用Python爬取28010条《隐秘的角落》评论,有没发现点什么?
2020-12-24 15:27
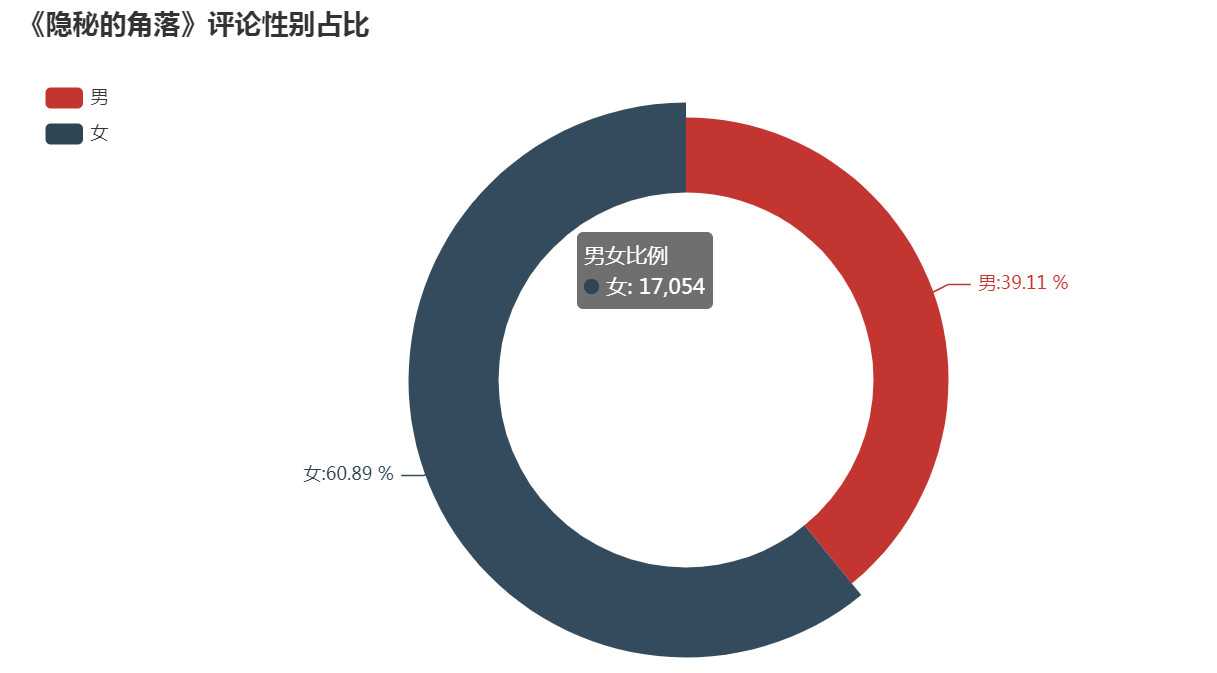
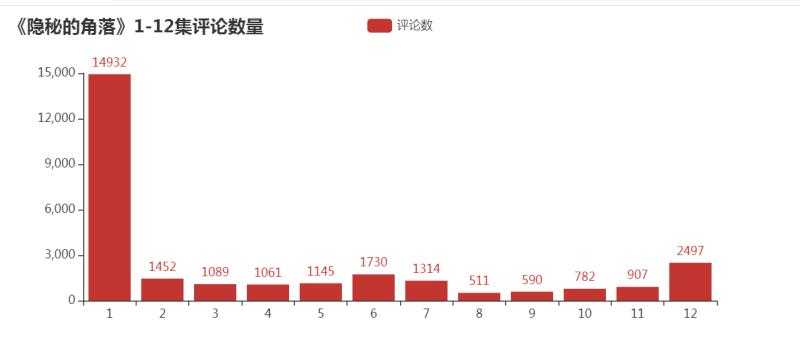
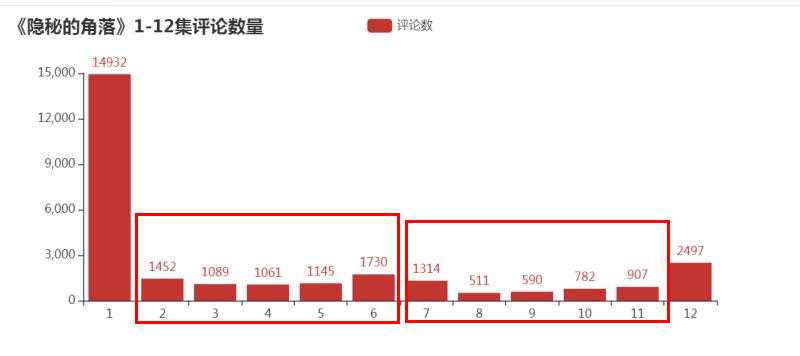
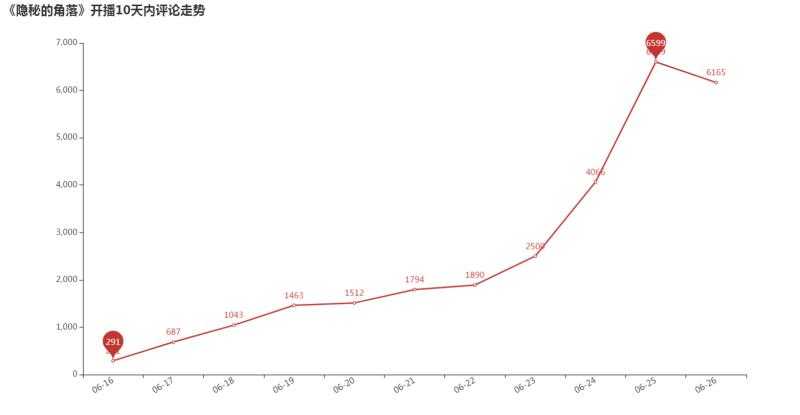
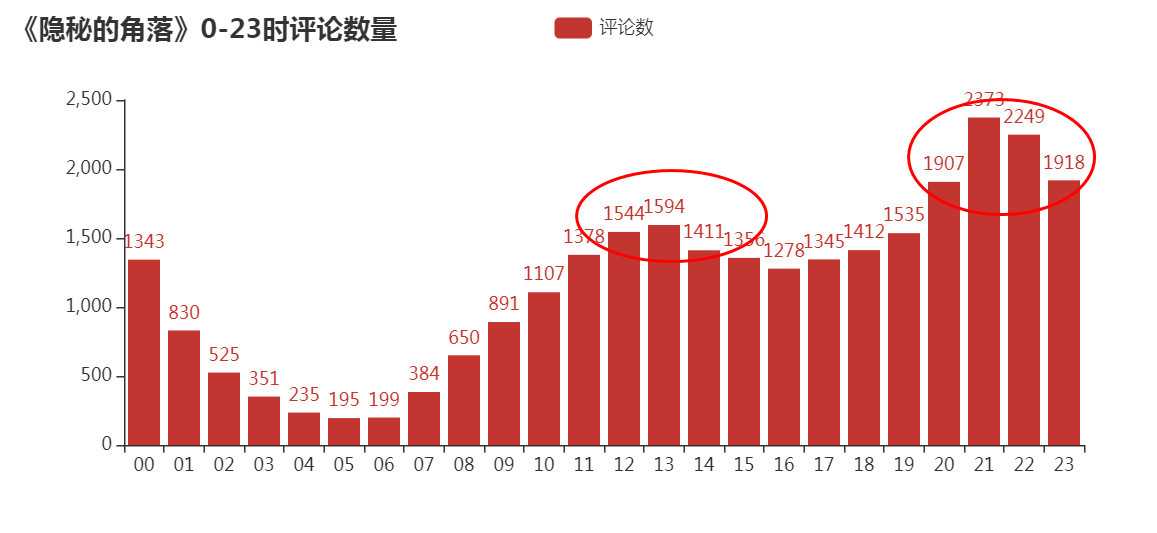
标签:poi 展示 有一个 == 滑动 词云 array mask alt “一起去爬山吧?” 这句台词火爆了整个朋友圈,没错,就是来自最近热门的《隐秘的角落》,豆瓣评分8.9分,好评不断。 永恒君趁着端午的假期也赶紧刷完了这部剧,感觉还是蛮不错的。同时,为了想更进一步了解一下小伙伴观剧的情况,永恒君抓取了爱奇艺平台评论数据并进行了分析。下面来做个分享,给大伙参考参考。 因为该剧是在爱奇艺平台独播的,自然数据源从这里取比较合适。永恒君爬取了 使用 Chrome 查看源代码模式,在播放页面往下面滑动,有一个 get_comments 的请求,经过调试分析,这个接口就是获取评论数据的接口,后面连接上一系列的参数即可获取评论的数据。 