为什么说GraphQL可以取代REST API?
2020-12-24 17:27
标签:包含 app 端点 str 版本 created sts 相对 差距 我是 Indeed(世界排名第一的求职网站)的软件工程负责人,所以让我们先来看看 Indeed.com 的主页和职位查询结果页面。它们分别发出了 10 和 11 个 XHR 请求。 响应结果可能是这样的: 通常,单个调用比多个调用更方便、更有效,因为它需要更少的代码和更少的网络开销。来自 PayPal 过程团队的开发体验还证实,很多 UI 工作实际上不是 UI 工作,而是其他任务,例如前端和后端之间的通信: 首先,GraphQL 有助于减少发出的请求数。通过单个调用来获取所需的数据比使用多个请求要容易得多。从工程师的角度来看,这加快了开发速度。后面我会解释更多有关为什么会提升开发速度的原因,但现在我想先说明另一个问题。 GraphQL 提供了更好的开发者体验(DX),开发者将花更少的时间思考如何获取数据。在使用 Apollo 时,他们只需要在 UI 中声明数据。数据和 UI 放在一起,阅读代码和编写代码都变得更方便。 ERROR 使用这种方法,可以非常容易地修改或向 UI 或查询(gql)添加新字段。React 组件的可移植性更强了,因为它们描述了所需的所有数据。 工程师并不是唯一从 GraphQL 中受益的人。用户也会从中受益,因为应用程序的性能获得了提升(可以感知到的): 通常,客户端会发出复杂的请求来获取有序、排好序、被过滤过的数据或子集(用于分页),或者请求嵌套对象。GraphQL 支持嵌套数据和其他难以使用标准 REST API 资源(也叫端点或路由)实现的查询。 上面的请求将比使用多个 REST 请求更好,但它不是标准化的,不受客户端库支持,而且这样的代码也更难编写和维护。对于相对复杂的 API,工程师需要在查询中使用自己的查询字符串参数约定,最终得到类似 GraphQL 的东西。既然 GraphQL 已经提供了标准和库,为什么还要基于 REST 设计自己的查询约定呢? 在使用 GraphQL 时,我们可以在查询中保留嵌套对象,对于每个对象,我们将精确地获得我们需要的数据,不多也不少。 相比复杂的 REST 端点,使用 GraphQL 的另一个好处是提高了安全性。这是因为 URL 经常会被记录下来,而 RESTful GET 端点依赖于查询字符串(是 URL 的一部分)。这可能会暴露敏感数据,所以 RESTful GET 请求的安全性低于 GraphQL 的 POST 请求。我打赌这就是为什么 Indeed 主页会使用 POST 发出“阅读”页面请求。 GraphQL 的 schema 与语言无关。对前面的示例进行扩展,我们可以在 schema 中定义 Address 类型: String 和 Int 是标量类型,! 表示字段不可为空。 我们可以使用我们的类型构建复杂的 GraphQL schema。例如,用户类型可能会使用我们的地址、简历和订阅类型,如下所示: Indeed 的大量对象和类型都是使用 ProtoBuf 定义的。类型化数据并不是什么新鲜事物,而且类型数据的好处也是众所周知。与发明新的 JSON 类型标准相比,GraphQL 的优点在于已经存在可以从 ProtoBuf 自动换换到 GraphQL 的库。即使其中一个库(rejoiner:https://github.com/google/rejoiner) 不能用,也可以开发自己的转换器。 在选择实现 GraphQL API 的平台时,Node 是一个候选项,因为最初 GraphQL 用于 Web 应用程序和前端,而 Node 是开发 Web 应用程序的首选,因为它是基于 JavaScript 的。使用 Node 可以非常容易地实现 GraphQL(假设提供了 schema)。事实上,使用 Express 或 Koa 来实现只需要几行代码: schema 是使用 npm 的 graphql 中的类型来定义的。Query 和 Mutation 是特殊的 schema 类型。 GraphQL 的 schema 使用 POJO 来定义。GraphQL 端点类使用了 LinkRepository POJO。解析器包含了操作的(例如获取链接)实际代码: 在很多情况下,GraphQL 的 schema 可以从其他类型的 schema 自动生成,例如 gRPC、Boxcar、ProtoBuf 或 ORM/ODM。 以下代码可以在任意一个现代浏览器(为了避免 CORS,请访问 launchpad.graphql.com)中运行。 虽然构建 GraphQL 请求很容易,但是还需要实现很多其他东西,比如缓存,因为缓存可以极大地改善用户体验。