标签:des style blog class code java
前言
本文讲解如何在VS 2010开发平台中搭建CUDA开发环境
当前配置:
系统:WIN7 64位
开发平台:VS 2010
显卡:英伟达G卡
CUDA版本:6.0
若配置不一样,请勿参阅本文。
第一步
点击这里下载
cuda最新版,目前最高版本是6.0。下载完毕后得到 cuda_6.0.37_winvista_win7_win8.1_general_64.exe
文件。
第二步
运行安装程序,弹出安装过程中转文件路径设定框:
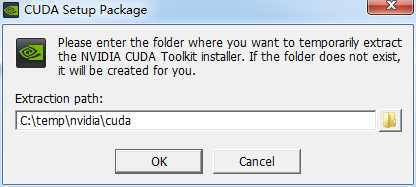
这个路径随便填无所谓,安装完后就会自动删除的,我就直接设置为默认的。
第三步
等待系统帮你检测当前平台是否适合搭建CUDA:
第四步
检测完毕后,正式进入CUDA安装界面:
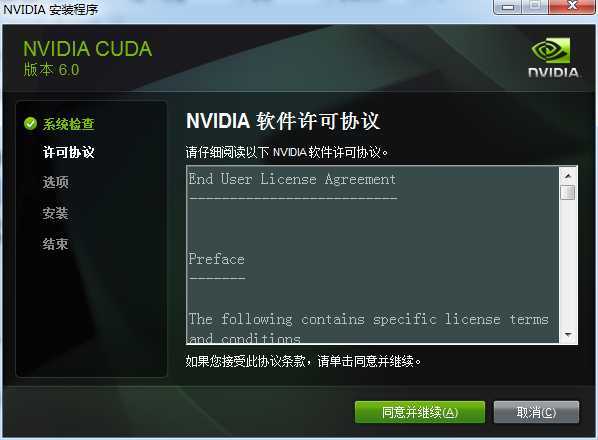
同意并继续
第五步
然后选择安装模式:
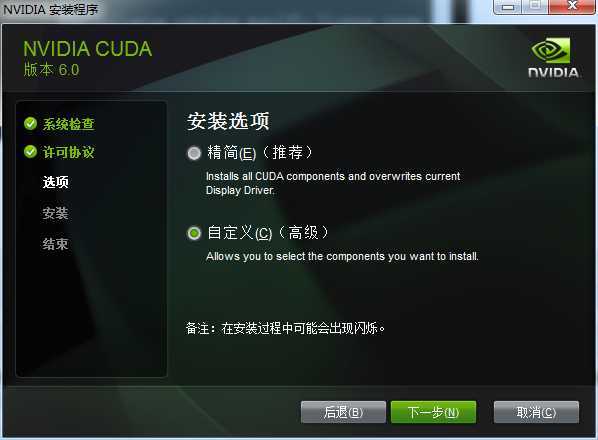
为了完全安装所有功能,选择自定义模式安装。
第六步
接下来勾选要安装的组件:
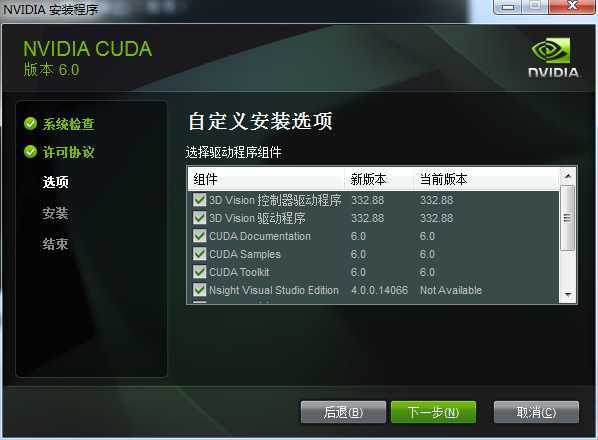
全部勾上
第七步
接下来要设置三个安装路径:
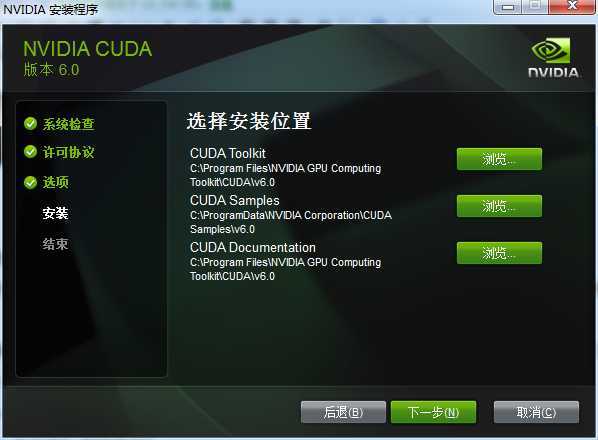
这三个路径安装的是什么在日后的文章中将会解释,目前先不理会,直接安装到默认路径。点击下一步之后开始正式安装。
第八步
安装完毕后,可以看到系统中多了CUDA_PATH和CUDA_PATH_V6_0两个环境变量,接下来,还要在系统中添加以下几个环境变量:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA
Samples\v6.0\common
CUDA_LIB_PATH = %CUDA_PATH%lib\x64
CUDA_BIN_PATH
= %CUDA_PATH%bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\x64
CUDA_SDK_LIB_PATH
= %CUDA_SDK_PATH%\common\lib\x64
然后,在系统变量末尾添加:
;%CUDA_LIB_PATH%;%CUDA_BIN_PATH%;%CUDA_SDK_LIB_PATH%;%CUDA_SDK_BIN_PATH%;
第九步
重新启动计算机以使环境变量生效
第十步
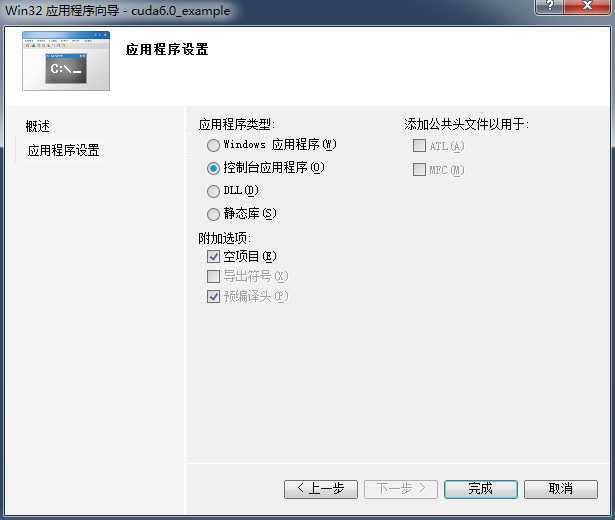
打开VS2010并建立一个空的win32控制台项目:
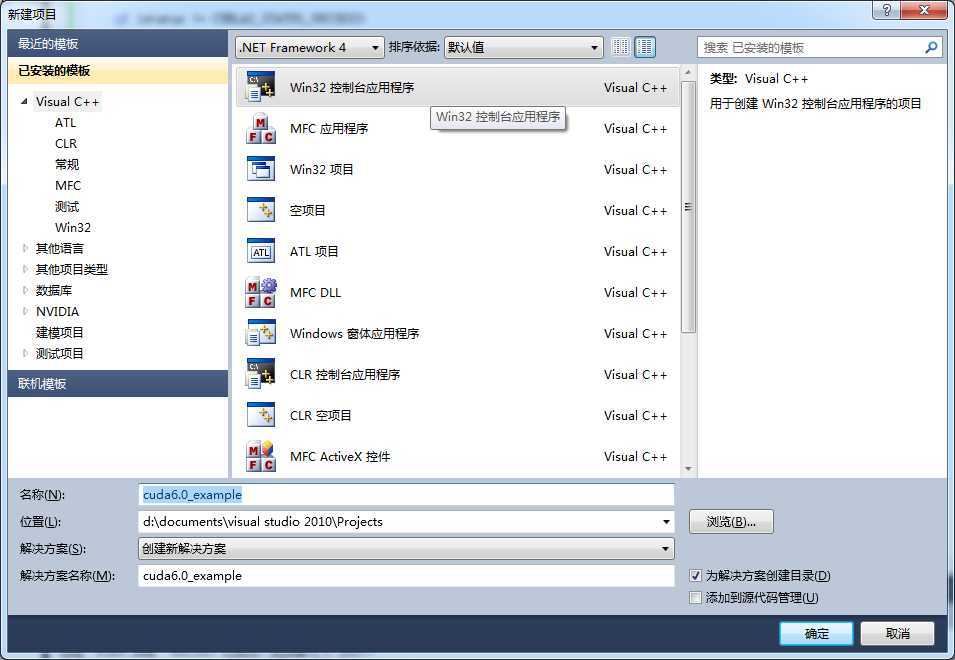
附加选项那里请把“空项目”打钩:
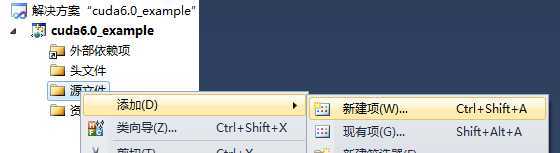
第十一步
右键源文件 -> 添加 -> 新建项
如下图所示:
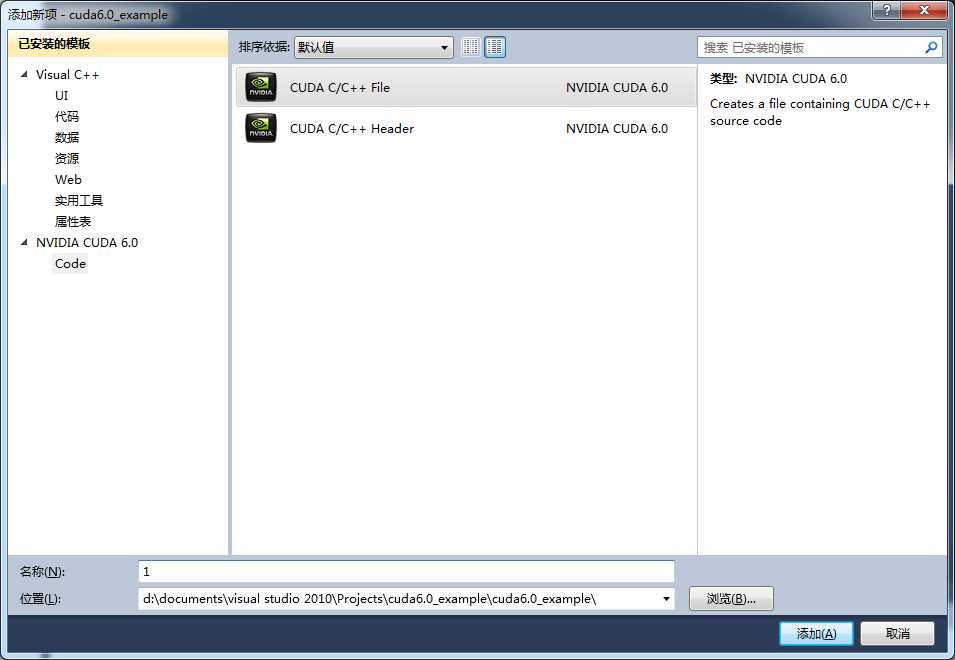
