C语言中的函数
2020-11-24 16:53
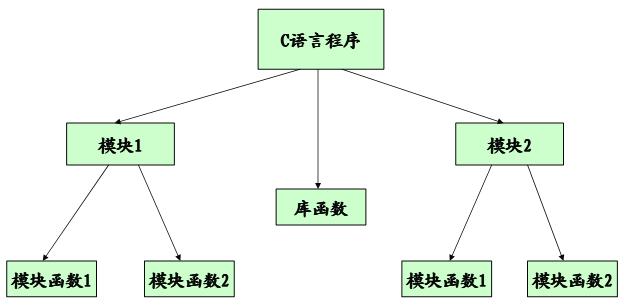
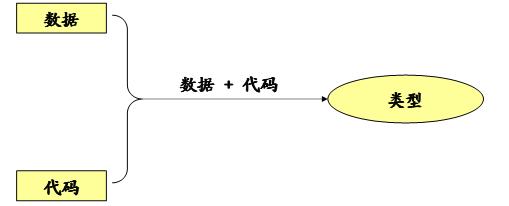
标签:c 函数 一、认清函数的真相 1、函数的由来 程序 = 数据 + 算法 C程序 = 数据 + 函数 2、函数的意义 模块化程序设计 C语言中的模块化 3、面向过程的程序设计 # 面向过程是一种以过程为中心的编程思想 # 首先将复杂问题分解为一个个容易解决的问题 # 分解过后的问题可以按照步骤一步步完成 # 函数是面向过程在C语言中的体现 # 解决问题的每一个步骤可以用函数来实现 3、声明和定义 # 程序中的声明可以理解为预先告诉编译器实体的存在,如:变量,函数,等等 # 程序中的定义明确指示编译器实体的意义 声明和定义并不相同!!! 实例: // global.c
void f(int i, int j); //声明一个外部函数
int main()
void f(int i, int j) // 定义
int g(int x) # 函数参数在本质上与局部变量相同,都是在栈上分配空间 # 函数参数的初始值是函数调用时的实参值
int f(int i, int j)
int main()
int main()
float func(int array[], int size)
int main()
float average(int n, ...)
int main()
void reset(void* p, int len)
int main()
#define ADD(a, b) a + b
int main()
int add(int a, int b)
int mul(int a, int b)
int _min_(int a, int b)
int main()
int func(int x)
int main()
struct Student
int main()
int main()
struct Student
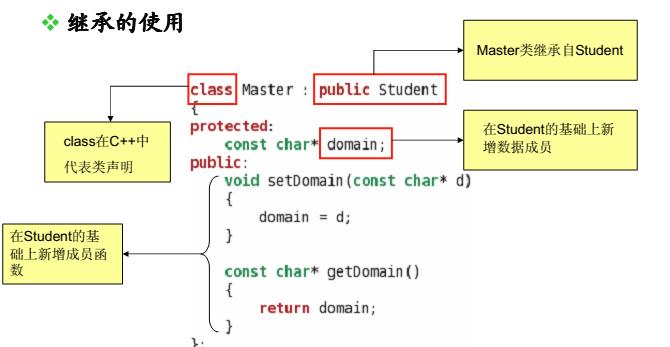
class Master : public Student
int main() C语言中的函数 标签:c 函数 原文地址:http://blog.csdn.net/renren900207/article/details/24668283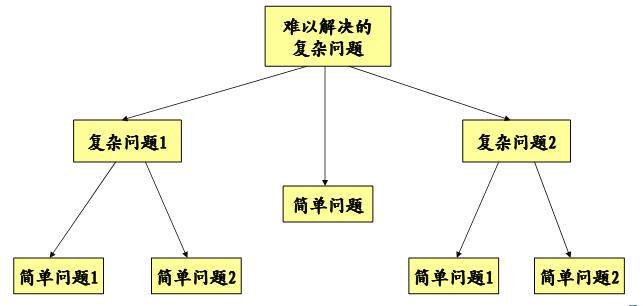
// int g_var = 0; // 定义
#include
extern int g_var; //声明一个外部变量
{
int g(int x);
g_var = 10;
f(1, 2);
printf("%d\n", g(3));
return 0;
}
{
printf("i + j = %d\n", i + j);
}
{
return 2 * x + g_var;
}
4、函数参数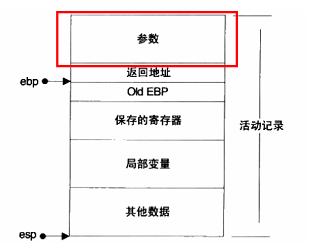
{
printf("%d, %d\n", i, j);
}
{
int k = 1;
f(k, k++);
printf("%d\n", k);
return 0;
}
函数参数的求值顺序依赖于编译器的实现!!!