构建客户端缓存不是那么容易,所幸的是,Apollo 和 Relay Modern 等提供了开箱即用的客户端缓存。 当然,完美的解决方案是不存在的(尽管 GraphQL 接近完美),还有一些问题需要注意,例如: GraphQL 是一种协议和一种查询语言。GraphQL API 可以直接访问数据存储,但在大多数情况下,GraphQL API 是一个数据聚合器和一个抽象层,一个可以提升开发速度、减少维护工作并让开发人员更快乐的层。因此,GraphQL 比公共 API 更有意义。很多公司开始采用 GraphQL。IBM、PayPal 和 GitHub 声称在使用 GraphQL 方面取得了巨大的成功。如果 GraphQL 很有前途,我们现在是否可以停止构建过时且笨重的 REST API,并拥抱 GraphQL? 为什么说GraphQL可以取代REST API? 标签:包含 app 端点 str 版本 created sts 相对 差距 原文地址:https://blog.51cto.com/15057848/2567816
作者|Azat Mardan
译者|薛命灯
在这篇文章中,我将介绍 GraphQL 的优势,以及为什么它会变得如此受欢迎。
几年前,我在 DocuSign 带领了一个开发团队,任务是重写一个有数千万个用户在使用的 Web 应用程序。当时还没有可以支持前端的 API,因为从一开始,Web 应用程序就是一个.NET 大单体。西雅图的 API 团队在将拆分单体,并逐步暴露出 RESTful API。这个 API 团队由两名工程师组成,发布周期为一个月,而我们在旧金山的前端团队每周都会发布新版本。
API 团队的发布周期太长,因为很多(几乎所有)功能都必须进行手动测试,这是可以理解的。它毕竟是一个单体,而且没有适当的自动化测试——如果他们修改了一个地方,不知道在应用程序的其他地方会出现什么问题。
我记得有一次,我们的前端团队面临为某大会交付新版本的压力,但我们忘记跟进一个重要的 API 变更,这个变更未被包含在即将发布的 API 版本中。我们要么一直等待,直到错过截止日期,要么有人愿意放弃优先权,以便让我们的变更包括在即将发布的版本中。所幸的是,这个变更最后被包含在新版本中,我们也及时发布了新的前端版本。我真的希望当时我们已经使用了 GraphQL,因为它可以消除对外部团队及其发布周期的重度依赖。
很多公司已经在内部从 RESTful 转向了 GraphQL API:IBM、Twitter、Walmart Labs、纽约时报、Intuit、Coursera,等等。
其他一些公司不仅是在内部而且还将外部 API 也转为 GraphQL:AWS、Yelp、GitHub、Facebook 和 Shopify,等等。GitHub 甚至打算停止使用 REST API,他们的 v4 版本只使用 GraphQL。
GraphQL 究竟是一个炒作流行语还是真正会带来一场变革?有趣的是,我之前列出的大多数从 GraphQL 获益的公司都有以下这些共同点。
GitHub 工程团队表明了他们的动机:
“GraphQL 弥合了发布的内容与可以使用的内容之间的差距。我们真的很期待能够同时发布它们。GraphQL 代表了 API 开发的巨大飞跃。类型安全、内省、生成文档和可预测的响应都为我们平台的维护者和消费者带来了好处。我们期待着由 GraphQL 提供支持的平台进入新时代,也希望你们也这样做!”
GraphQL 加速了开发速度,提升了开发者体验,并提供了更好的工具。我并不是说这绝对是这样的,但我会尽力说明 GraphQL 与 REST 之间的争论点及其原因。
超级数据聚合器
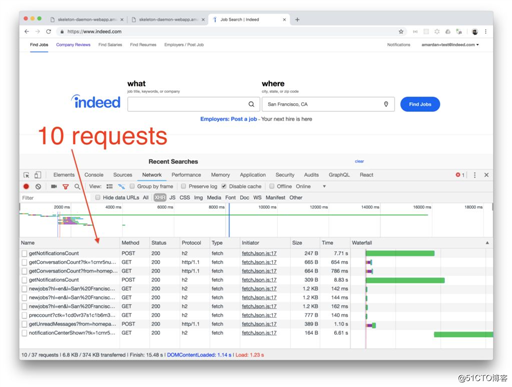
需要注意的是,在 REST 中使用 POST 进行页面浏览并不是很“正规”。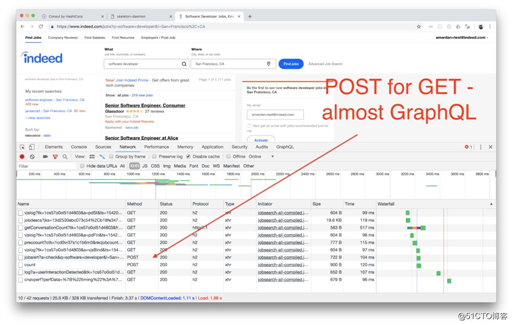
以下是其中的一些调用:
https://inbox.indeed.com/api/getConversationCount
https://www.indeed.com/rpc/jobdescs
https://www.indeed.com/rpc/vjslog
https://www.indeed.com/rpc/preccount
https://www.indeed.com/rpc/jobalert
https://www.indeed.com/rpc/count
在使用 GraphQL 时,上面的这些请求可以被包含在单个查询和单个请求中。query HomePage {
getConversationCount(...) {
...