其中关键的就是 爬虫部分代码 最终将12集爬取下来的包含评论数据的json源码保存到txt文件当中,解析提取评论的时间、用户名、性别、评论内容等信息,经过去重、去空白等数据清理工作,最终获得28010条评论信息。 在海量的数据中,我们可以分析出我们想看到的结果。为了更好的数据处理和可视化展示,这里永恒君用了Pandas和Pyecharts 这两个库。 女生占了大部分,占比60.89%,比男性用户要多不少。 接下来,我们再来看一下,每一期的评论数量,看是否能够得出一些不一样的数据。 除了第一集的评论数特别多之外,可以看到,上半段的评论数明显要比下半段的要多,是否意味着大家普遍觉得前期的要更好看一些? 接下来我们来看看从6月16日开播之后,网友们对该剧的评论数量走势情况。 可以看到,从6月16日开播后,评论数量一路走高在6月25日达到了一个阶段的高点。 通过统计16日-26日每日0-23时的评论数量,来看看大家一般都在什么时候看剧 可以看到,晚上20点-23时为最集中看剧的时间段,其次中午12-14点也有一波小高峰,总体更多的人是下午看剧的人多。 这是否也是你看剧的时间段呢? 永恒君一般看剧基本都不写评论的或者也是简单几个字,但是在这里,我特地看了一下评论字数的分布, 绝大部分的评论字数都是在10个字以内,但也有约25%的评论字数在10-30个之内,还是让永恒君有点意外,是否说明该剧火爆也是有原因的,激起了不少伙伴的共鸣。 