Handtrack.js 开源:3行JS代码搞定手部动作跟踪
2020-12-24 16:28
标签:环境 如何 提高 org top png 开源 托管 经验 你可以直接在 script 标签中包含这个库的 URL 地址,或者使用构建工具从 npm 中导入它。 在将上面的 script 标签添加到 html 页面后,就可以使用 handTrack 变量引用 handtrack.js,如下所示。 上面的代码段将打印出通过 img 标签传入的图像的预测边框,如果换了视频或通过摄像头提交图像帧,那么就可以“跟踪”在每一帧中出现的手。 使用 handtrack.js 跟踪图像中的手,你可以调用 renderPredictions() 方法在 canvas 对象中绘制检测到的边框和源图像。 你可以使用以下命令将 handtrack.js 作为 npm 包来安装: 下面给出了如何在 React 应用程序中导入和使用它的示例。 Handtrack.js 提供了几种方法。两个主要的方法是 load() 和 detect(),分别用于加载手部检测模型和获取预测结果。 预测结果格式如下: Handtrack.js 还提供了其他辅助方法: 浏览器是单线程的:所以必须确保预测操作不会阻塞 UI 线程。每个预测可能需要 50 到 150 毫秒,所以用户会注意到这个延迟。在将 Handtrack.js 集成到每秒需要多次渲染整个屏幕的应用程序中时(例如游戏),我发现有必要减少每秒的预测数量。 Handtrack.js 代表了新形式 AI 人机交互的早期阶段。在浏览器方面已经有一些很好的想法,例如用于人体姿势检测的 posenet: Handtrack.js 开源:3行JS代码搞定手部动作跟踪 标签:环境 如何 提高 org top png 开源 托管 经验 原文地址:https://blog.51cto.com/15057848/2567668
作者|Victor Dibia
译者|薛命灯
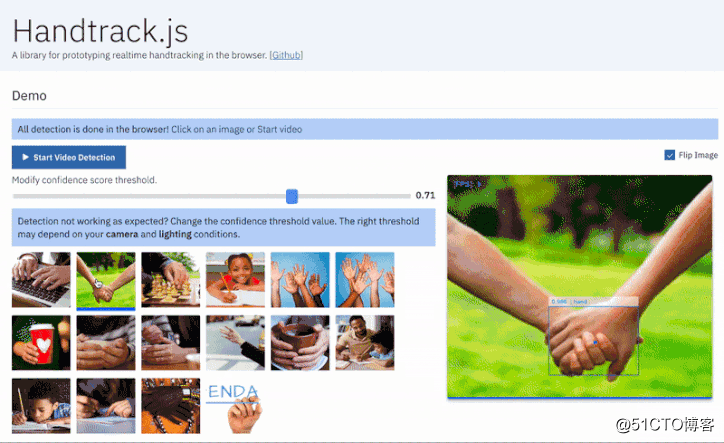
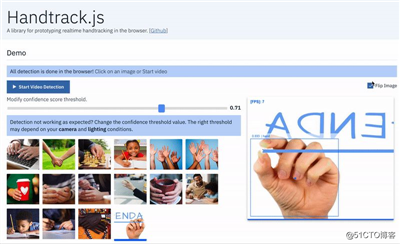
近日,GitHub 上开源了一个名为 Handtrack.js 的项目,有了它,你只需要 3 行代码就能用来检测图片中手的动作。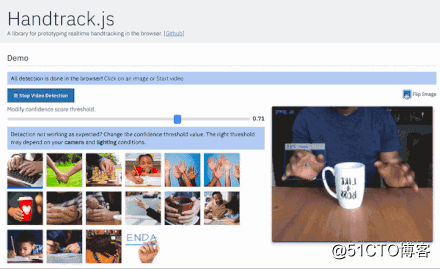
演示地址:https://victordibia.github.io/handtrack.js/#/
运行时:22 FPS,Macbook Pro 2018(2.5 Ghz),Chrome 浏览器。13FPS,Macbook Pro 2014(2.2GHz)。
不久之前,一个使用 TensorFlow 对象检测 API 跟踪图片中手部动作的实验结果把我震惊到了。我把训练模型和源代码开放了出来:https://github.com/victordibia/handtracking
%E4%BB%8E%E9%82%A3%E6%97%B6%E8%B5%B7%EF%BC%8C%E5%AE%83%E5%B0%B1%E8%A2%AB%E7%94%A8%E6%9D%A5%E5%BC%80%E5%8F%91%E4%B8%80%E4%BA%9B%E9%9D%9E%E5%B8%B8%E6%9C%89%E8%B6%A3%E7%9A%84%E4%B8%9C%E8%A5%BF%EF%BC%8C%E6%AF%94%E5%A6%82%EF%BC%9A
%E4%B8%80%E4%B8%AA%E5%8F%AF%E4%BB%A5%E5%B8%AE%E5%8A%A9%E5%AD%A9%E5%AD%90%E8%BF%9B%E8%A1%8C%E6%8B%BC%E5%86%99%E7%BB%83%E4%B9%A0%E7%9A%84%E5%B7%A5%E5%85%B7%EF%BC%9A
https://medium.com/@drewgillson/alphabot-a-screen-less-interactive-spelling-primer-powered-by-computer-vision-cc1095bce90
