使用 多变量回归 现在,需要提供输入数据,并将数据保存在名为 我们将通过使用 下一步将是训练模型; 会提供训练和测试样品数据。 现在,我们需要创建一个线性回归器对象。 现在,最后需要用测试数据做预测。 线性回归器的性能输出结果如下 - 现在,我们将创建一个10阶多项式并训练回归器。并提供样本数据点。 线性回归 - 在上面的代码中,我们使用了这些小数据。 如果想要一个大的数据集,那么可以使用 易百教程移动端:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"教程" 选择相关教程阅读或直接访问:http://m.yiibai.com 。 易百教程人工智能python修正-人工智能监督学习(回归) 标签:变化 如何 link square ring jpg point cti 可视化 原文地址:https://www.cnblogs.com/duoba/p/9534516.html在Python中构建回归器
import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
linear.txt的文件中。input = ‘F:\\notebook\\linear.txt‘
np.loadtxt函数加载这些数据。input_data = np.loadtxt(input, delimiter=‘,‘)
X, y = input_data[:, :-1], input_data[:, -1]
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]
reg_linear = linear_model.LinearRegression()
reg_linear.fit(X_train, y_train)
y_test_pred = reg_linear.predict(X_test)
plt.scatter(X_test, y_test, color = ‘red‘)
plt.plot(X_test, y_test_pred, color = ‘black‘, linewidth = 2)
plt.xticks(())
plt.yticks(())
plt.show()
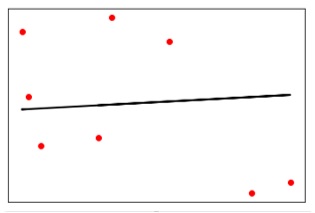
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred),
2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
Mean absolute error = 1.78
Mean squared error = 3.89
Median absolute error = 2.01
Explain variance score = -0.09
R2 score = -0.09
sklearn.dataset来导入更大的数据集。2,4.82.9,4.72.5,53.2,5.56,57.6,43.2,0.92.9,1.92.4,
3.50.5,3.41,40.9,5.91.2,2.583.2,5.65.1,1.54.5,
1.22.3,6.32.1,2.8
首先,让我们导入一些必需的软件包 -import numpy as np
from sklearn import linear_model
import sklearn.metrics as sm
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
linear.txt的文件中。input = ‘F:\\notebook\\Mul_linear.txt‘np.loadtxt函数加载这些数据。input_data = np.loadtxt(input, delimiter=‘,‘)
X, y = input_data[:, :-1], input_data[:, -1]
training_samples = int(0.6 * len(X))
testing_samples = len(X) - num_training
X_train, y_train = X[:training_samples], y[:training_samples]
X_test, y_test = X[training_samples:], y[training_samples:]
reg_linear_mul = linear_model.LinearRegression()
reg_linear_mul.fit(X_train, y_train)
y_test_pred = reg_linear_mul.predict(X_test)
print("Performance of Linear regressor:")
print("Mean absolute error =", round(sm.mean_absolute_error(y_test, y_test_pred), 2))
print("Mean squared error =", round(sm.mean_squared_error(y_test, y_test_pred), 2))
print("Median absolute error =", round(sm.median_absolute_error(y_test, y_test_pred), 2))
print("Explain variance score =", round(sm.explained_variance_score(y_test, y_test_pred), 2))
print("R2 score =", round(sm.r2_score(y_test, y_test_pred), 2))
Mean absolute error = 0.6
Mean squared error = 0.65
Median absolute error = 0.41
Explain variance score = 0.34
R2 score = 0.33
polynomial = PolynomialFeatures(degree = 10)
X_train_transformed = polynomial.fit_transform(X_train)
datapoint = [[2.23, 1.35, 1.12]]
poly_datapoint = polynomial.fit_transform(datapoint)
poly_linear_model = linear_model.LinearRegression()
poly_linear_model.fit(X_train_transformed, y_train)
print("\nLinear regression:\n", reg_linear_mul.predict(datapoint))
print("\nPolynomial regression:\n", poly_linear_model.predict(poly_datapoint))
[2.40170462]
[1.8697225]
sklearn.dataset来导入一个更大的数据集。2,4.8,1.2,3.22.9,4.7,1.5,3.62.5,5,2.8,23.2,5.5,3.5,2.16,5,
2,3.27.6,4,1.2,3.23.2,0.9,2.3,1.42.9,1.9,2.3,1.22.4,3.5,
2.8,3.60.5,3.4,1.8,2.91,4,3,2.50.9,5.9,5.6,0.81.2,2.58,
3.45,1.233.2,5.6,2,3.25.1,1.5,1.2,1.34.5,1.2,4.1,2.32.3,
6.3,2.5,3.22.1,2.8,1.2,3.6
文章标题:易百教程人工智能python修正-人工智能监督学习(回归)
文章链接:http://soscw.com/index.php/essay/105972.html