最后,永恒君将通过wordcloud库制作词云来看看,大家对该剧的整体评价,以及该剧的核心关键词。 可以看到,“朝阳”、“严良”、“张东升”、“普普”、“好看”、“喜欢”、“小孩”、“原著”等关键词都是大伙在热议的。 不得不说,近年来如此火热的、而且质量不错的国产剧确实不多了。永恒君看前几集的时候,突然又有大学时候看《越狱》的那个味道,看了一集就想看下一集,停不下来。 如果你现在还没有来得及看,建议抽个时间去看看吧~~~ 用Python爬取28010条《隐秘的角落》评论,有没发现点什么? 标签:poi 展示 有一个 == 滑动 词云 array mask alt 原文地址:https://www.cnblogs.com/eternalpal/p/13210710.html
1、爬取评论数据
《隐秘的角落》12集的从开播日6月16日-6月26日的评论数据。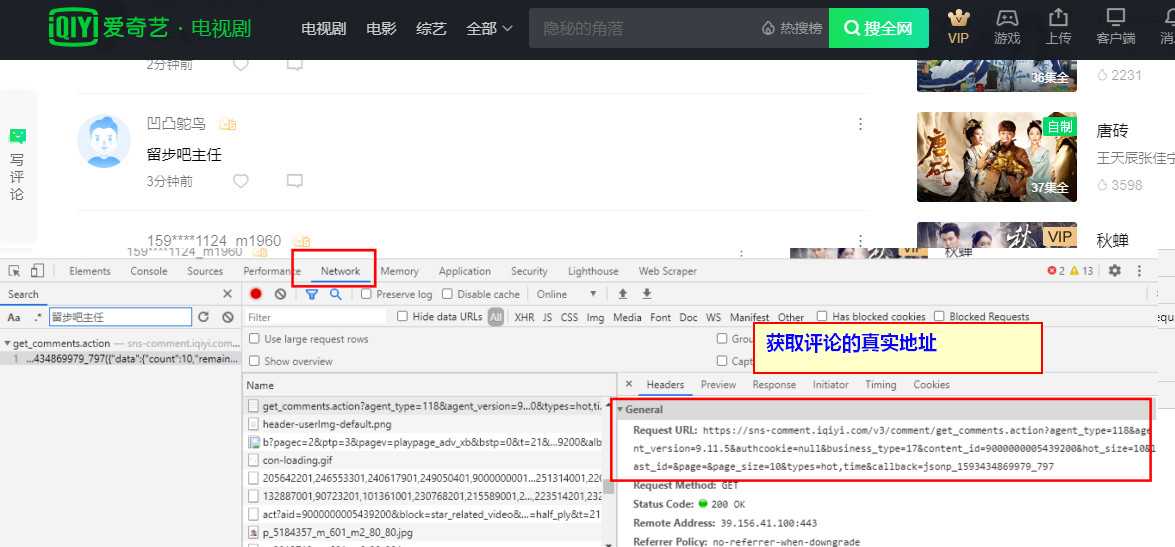
last_id这个参数,是用来控制评论分页的,需要通过上一个页面最后一条评论的id来进行获取。def get_comment_html(movieId, movieName, lastId):#将获取评论的json源码,保存到txt文件中
url = "http://sns-comment.iqiyi.com/v3/comment/get_comments.action?"