br/>https://github.com/victordibia/handtracking
从那时起,它就被用来开发一些非常有趣的东西,比如:
一个可以帮助孩子进行拼写练习的工具:
https://medium.com/@drewgillson/alphabot-a-screen-less-interactive-spelling-primer-powered-by-computer-vision-cc1095bce90
一个可以识别手势的插件:
https://github.com/MrEliptik/HandPose
一个乒乓球游戏:
https://github.com/alvinwan/hand-tracking-pong
有很多人想要尝试我提供的训练模型,但无法设置好 Tensorflow(安装问题、TF 版本问题、导出图表,等等)。幸运的是,Tensorflow.js 解决了其中的一些安装和发行问题,因为它经过优化,可以在浏览器的标准化环境中运行。为此,我创建了 Handtrack.js 库:
https://github.com/victordibia/handtrack.js/
它可以让开发人员使用经过训练的手部检测模型快速创建手势交互原型。
这个库的目标是隐藏与加载模型文件相关的步骤,为用户提供有用的函数,并允许用户在没有任何 ML 经验的情况下检测图像中的手,你不需要自己训练模型。
你也无需导出任何图或已保存的模型。你可以直接在 Web 应用程序中包含 handtrack.js(详情如下),然后调用这个库提供的方法。如何在 Web 应用程序中使用它?
使用 script 标签
Handtrack.js 的最小化 js 文件目前托管在 jsdelivr 上,jsdelivr 是一个免费的开源 CDN,让你可以在 Web 应用程序中包含任何的 npm 包。const img = document.getElementById(‘img‘);
handTrack.load().then(model => {
model.detect(img).then(predictions => {
console.log(‘Predictions: ‘, predictions) // bbox predictions
});
});
使用 NPM
npm install --save handtrackjsimport * as handTrack from ‘handtrackjs‘;
const img = document.getElementById(‘img‘);
// Load the model.
handTrack.load().then(model => {
// detect objects in the image.
console.log("model loaded")
model.detect(img).then(predictions => {
console.log(‘Predictions: ‘, predictions);
});
});
Handtrack.js 的 API
load() 方法接受可选的模型参数,允许你控制模型的性能。这个方法以 webmodel 格式(也托管在 jsdelivr 上)加载预训练的手部检测模型。
detect() 方法接受输入源参数(img、video 或 canvas 对象)并返回图像中手部位置的边框预测结果。const modelParams = {
flipHorizontal: true, // flip e.g for video
imageScaleFactor: 0.7, // reduce input image size .
maxNumBoxes: 20, // maximum number of boxes to detect
iouThreshold: 0.5, // ioU threshold for non-max suppression
scoreThreshold: 0.79, // confidence threshold for predictions.