在打开的对话框中选择新建一个CUDA格式的源文件:
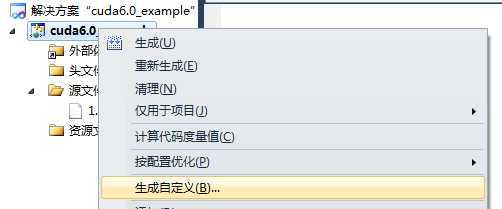
第十二步
右键工程 -> 生成自定义
如下图所示:
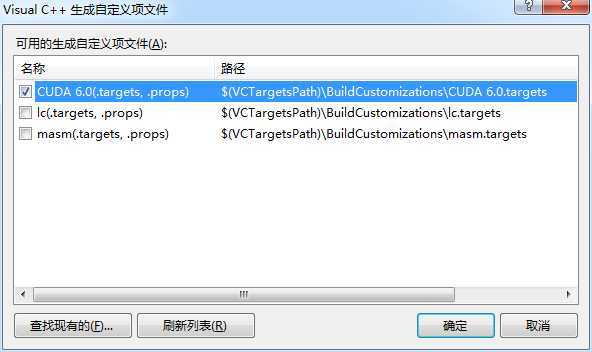
在弹出的对话框中勾选“CUDA 6.0
*****"选项:
第十三步
右键源代码文件 1.cu -> 属性
如下图所示:
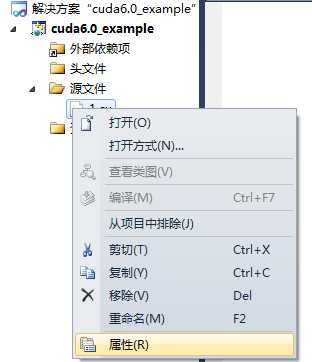
项类型选择 C/C++
编译器:

第十四步
右键项目 -> 属性 -> 配置属性 ->
VC++目录,添加以下两个包含目录:
C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v6.0\include
C:\ProgramData\NVIDIA Corporation\CUDA
Samples\v6.0\common\inc
再添加以下两个库目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v6.0\lib\x64
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v6.0\common\lib\x64
第十五步
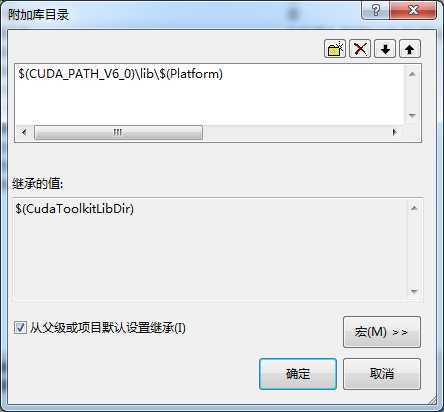
右键项目 -> 属性 -> 配置属性 ->连接器 -> 常规 -> 附加库目录,添加以下目录:
$(CUDA_PATH_V6_0)\lib\$(Platform)
如下图所示:
第十六步
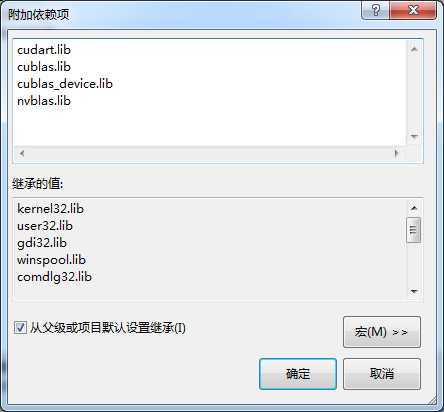
右键项目 -> 属性 -> 配置属性 ->连接器 -> 输入 -> 附加依赖项,添加以下库:
cudart.lib cublas.lib cublas_device.lib nvblas.lib
如下图所示:
第十七步
打开配置管理器,如下图所示:
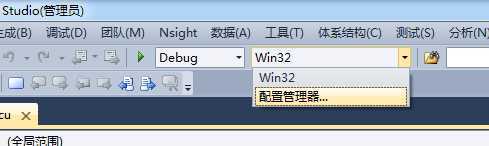
点击
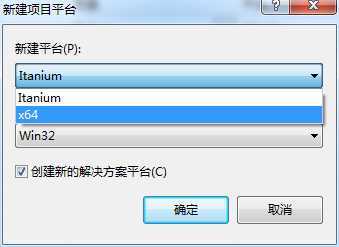
新建,如下图所示:
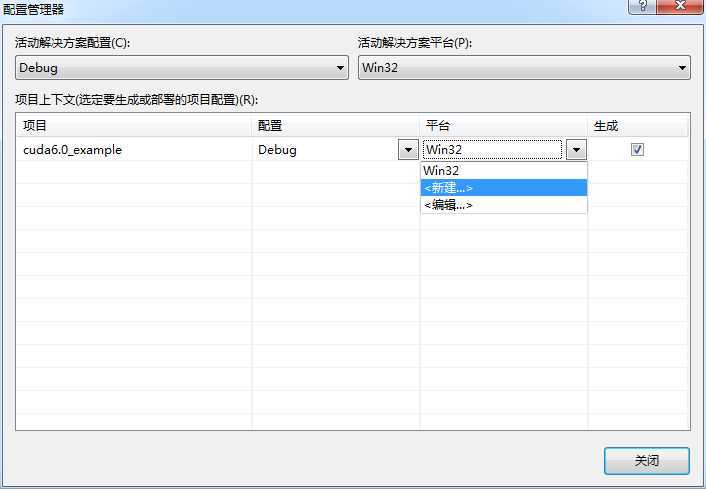
选择 X64
平台:
好了,至此平台已经完全搭建完毕,可用以下代码进行测试:

1 /* Includes, system */
2 #include 3 #include 4 #include string.h>
5
6 /* Includes, cuda */
7 #include 8 #include 9 #include 10
11 /* Matrix size */
12 #define N (275)
13
14 /* Host implementation of a simple version of sgemm */
15 static void simple_sgemm(int n, float alpha, const float *A, const float *B,