params = {
"types":"time",
"business_type":"17",
"agent_type":"118",
"agent_version":"9.11.5",
"authcookie":"authcookie"
}
for item in params:
url = url + item + "=" + params[item] + "&"
url = url + "content_id=" + movieId+ "&last_id=" + lastId
#url 为拼接好的评论地址
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"Accept": "application/json, text/javascript",
"Referer": "https://www.iqiyi.com/v_19rxtiliso.html?vfm=2008_aldbd&fv=p_02_01",
}
response = requests.get(url, headers=headers)
filename = movieId + movieName+".txt"
if response.status_code == 200:
with open(filename,"a",encoding=‘utf-8‘) as f:
f.write(response.text+"\n")
#将获取的评论json源码保存到txt文件,一次写入一行,表示获取的这一页的评论
else:
print("request error")
print("爬取第{}页评论".format(file_lines(filename)))
time.sleep(0.5)
last_id = parseData(response.text) #解析并获取下一个id
if last_id != "End":
get_comment_html(movieId, movieName, parseData(response.text))
else:
print("已到结尾")
#continue#结束整个程序
return None
2、分析展示数据
1)评论用户性别方面
2)每一集的评论数量
from pyecharts.charts import Bar ##导入需要使用的图表
from pyecharts import options as opts ##导入配置项
comment_num3 = df["集数"].value_counts().sort_index()
x_line3 = comment_num3.index.to_list()
y_line3 = comment_num3.values.tolist()
bar1=(
Bar(init_opts=opts.InitOpts(width=‘800px‘, height=‘350px‘)) ##定义为柱状图
.add_xaxis(x_line3) ##X轴的值
.add_yaxis(‘评论数‘,y_line3) ##y的值和y的一些数据配置项
.set_global_opts(title_opts=opts.TitleOpts(title=‘《隐秘的角落》1-12集评论数量‘))
)
bar1.render("bar3.html") ###输出html文件
3)开播十天之内的评论数量走势
from pyecharts.charts import Line ##导入需要使用的图表
from pyecharts import options as opts ##导入配置项
comment_num = df["留言时间"].str.split(‘ ‘).str[0].value_counts().sort_index()
x_line1 = [i.replace(‘2020-‘,‘‘) for i in comment_num.index.to_list()]
y_line1 = comment_num.values.tolist()
# 绘制面积图
line1 = Line(init_opts=opts.InitOpts(width=‘1200px‘, height=‘600px‘))
line1.add_xaxis(x_line1)
line1.add_yaxis(‘‘, y_line1,
markpoint_opts=opts.MarkPointOpts(data=[
opts.MarkPointItem(type_=‘max‘, name=‘最大值‘),
opts.MarkPointItem(type_=‘min‘, name=‘最小值‘)
]))
line1.set_global_opts(title_opts=opts.TitleOpts(‘《隐秘的角落》开播10天内评论走势‘),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=‘30‘)),
#visualmap_opts=opts.VisualMapOpts(max_=12673)
)
line1.set_series_opts(label_opts=opts.LabelOpts(is_show=True),
linestyle_opts=opts.LineStyleOpts(width=2))
line1.render("Line.html")
4)一天之中大家都在什么时间段看这部剧?