}
jobdescs(...) {
...
}
vjslog(...) {
...
}
preccount(...) {
…
}
jobalert(...) {
…
}
count(...) {
…
}
}{
"data": {
"getConversationCount": [
{
...
}
],
"vjslog": [...],
"preccount": [...],
"jobalert": [...],
"count": {}
},
"errors": []
}
“我们发现,UI 开发人员实际用于构建 UI 的时间不到三分之一,剩下的时间用于确定在何处以及如何获取数据、过滤 / 映射数据以及编排 API 调用,还有一些用于构建和部署。”
需要注意的是,有实时使多个请求也是有必要的,例如多个单独的请求可以快速且异步独立地获取不同的数据,如果采用了微服务架构,它们会增加部署灵活性,而且它们的故障点是多个,而不是一个。
此外,如果页面是由多个团队开发的,GraphQL 提供了一个功能,可以将查询分解称为片段。稍后我们将详细介绍这方面的内容。
从更大的角度来看,GraphQL API 的主要应用场景是 API 网关,在客户端和服务之间提供了一个抽象层。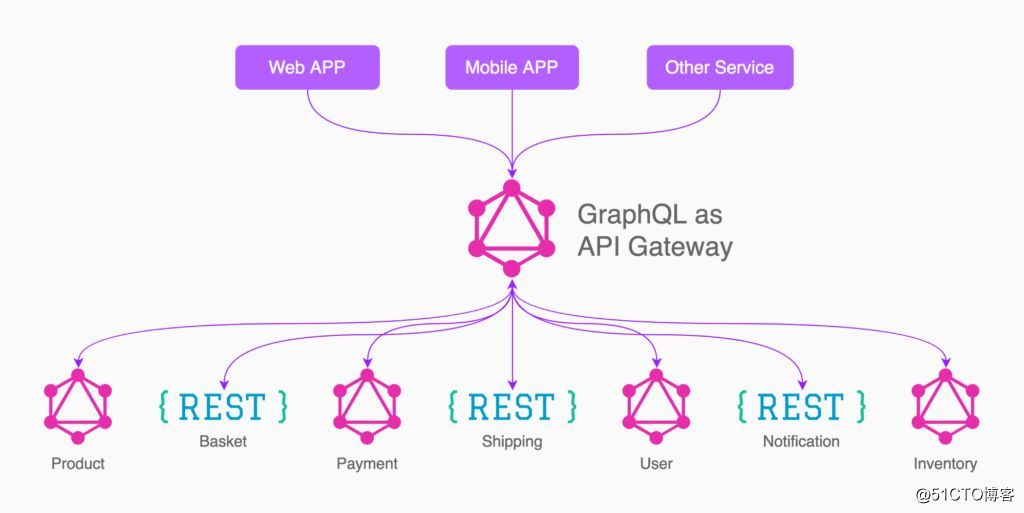
微服务架构很好,但也存在一些问题,GraphQL 可以用来解决这些问题。以下是来自 IBM 在微服务架构中使用 GraphQL 的经验:
“总的来说,GraphQL 微服务的开发和部署都非常快。他们 5 月份开始开发,7 月份就进入了生产环境。因为他们不需要征得许可,直接开干。他强烈推荐这个方案,比开会讨论好太多了。”
接下来,让我们逐一讨论 GraphQL 的每一个好处。提高开发速度
后端和客户端团队需要通过密切合作来定义 API、测试它们,并做出更改。前端、移动、物联网(例如 Alexa)等客户端团队不断迭代功能,并尝试使用新的 UX 和设计。他们的数据需求经常发生变化,后端团队必须跟上他们的节奏。如果客户端和后端代码由同一团队负责,那么问题就没那么严重了。Indeed 的大多数工程团队都是由全栈工程师组成,但并非全部都是这样。对于非全栈团队,客户端团队经常因为依赖了后端团队开发速度受到影响。
当我转到 Job Seeker API 团队时,移动团队开始我们的开发进度。我们之间有很多关于参数、响应字段和测试的事情需要沟通。
在使用了 GraphQL 之后,客户端工程师就可以完全控制前端,不需要依赖任何人,因为他们可以告诉后端他们需要什么以及响应结构应该是怎样的。他们使用了 GraphQL 查询,它们会告诉后端 API 应该要提供哪些数据。
客户端工程师不需要花时间让后端 API 团队添加或修改某些内容。GraphQL 具有自文档的特点,所以可以节省一些用于查找文档以便了解如何使用 API 的时间。我相信大多数人曾经在找出确切的请求参数方面浪费了很多时间。GraphQL 协议本身及其社区在文档方面为我们提供了一些有用的工具。在某些情况下,可以从模式自动生成文档。其他时候,只需使用 GraphiQL Web 界面就足以编写一个查询。
来自纽约时报的工程师表示,他们在转到 GraphQL 和 Relay 之后,在做出变更时不需要改太多的东西:
“当我们想要更新所有产品的设计时,不再需要修改多个代码库。这就是我们想要的。我们认为 Relay 和 GraphQL 是帮助我们实现这个伟大目标的完美工具。”