{
int k = 2;
int a = 1;
k = k++ + k++;
printf("k = %d\n", k);
if( a-- && a )
{
printf("a = %d\n", a);
}
return 0;
}
函数的缺省认定
int f(int i, int j)
{
int i = 0;
float avr = 0;
for(i=0; i
avr += array[i];
}
return avr / size;
}
{
int array[] = {1, 2, 3, 4, 5};
printf("%f\n", func(array, 5));
return 0;
}
1、可变参数
#include
{
va_list args; //专用类型,可变列表
int i = 0;
float sum = 0;
va_start(args, n);//初始化列表
for(i=0; i
sum += va_arg(args, int);
}
va_end(args); //结束列表
return sum / n;
}
{
printf("%f\n", average(5, 1, 2, 3, 4, 5));
printf("%f\n", average(4, 1, 2, 3, 4));
return 0;
}
2、可变参数的限制
warning:va_arg如果指定了错误的类型,那么结果是不可预测的。
小结:
#define RESET(p, len) while( len > 0) ((char*)p)[--len] = 0
{
while( len > 0 )
{
((char*)p)[--len] = 0;
}
}
{
int array[] = {1, 2, 3, 4, 5};
int len = sizeof(array);
reset(array, len);
RESET(array, len);
return 0;
}
4、函数 VS 宏
#include
#define MUL(a, b) a * b
#define _MIN_(a, b) ((a)
{
int i = 1;
int j = 10;
printf("%d\n", MUL(ADD(1, 2), ADD(3, 4)));//宏的副作用
printf("%d\n", _MIN_(i++, j));
return 0;
}
{
return a + b;
}
{
return a * b;
}
{
return a
}
{
int i = 1;
int j = 10;
printf("%d\n", mul(add(1, 2), add(3, 4)));
printf("%d\n", _min_(i++, j));
return 0;
}
宏无可替代的优势
小结:
{
if( x > 1 )
{
return x * func(x - 1);
}
else
{
return 1;
}
}
{
printf("x! = %d\n", func(4));
return 0;
}
递归的一大优点就是它非常符合我们的思考方式。
函数设计技巧

{
const char* name;
int number;
void info()
{
printf("Name = %s, Number = %d\n", name, number);
}
};
{
Student s;
s.name = "Delphi";
s.number = 100;
s.info();
return 0;
}
struct Student
{
protected:
const char* name;
int number;
public:
void set(const char* n, int i)
{
name = n;
number = i;
}
void info()
{
printf("Name = %s, Number = %d\n", name, number);
}
};
{
Student s;
s.set("Delphi", 100);
s.info();
return 0;
}
{
protected:
const char* name;
int number;
public:
void set(const char* n, int i)
{
name = n;
number = i;
}
void info()
{
printf("Name = %s, Number = %d\n", name, number);
}
};
{
protected:
const char* domain;
public:
void setDomain(const char* d)
{
domain = d;
}
const char* getDomain()
{
return domain;
}
};
{
Master s;
s.set("Delphi", 100);
s.setDomain("Software");
s.info();
printf("Domain = %s\n", s.getDomain());
return 0;
}