}
const img = document.getElementById(‘img‘);
handTrack.load(modelParams).then(model => {
model.detect(img).then(predictions => {
console.log(‘Predictions: ‘, predictions);
});
});[{
bbox: [x, y, width, height],
class: "hand",
score: 0.8380282521247864
}, {
bbox: [x, y, width, height],
class: "hand",
score: 0.74644153267145157
}]
库大小和模型大小
库大小为 810 KB,主要是因为它与 tensorflow.js 库捆绑在一起(最新版本存在一些未解决的问题)。
模型大小为 18.5 MB,在初始加载页面时需要等待一会儿。TF.js 模型通常分为多个文件(在本例中为四个 4.2 MB 的文件和一个 1.7 MB 的文件)。
工作原理
Handtrack.js 使用了 Tensorflow.js 库,一个灵活而直观的 API,用于在浏览器中从头开始构建和训练模型。它提供了一个低级的 JavaScript 线性代数库和一个高级的层 API。
创建 Handtrack.js 库

创建基于 Tensorflow.js 的 JavaScript 库的步骤
数据汇编
这个项目中使用的数据主要来自 Egohands 数据集(http://vision.soic.indiana.edu/projects/egohands/)。其中包括 4800 张人手的图像,带有边框,使用谷歌眼镜捕获。
模型训练
使用 Tensorflow 对象检测 API 训练模型。对于这个项目,我们使用了 Single Shot MultiBox Detector(https://arxiv.org/abs/1512.02325)和 MobileNetV2 架构(https://arxiv.org/abs/1801.04381)。然后将训练好的模型导出为 savedmodel。
模型转换
Tensorflow.js 提供了一个模型转换工具,可以用它将 savedmodel 转换为可以在浏览器中加载的 webmodel 格式。最后,在转换过程中删除了对象检测模型图的后处理部分。这个优化可以让检测和预测操作的速度加倍。
库的包装和托管
这个库由一个主类组成,这个类提供了一些用于加载模型、检测图像的方法以及一组其他有用的函数,例如 startVideo、stopVideo、getFPS()、renderPredictions()、getModelParameters()、setModelParameters(),等等。方法的完整描述可以在 Github 上找到:
https://github.com/victordibia/handtrack.js/#other-helper-methods
然后使用 rollup.js 捆绑源文件,并在 npm 上发布(包括 webmodel 文件)。目前 Handtrack.js 与 Tensorflow.js(v0.13.5)捆绑在一起,主要是因为在编写这个库的时候,Tensorflow.js(v0.15)在加载图像 / 视频标签为张量时会发生类型错误。如果新版本修复了这个问题,我也将更新到最新版本。
什么时候应该使用 Handtrack.js?
如果你对基于手势的交互式体验感兴趣,Handtrack.js 可能会很有用。用户不需要使用任何额外的传感器或硬件就可以立即获得基于手势的交互体验。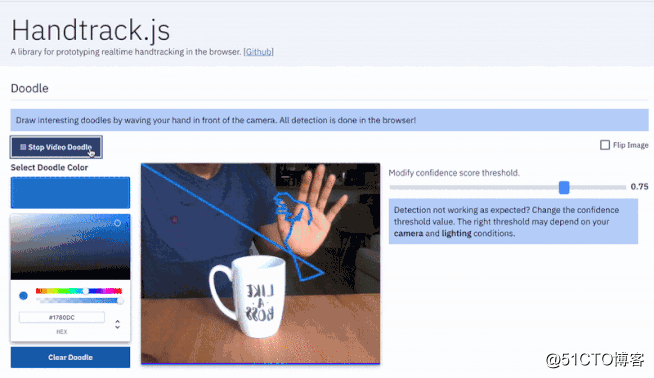
下面列出了一些(并非所有)相关的场景:
局限性
逐帧跟踪手部动作:如果想要跨帧识别手势,需要编写额外的代码来推断手在进入、移动和离开连续帧时的 ID。
不正确的预测:偶尔会出现不正确的预测(有时候会将脸检测为手)。我发现,不同的摄像头和光线条件都需要不同的模型参数设置(尤其是置信度阈值)才能获得良好的检测效果。更重要的是,这个可以通过额外的数据进行改进。下一步
https://github.com/tensorflow/tfjs-models/tree/master/posenet
以及用于在浏览器中检测面部表情的 handsfree.js:
https://handsfree.js.org/
与此同时,我将在以下这些方面花更多的时间:
创建更好的模型:创建一个强大的基准来评估底层的手部模型。收集更多可提高准确性和稳定性的数据。
额外的词汇表:在构建样本时,我发现这种交互方法的词汇表很有限。最起码还需要支持更多的状态,比如拳头和摊开的手掌。这意味着需要重新标记数据集(或使用一些半监督方法)。
额外的模型量化:现在,我们使用的是 MobilenetV2。是否还有更快的解决方案?
英文原文:
https://hackernoon.com/handtrackjs-677c29c1d585
文章标题:Handtrack.js 开源:3行JS代码搞定手部动作跟踪
文章链接:http://soscw.com/index.php/essay/37960.html