当一家公司已经拥有大量 GraphQL API,然后有人想出了一个新的产品创意,这也是我最喜欢 GraphQL 的应用场景。使用已有的 GraphQL API 实现原型比调用各种 REST 端点(将提供太少或太多的数据)或为新应用程序构建新的 REST API 要快得多。
开发速度的提升与开发者体验的提升密切相关。提升开发者体验
通常,在开发 UI 时需要在 UI 模板、客户端代码和 UI 样式之间跳转。GraphQL 允许工程师在客户端开发 UI,减少摩擦,因为工程师在添加或修改代码时无需在文件之间切换。如果你熟悉 React,这里有一个很好的比喻:GraphQL 之于数据,就像 React 之于 UI。
下面是一个简单的示例,UI 中直接包含了属性名称 launch.name 和 launch.rocket.name。const GET_LAUNCHES = gql`
query launchList($after: String) {
launches(after: $after) {
launches {
id
name
isBooked
rocket {
id
name
}
}
}
}
`;
export default function Launches() {
return (
Rocket: {launch.rocket.name}
如前所述, GraphQL 提供了更好的文档,而且还有一个叫作 GraphiQL 的 IDE: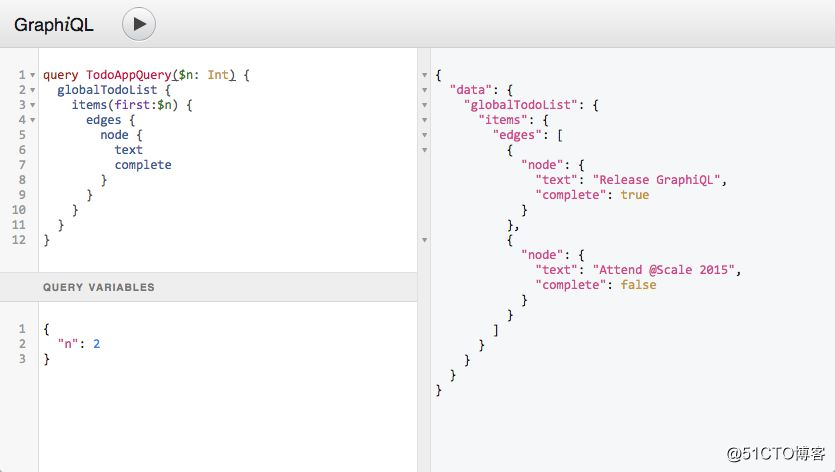
前端工程师很喜欢 GraphiQL,下面引用 Indeed 的一位高级工程师说过的话:
“我认为开发体验中最好的部分是能够使用 GraphiQL。对我来说,与典型的 API 文档相比,这是一种编写查询更有效的辅助方法”。
GraphQL 的另一个很棒的功能是片段,因为它允许我们在更高的组件层面重用查询。
这些功能改善了开发者体验,让开发人员更快乐,更不容易出现 JavaScript 疲劳。提升性能
1.减少了有效载荷(客户端只需要必要的东西);
2.多个请求合并为一个请求可减少网络开销;
3.使用工具可以更轻松地实现客户端缓存和后端批处理和后端缓存;
4.预取;
5.更快的 UI 更新。
PayPal 使用 GraphQL 重新设计了他们的结账流程。下面是来自用户的反馈:
“REST 的原则并没有为 Web 和移动应用及其用户的需求考虑,这个在结账优化交易中体现得尤为明显。用户希望能够尽快完成结账,如果应用程序使用了很多原子 REST API,就需要在客户端和服务器之间进行多次往返以获取数据。我们的结账每次往返网络时间至少需要 700 毫秒,这还不包括服务器处理请求的时间。每次往返都会导致渲染变慢,用户体验不好,结算转换率也会降低。”
性能改进中有一项是“多个请求组合成一个请求可以减少网络开销”。对于 HTTP/1 而言,这是非常正确的,因为它没有 HTTP/2 那样的多路复用机制。但尽管 HTTP/2 提供的多路复用机制有助于优化单独的请求,但它对于图遍历(获取相关或嵌套对象)并没有实际帮助。让我们来看一看 REST 和 GraphQL 是如何处理嵌套对象和其他复杂请求的。标准化和简化复杂的 API
例如,我们假设有三种资源:用户、订阅和简历。工程师需要按顺序进行两次单独的调用(这会降低性能)来获取一个用户简历,首先需要通过调用获取用户资源,拿到简历 ID,然后再使用简历 ID 来获取简历数据。对于订阅来说也是一样的。
