[leetcode]LRU Cache @ Python
2020-11-24 05:53
标签:style blog class code java javascript ext width strong color get 原题地址:http://oj.leetcode.com/problems/lru-cache/ 题意:设计LRU Cache 参考文献:http://blog.csdn.net/hexinuaa/article/details/6630384 这篇博文总结的很到位。
https://github.com/Linzertorte/LeetCode-in-Python/blob/master/LRUCache.py
代码参考的github人写的,思路非常清晰,写的也很好。 Cache简介: Cache(高速缓存),
一个在计算机中几乎随时接触的概念。CPU中Cache能极大提高存取数据和指令的时间,让整个存储器(Cache+内存)既有Cache的高速度,又能有内存的大容量;操作系统中的内存page中使用的Cache能使得频繁读取的内存磁盘文件较少的被置换出内存,从而提高访问速度;数据库中数据查询也用到Cache来提高效率;即便是Powerbuilder的DataWindow数据处理也用到了Cache的类似设计。Cache的算法设计常见的有FIFO(first
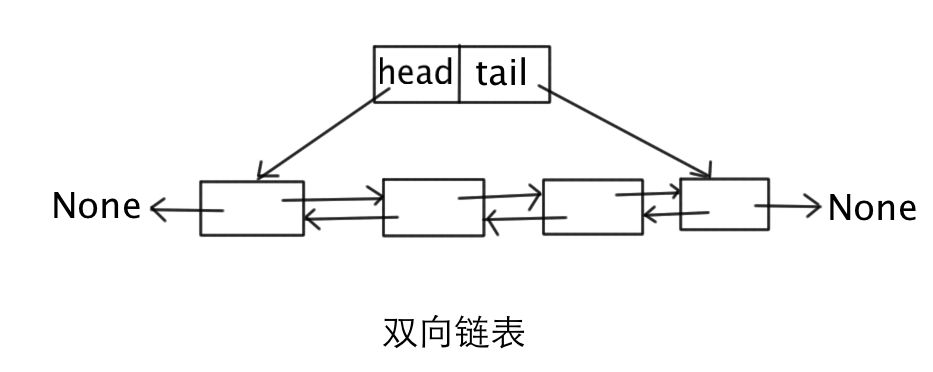
in first out)和LRU(least recently used)。根据题目的要求,显然是要设计一个LRU的Cache。 解题思路: Cache中的存储空间往往是有限的,当Cache中的存储块被用完,而需要把新的数据Load进Cache的时候,我们就需要设计一种良好的算法来完成数据块的替换。LRU的思想是基于“最近用到的数据被重用的概率比较早用到的大的多”这个设计规则来实现的。 为了能够快速删除最久没有访问的数据项和插入最新的数据项,我们双向链表连接Cache中的数据项,并且保证链表维持数据项从最近访问到最旧访问的顺序。每次数据项被查询到时,都将此数据项移动到链表头部(O(1)的时间复杂度)。这样,在进行过多次查找操作后,最近被使用过的内容就向链表的头移动,而没有被使用的内容就向链表的后面移动。当需要替换时,链表最后的位置就是最近最少被使用的数据项,我们只需要将最新的数据项放在链表头部,当Cache满时,淘汰链表最后的位置就是了。 注:
对于双向链表的使用,基于两个考虑。首先是Cache中块的命中可能是随机的,和Load进来的顺序无关。其次,双向链表插入、删除很快,可以灵活的调整相互间的次序,时间复杂度为O(1)。 梳理一下思路:对于Cache的每个数据块,我们设计一个数据结构来储存Cache块的内容,并实现一个双向链表,其中属性next和prev是双向链表的两个指针,key用于存储对象的键值,value用于存储cache块对象本身。 Cache的接口: 查询: 插入: 更新: 删除: 双向链表示意图: 代码: [leetcode]LRU Cache @ Python,搜素材,soscw.com [leetcode]LRU Cache @ Python 标签:style blog class code java javascript ext width strong color get 原文地址:http://www.cnblogs.com/zuoyuan/p/3701572.html
查找一个链表中元素的时间复杂度是O(n),每次命中的时候,我们就需要花费O(n)的时间来进行查找,如果不添加其他的数据结构,这个就是我们能实现的最高效率了。目前看来,整个算法的瓶颈就是在查找这里了,怎么样才能提高查找的效率呢?Hash表,对,就是它,数据结构中之所以有它,就是因为它的查找时间复杂度是O(1)。

class Node: #双向链表中节点的定义
def __init__(self,k,x):
self.key=k
self.val=x
self.prev=None
self.next=None
class DoubleLinkedList: #双向链表是一个表头,head指向第一个节点,tail指向最后一个节点
def __init__(self):
self.tail=None
self.head=None
def isEmpty(): #如果self.tail==None,那么说明双向链表为空
return not self.tail
def removeLast(self): #删除tail指向的节点
self.remove(self.tail)
def remove(self,node): #具体双向链表节点删除操作的实现
if self.head==self.tail:
self.head,self.tail=None,None
return
if node == self.head:
node.next.prev=None
self.head=node.next
return
if node ==self.tail:
node.prev.next=None
self.tail=node.prev
return
node.prev.next=node.next
node.next.prev=node.prev
def addFirst(self,node): #在双向链表的第一个节点前面再插入一个节点
if not self.head:
self.head=self.tail=node
node.prev=node.next=None
return
node.next=self.head
self.head.prev=node
self.head=node
node.prev=None
class LRUCache:
# @param capacity, an integer
def __init__(self, capacity): #初始化LRU Cache
self.capacity=capacity #LRU Cache的容量大小
self.size=0 #LRU Cache目前占用的容量
self.P=dict() #dict为文章中提到的hashmap,加快搜索速度,{key:对应节点的地址}
self.cache=DoubleLinkedList()
# @return an integer
def get(self, key): #查询操作
if (key in self.P) and self.P[key]: #如果key在字典中
self.cache.remove(self.P[key]) #将key对应的指针指向的节点删除
self.cache.addFirst(self.P[key]) #然后将这个节点添加到双向链表头部
return self.P[key].val #并返回节点的value
else: return -1
# @param key, an integer
# @param value, an integer
# @return nothing
def set(self, key, value): #设置key对应的节点的值为给定的value值
if key in self.P: #如果key在字典中
self.cache.remove(self.P[key]) #先删掉key对应的节点
self.cache.addFirst(self.P[key]) #然后将这个节点插入到表的头部
self.P[key].val=value #将这个节点的值val改写为value
else: #如果key不在字典中
node=Node(key,value) #新建一个Node节点,val值为value
self.P[key]=node #将key和node的对应关系添加到字典中
self.cache.addFirst(node) #将这个节点添加到链表表头
self.size +=1 #容量加1
if self.size > self.capacity: #如果链表的大小超过了缓存的大小,删掉最末尾的节点,
self.size -=1 #并同时删除最末尾节点key值和末节点在字典中的对应关系
del self.P[self.cache.tail.key]
self.cache.removeLast()
文章标题:[leetcode]LRU Cache @ Python
文章链接:http://soscw.com/index.php/essay/22331.html