16 float beta, float *C)
17 {
18 int i;
19 int j;
20 int k;
21
22 for (i = 0; i i)
23 {
24 for (j = 0; j j)
25 {
26 float prod = 0;
27
28 for (k = 0; k k)
29 {
30 prod += A[k * n + i] * B[j * n + k];
31 }
32
33 C[j * n + i] = alpha * prod + beta * C[j * n + i];
34 }
35 }
36 }
37
38 /* Main */
39 int main(int argc, char **argv)
40 {
41 cublasStatus_t status;
42 float *h_A;
43 float *h_B;
44 float *h_C;
45 float *h_C_ref;
46 float *d_A = 0;
47 float *d_B = 0;
48 float *d_C = 0;
49 float alpha = 1.0f;
50 float beta = 0.0f;
51 int n2 = N * N;
52 int i;
53 float error_norm;
54 float ref_norm;
55 float diff;
56 cublasHandle_t handle;
57
58 int dev = findCudaDevice(argc, (const char **) argv);
59
60 if (dev == -1)
61 {
62 return EXIT_FAILURE;
63 }
64
65 /* Initialize CUBLAS */
66 printf("simpleCUBLAS test running..\n");
67
68 status = cublasCreate(&handle);
69
70 if (status != CUBLAS_STATUS_SUCCESS)
71 {
72 fprintf(stderr, "!!!! CUBLAS initialization error\n");
73 return EXIT_FAILURE;
74 }
75
76 /* Allocate host memory for the matrices */
77 h_A = (float *)malloc(n2 * sizeof(h_A[0]));
78
79 if (h_A == 0)
80 {
81 fprintf(stderr, "!!!! host memory allocation error (A)\n");
82 return EXIT_FAILURE;
83 }
84
85 h_B = (float *)malloc(n2 * sizeof(h_B[0]));
86
87 if (h_B == 0)
88 {
89 fprintf(stderr, "!!!! host memory allocation error (B)\n");