1.GET /users/123:响应中包含了简历 ID 和工作岗位通知订阅的 ID 清单;
2.GET /resumes/ABC:响应中包含了简历文本——依赖第一个请求;
3.GET /subscriptions/XYZ:响应中包含了工作岗位通知的内容和地址——依赖第一个请求。
上面的示例很糟糕,原因有很多:客户端可能会获得太多数据,并且必须等待相关的请求完成了以后才能继续。此外,客户端需要实现如何获取子资源(例如建立或订阅)和过滤。
想象一下,一个客户端可能只需要第一个订阅的内容和地址以及简历中的当前职位,另一个客户端可能需要所有订阅和整个简历列表。所以,如果使用 REST API,对第一个客户端来说有点不划算。
另一个例子:用户表里可能会有用户的名字和姓氏、电子邮件、简历、地址、电话、社会保障号、密码(当然是经过混淆的)和其他私人信息。并非每个客户端都需要所有字段,有些应用程序可能只需要用户电子邮件,所以向这些应用程序发送社会保障号等信息就不太安全。
当然,为每个客户端创建不同的端点也是不可行的,例如 /api/v1/users 和 /api/v1/usersMobile。
事实上,各种客户端通常都有不同的数据需求:/api/v1/userPublic、/api/v1/userByName、/api/v1/usersForAdmin,如果这样的话,端点会呈指数级增长。
GraphQL 允许客户要求 API 发送他们想要的字段,这将使后端工作变得更加容易:/api/gql——所有客户端只需要这个端点。
注意:对于 REST 和 GraphQL,后端都需要使用访问控制级别。
或者可以使用旧 REST 来实现 GraphQL 的很多功能。但是这样要付出什么代价?后端可以支持复杂的 RESTful 请求,这样客户端就可以使用字段和嵌套对象进行调用:GET /users/?fields=name,address&include=resumes,subscriptions
将复杂的 REST 端点与以下的 GraphQL 嵌套查询进行对比,嵌套查询使用了更多的过滤条件,例如“只要给我前 X 个对象”和“按时间按升序排列”(可以添加无限制的过滤选项):{
user (id: 123) {
id
firstName
lastName
address {
city
country
zip
}
resumes (first: 1, orderBy: time_ASC) {
text
title
blob
time
}
subscriptions(first: 10) {
what
where
time
}
}
}
}
响应消息的数据格式反映了请求查询的结构,如下所示:{
"data": {
"user": {
"id": 123,
"firstName": "Azat",
"lastName": "Mardan",
"address": {
"city": "San Francisco",
"country": "US",
"zip": "94105"
},
"resumes" [
{
"text": "some text here...",
"title": "My Resume",
"blob": "
使用 GraphQL 可有更容易地实现分页等关键功能,这要归功于查询以及 BaaS 提供商提供的标准,以及后端的实现和客户端库使用的标准。改进的安全性、强类型和验证
type Address {
city: String!