from pyecharts.charts import Bar ##导入需要使用的图表
from pyecharts import options as opts ##导入配置项
comment_num2 = df["留言时间"].str.split(‘ ‘).str[1].str.split(":").str[0].value_counts().sort_index()
x_line2 = comment_num2.index.to_list()
y_line2 = comment_num2.values.tolist()
bar1=(
Bar(init_opts=opts.InitOpts(width=‘800px‘, height=‘350px‘)) ##定义为柱状图
.add_xaxis(x_line2) ##X轴的值
.add_yaxis(‘评论数‘,y_line2) ##y的值和y的一些数据配置项
.set_global_opts(title_opts=opts.TitleOpts(title=‘《隐秘的角落》0-23时评论数量‘))
)
bar1.render("bar2.html") ###输出html文件
5)评论的字数情况
def comment_word_group(strings): #评论字数分组函数
if len(strings) 10 and len(strings)30 and len(strings) 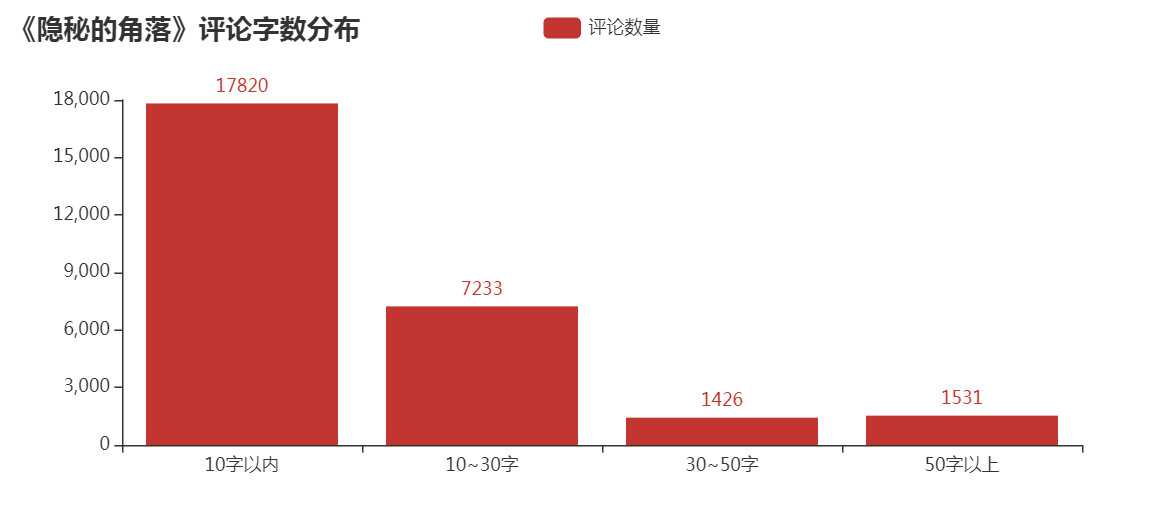
6)评论核心关键词
#词云
from PIL import Image
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS
import jieba
import matplotlib.pyplot as plt
import numpy as np
contents = df["留言内容"].str.cat(sep=" ")
contents
sw = set(STOPWORDS)
sw.add("这个")
sw.add("什么")
cut_text2 = " ".join(jieba.lcut(contents))
background_image = np.array(Image.open("bg.png"))
wc = WordCloud(font_path=r‘C:\Windows\Fonts\simhei.ttf‘,
background_color=‘White‘,
max_words=3000,
width=1000,
height=500,
scale=1,
stopwords=sw,#停用词
mask = background_image
)
#font_path:设置字体,max_words:出现的最多词数量,mask参数=图片背景,必须要写上,另外有mask参数再设定宽高是无效的
wc.generate(cut_text2)
wc.to_file("a2.jpg")
#将图绘制出来
plt.imshow(wc)
plt.axis("off")
plt.show()

上一篇:部署IIS调试WebApi
下一篇:【python】冒泡排序
文章标题:用Python爬取28010条《隐秘的角落》评论,有没发现点什么?
文章链接:http://soscw.com/index.php/essay/37944.html