golang如何实现mapreduce单进程版本详解
2018-09-24 21:28
前言
MapReduce作为hadoop的编程框架,是工程师最常接触的部分,也是除去了网络环境和集群配 置之外对整个Job执行效率影响很大的部分,所以很有必要深入了解整个过程。元旦放假的第一天,在家没事干,用golang实现了一下mapreduce的单进程版本,github地址。处理对大文件统计最高频的10个单词,因为功能比较简单,所以设计没有解耦合。
本文先对mapreduce大体概念进行介绍,然后结合代码介绍一下,如果接下来几天有空,我会实现一下分布式高可用的mapreduce版本。下面话不多说了,来一起看看详细的介绍吧。
1. Mapreduce大体架构
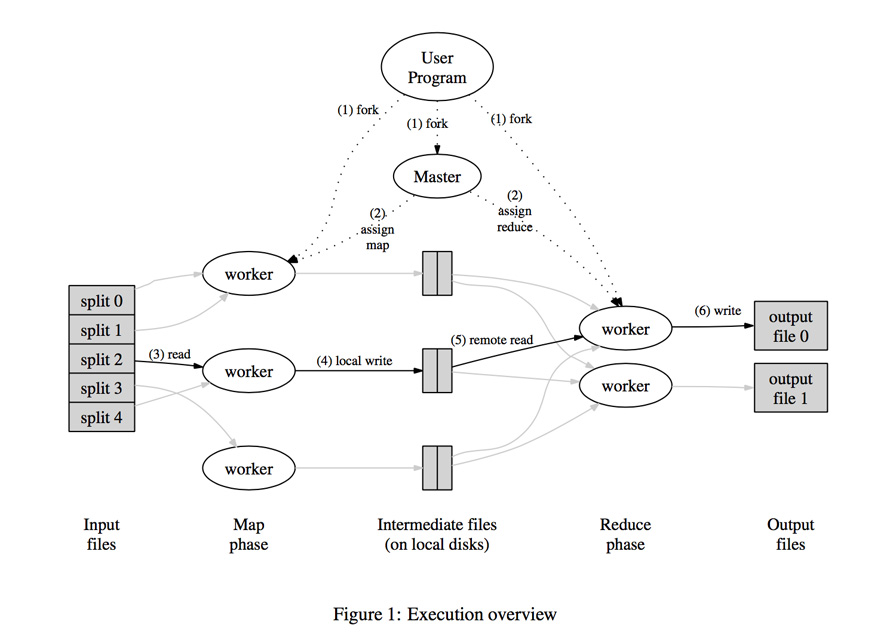
上图是论文中mapreduce的大体架构。总的来说Mapreduce的思想就是分治思想:对数据进行分片,然后用mapper进行处理,以key-value形式输出中间文件;然后用reducer进行对mapper输出的中间文件进行合并:将key一致的合到一块,并输出结果文件;如果有需要,采用Combiner进行最后的合并。
归纳来说主要分为5部分:用户程序、Master、Mapper、Reducer、Combiner(上图未给出)。
用户程序。用户程序主要对输入数据进行分割,制定Mapper、Reducer、Combiner的代码。 Master:中控系统。控制分发Mapper、Reduer的个数,比如生成m个进程处理Mapper,n个进程处理Reducer。其实对Master来说,Mapper和Reduer都属于worker,只不过跑的程序不一样,Mapper跑用户输入的map代码,Reduer跑用户输入的reduce代码。Master还作为管道负责中间路径传递,比如将Mapper生成的中间文件传递给Reduer,将Reduer生成的结果文件返回,或者传递给Combiner(如果有需要的话)。由于Master是单点,性能瓶颈,所以可以做集群:主备模式或者分布式模式。可以用zookeeper进行选主,用一些消息中间件进行数据同步。Master还可以进行一些策略处理:比如某个Worker执行时间特别长,很有可能卡住了,对分配给该Worker的数据重新分配给别的Worker执行,当然需要对多份数据返回去重处理。 Mapper:负责将输入数据切成key-value格式。Mapper处理完后,将中间文件的路径告知Master,Master获悉后传递给Reduer进行后续处理。如果Mapper未处理完,或者已经处理完但是Reduer未读完其中间输出文件,分配给该Mapper的输入将重新被别的Mapper执行。 Reducer: 接受Master发送的Mapper输出文件的消息,RPC读取文件并处理,并输出结果文件。n个Reduer将产生n个输出文件。 Combiner: 做最后的归并处理,通常不需要。
总的来说,架构不复杂。组件间通信用啥都可以,比如RPC、HTTP或者私有协议等。
2. 实现代码介绍
该版本代码实现了单机单进程版本,Mapper、Reducer和Combiner的实现用协程goroutine实现,通信采用channel。代码写的比较随意,没有解耦合。
功能:统计给定文件中出现的最高频的10个单词 输入:大文件 输出:最高频的10个单词 实现:5个Mapper协程、2个Reducer、1个Combiner。
为了方便起见,Combiner对最高频的10个单词进行堆排序处理,按规范来说应该放在用户程序处理。
文件目录如下,其中bin文件夹下的big_input_file.txt为输入文件,可以调用generate下的main文件生成,caller文件为入口的用户程序,master目录下分别存放master、mapper、reducer、combiner代码:
. ├── README.md ├── bin │ └── file-store │ └── big_input_file.txt └── src├── caller │ └── main.go ├── generate │ └── main.go └── master ├── combiner.go ├── mapper.go ├── master.go └── reducer.go 6 directories, 8 files
2.1 caller
用户程序,读入文件并按固定行数进行划分;然后调用master.Handle进行处理。
2.2 master
Master程序,依次生成Combiner、Reducer、Mapper,处理消息中转,输出最后结果。
2.3 mapper
Mapper程序,读入并按key-value格式生成中间文件,告知Master。
2.4 reducer
Reducer程序,读入Master传递过来的中间文件并归并。
package master import ( fmt bufio os strconv path strings github.com/vinllen/go-logger/logger ) func reducer(nr int, fileDir string) { mp := make(map[string]int) // store the frequence of words // read file and do reduce for { val, ok := <- ReduceChanIn if !ok { break } logger.Debug(reducer called: , nr) file, err := os.Open(val) if err != nil { errMsg := fmt.Sprintf(Read file(%s) error in reducer, val) logger.Error(errMsg) continue } scanner := bufio.NewScanner(file) for scanner.Scan() { str := scanner.Text() arr := strings.Split(str, ) if len(arr) != 2 { errMsg := fmt.Sprintf(Read file(%s) error that len of line(%s) != 2(%d) in reducer, val, str, len(arr)) logger.Warn(errMsg) continue } v, err := strconv.Atoi(arr[1]) if err != nil { errMsg := fmt.Sprintf(Read file(%s) error that line(%s) parse error in reduer, val, str) logger.Warn(errMsg) continue } mp[arr[0]] += v } if err := scanner.Err(); err != nil { logger.Error(reducer: reading standard input:, err) } file.Close() } outputFilename := path.Join(fileDir, reduce-output- + strconv.Itoa(nr)) outputFileHandler, err := os.Create(outputFilename) if err != nil { errMsg := fmt.Sprintf(Write file(%s) error in reducer(%d), outputFilename, nr) logger.Error(errMsg) } else { for k, v := range mp { str := fmt.Sprintf(%s %d\n, k, v) outputFileHandler.WriteString(str) } outputFileHandler.Close() } ReduceChanOut <- outputFilename }
2.5 combiner
Combiner程序,读入Master传递过来的Reducer结果文件并归并成一个,然后堆排序输出最高频的10个词语。
package master import ( fmt strings bufio os container/heap strconv github.com/vinllen/go-logger/logger ) type Item struct { key string val int } type PriorityQueue []*Item func (pq PriorityQueue) Len() int { return len(pq) } func (pq PriorityQueue) Less(i, j int) bool { return pq[i].val > pq[j].val } func (pq PriorityQueue) Swap(i, j int) { pq[i], pq[j] = pq[j], pq[i] } func (pq *PriorityQueue) Push(x interface{}) { item := x.(*Item) *pq = append(*pq, item) } func (pq *PriorityQueue) Pop() interface{} { old := *pq n := len(old) item := old[n - 1] *pq = old[0 : n - 1] return item } func combiner() { mp := make(map[string]int) // store the frequence of words // read file and do combine for { val, ok := <- CombineChanIn if !ok { break } logger.Debug(combiner called) file, err := os.Open(val) if err != nil { errMsg := fmt.Sprintf(Read file(%s) error in combiner, val) logger.Error(errMsg) continue } scanner := bufio.NewScanner(file) for scanner.Scan() { str := scanner.Text() arr := strings.Split(str, ) if len(arr) != 2 { errMsg := fmt.Sprintf(Read file(%s) error that len of line != 2(%s) in combiner, val, str) logger.Warn(errMsg) continue } v, err := strconv.Atoi(arr[1]) if err != nil { errMsg := fmt.Sprintf(Read file(%s) error that line(%s) parse error in combiner, val, str) logger.Warn(errMsg) continue } mp[arr[0]] += v } file.Close() } // heap sort // pq := make(PriorityQueue, len(mp)) pq := make(PriorityQueue, 0) heap.Init(&pq) for k, v := range mp { node := &Item { key: k, val: v, } // logger.Debug(k, v) heap.Push(&pq, node) } res := []Item{} for i := 0; i < 10 && pq.Len() > 0; i++ { node := heap.Pop(&pq).(*Item) res = append(res, *node) } CombineChanOut <- res }
3. 总结
不足以及未实现之处:
各模块间耦合性高 master单点故障未扩展 未采用多进程实现,进程间采用RPC通信 未实现单个Workder时间过长,另起Worker执行任务的代码。
接下来要是有空,我会实现分布式高可用的代码,模块间采用RPC通讯。
好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
上一篇:Go语言命令行操作命令详细介绍
下一篇:GO语言数组和切片实例详解
文章标题:golang如何实现mapreduce单进程版本详解
文章链接:http://soscw.com/index.php/essay/17500.html