90 return EXIT_FAILURE;
91 }
92
93 h_C = (float *)malloc(n2 * sizeof(h_C[0]));
94
95 if (h_C == 0)
96 {
97 fprintf(stderr, "!!!! host memory allocation error (C)\n");
98 return EXIT_FAILURE;
99 }
100
101 /* Fill the matrices with test data */
102 for (i = 0; i )
103 {
104 h_A[i] = rand() / (float)RAND_MAX;
105 h_B[i] = rand() / (float)RAND_MAX;
106 h_C[i] = rand() / (float)RAND_MAX;
107 }
108
109 /* Allocate device memory for the matrices */
110 if (cudaMalloc((void **)&d_A, n2 * sizeof(d_A[0])) != cudaSuccess)
111 {
112 fprintf(stderr, "!!!! device memory allocation error (allocate A)\n");
113 return EXIT_FAILURE;
114 }
115
116 if (cudaMalloc((void **)&d_B, n2 * sizeof(d_B[0])) != cudaSuccess)
117 {
118 fprintf(stderr, "!!!! device memory allocation error (allocate B)\n");
119 return EXIT_FAILURE;
120 }
121
122 if (cudaMalloc((void **)&d_C, n2 * sizeof(d_C[0])) != cudaSuccess)
123 {
124 fprintf(stderr, "!!!! device memory allocation error (allocate C)\n");
125 return EXIT_FAILURE;
126 }
127
128 /* Initialize the device matrices with the host matrices */
129 status = cublasSetVector(n2, sizeof(h_A[0]), h_A, 1, d_A, 1);
130
131 if (status != CUBLAS_STATUS_SUCCESS)
132 {
133 fprintf(stderr, "!!!! device access error (write A)\n");
134 return EXIT_FAILURE;
135 }
136
137 status = cublasSetVector(n2, sizeof(h_B[0]), h_B, 1, d_B, 1);