country: String!
zip: Int
}
schema 验证是 GraphQL 规范的一部分,因此像这样的查询将返回错误,因为 name 和 phone 不是 Address 对象的字段:
{
user (id: 123) {
address {
name
phone
}
}
}type User {
id: ID!
firstName: String!
lastName: String!
address: Address!
resumes: [Resume]
subscriptions: [Subscription]
}
GraphQL 提供了比 JSON RESTful API 更强的安全性,主要有两个原因:强类型 schema(例如数据验证和无 SQL 注入)以及精确定义客户端所需数据的能力(不会无意泄漏数据)。
静态验证是另一个优势,可以帮助工程师节省时间,并在进行重构时提升工程师的信心。诸如 eslint-plugin-graphql(https://github.com/apollographql/eslint-plugin-graphql)之类的工具可以让工程师知道后端发生的变化,并让后端工程师确保不会破坏客户端代码。
保持前端和后端之间的契约是非常重要的。在使用 REST API 时,我们要小心不要破坏了客户端代码,因为客户端无法控制响应消息。相反,GraphQL 为客户端提供了控制,GraphQL 可以频繁更新,而不会因为引入了新类型造成重大变更。因为使用了 schema,所以 GraphQL 是一种无版本的 API。GraphQL 的实现
const Koa = require(‘koa‘);
const Router = require(‘koa-router‘); // koa-router@7.x
const graphqlHTTP = require(‘koa-graphql‘);
const app = new Koa();
const router = new Router();
router.all(‘/graphql‘, graphqlHTTP({
schema: schema,
graphiql: true
}));
app.use(router.routes()).use(router.allowedMethods());
GraphQL API 的大部分实现都在于 schema 和解析器。解析器可以包含任意代码,但最常见的是以下五个主要类别:
这里有一个示例:
https://medium.freecodecamp.org/graphql-zero-to-production-a7c4f786a57b。
Node 很棒,但在 Indeed,我们主要使用 Java。包括 Java 在内的很多语言都支持 GraphQL,例如:
由于 Indeed 主要使用了 Java,因此这里给出一个使用 graphql-java 的 Java GraphQL 示例,完整代码位于 https://github.com/howtographql/graphql-java。它定义了 /graphql 端点:import com.coxautodev.graphql.tools.SchemaParser;
import javax.servlet.annotation.WebServlet;
import graphql.servlet.SimpleGraphQLServlet;
@WebServlet(urlPatterns = "/graphql")
public class GraphQLEndpoint extends SimpleGraphQLServlet {
public GraphQLEndpoint() {
super(SchemaParser.newParser()
.file("schema.graphqls") //parse the schema file created earlier
.build()
.makeExecutableSchema());
}
}@WebServlet(urlPatterns = "/graphql")
public class GraphQLEndpoint extends SimpleGraphQLServlet {
public GraphQLEndpoint() {
super(buildSchema());
}
private static GraphQLSchema buildSchema() {
LinkRepository linkRepository = new LinkRepository();
return SchemaParser.newParser()
.file("schema.graphqls")
.resolvers(new Query(linkRepository))
.build()
.makeExecutableSchema();
}
}
GraphQL 不一定需要客户端。一个简单的 GraphQL 请求就是一个常规的 POST HTTP 请求,其中包含了查询内容。我们可以使用任意的 HTTP 代理库(如 CURL、axios、fetch、superagent 等)来生成请求。例如,在终端中使用 curl 发送请求:curl -X POST -H "Content-Type: application/json" --data ‘{ "query": "{ posts { title } }" }‘ https://1jzxrj179.lp.gql.zone/graphqlfetch(‘https://1jzxrj179.lp.gql.zone/graphql‘, {
method: ‘POST‘,
headers: { ‘Content-Type‘: ‘application/json‘ },
body: JSON.stringify({ query: ‘{ posts { title } }‘ }),
})
.then(res => res.json())
.then(res => console.log(res.data));什么时候不该使用 GraphQL?
1.它有单点故障吗?
2.它可以扩展吗?
3.谁在使用 GraphQL?
最后,以下列出了我们自己的有关 GraphQL 可能不是一个好选择的主要原因:
总 结
英文原文:https://webapplog.com/graphql/
文章标题:为什么说GraphQL可以取代REST API?
文章链接:http://soscw.com/index.php/essay/37969.html