138
139 if (status != CUBLAS_STATUS_SUCCESS)
140 {
141 fprintf(stderr, "!!!! device access error (write B)\n");
142 return EXIT_FAILURE;
143 }
144
145 status = cublasSetVector(n2, sizeof(h_C[0]), h_C, 1, d_C, 1);
146
147 if (status != CUBLAS_STATUS_SUCCESS)
148 {
149 fprintf(stderr, "!!!! device access error (write C)\n");
150 return EXIT_FAILURE;
151 }
152
153 /* Performs operation using plain C code */
154 simple_sgemm(N, alpha, h_A, h_B, beta, h_C);
155 h_C_ref = h_C;
156
157 /* Performs operation using cublas */
158 status = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A, N, d_B, N, &beta, d_C, N);
159
160 if (status != CUBLAS_STATUS_SUCCESS)
161 {
162 fprintf(stderr, "!!!! kernel execution error.\n");
163 return EXIT_FAILURE;
164 }
165
166 /* Allocate host memory for reading back the result from device memory */
167 h_C = (float *)malloc(n2 * sizeof(h_C[0]));
168
169 if (h_C == 0)
170 {
171 fprintf(stderr, "!!!! host memory allocation error (C)\n");
172 return EXIT_FAILURE;
173 }
174
175 /* Read the result back */
176 status = cublasGetVector(n2, sizeof(h_C[0]), d_C, 1, h_C, 1);
177
178 if (status != CUBLAS_STATUS_SUCCESS)
179 {
180 fprintf(stderr, "!!!! device access error (read C)\n");
181 return EXIT_FAILURE;
182 }
183
184 /* Check result against reference */
185 error_norm = 0;
186 ref_norm = 0;
187
188 for (i = 0; i i)
189 {
190 diff = h_C_ref[i] - h_C[i];
191 error_norm += diff * diff;
192 ref_norm += h_C_ref[i] * h_C_ref[i];
193 }
194
195 error_norm = (float)sqrt((double)error_norm);
196 ref_norm = (float)sqrt((double)ref_norm);
197
198 if (fabs(ref_norm) 7)
199 {
200 fprintf(stderr, "!!!! reference norm is 0\n");
201 return EXIT_FAILURE;
202 }
203
204 /* Memory clean up */
205 free(h_A);
206 free(h_B);
207 free(h_C);
208 free(h_C_ref);
209
210 if (cudaFree(d_A) != cudaSuccess)
211 {
212 fprintf(stderr, "!!!! memory free error (A)\n");
213 return EXIT_FAILURE;
214 }
215
216 if (cudaFree(d_B) != cudaSuccess)
217 {
218 fprintf(stderr, "!!!! memory free error (B)\n");
219 return EXIT_FAILURE;
220 }
221
222 if (cudaFree(d_C) != cudaSuccess)
223 {
224 fprintf(stderr, "!!!! memory free error (C)\n");
225 return EXIT_FAILURE;
226 }
227
228 /* Shutdown */
229 status = cublasDestroy(handle);
230
231 if (status != CUBLAS_STATUS_SUCCESS)
232 {
233 fprintf(stderr, "!!!! shutdown error (A)\n");
234 return EXIT_FAILURE;
235 }
236
237 exit(error_norm / ref_norm 1e-6f ? EXIT_SUCCESS : EXIT_FAILURE);
238 }
小结
不论什么开发环境的搭建,都应该确保自己电脑的硬件配置,软件版本和参考文档的一致,这样才能确保最短的时间内完成搭建,进入到具体的开发环节。
CUDA 6.0 安装及配置( WIN7 64位 / 英伟达G卡 / VS2010 ),搜素材,soscw.com
CUDA 6.0 安装及配置( WIN7 64位 / 英伟达G卡 / VS2010 )
标签:des style blog class code java
原文地址:http://www.cnblogs.com/scut-fm/p/3708723.html