分布式日志收集器 - Flume
2020-12-24 22:27
标签:单元 list 移动 eve archive array 就是 man port 官方文档: Flume是一种分布式、高可靠和高可用的日志数据采集服务,可高效地收集、聚合和移动大量日志数据。它具有一种基于流数据的简单且灵活的体系结构。它具有健壮性和容错性,具有可调整的可靠性机制和许多故障切换和恢复机制。它使用一个简单的可扩展数据模型,允许在线分析应用程序。 Flume的架构图: 准备好JDK环境: 下载Flum: 复制下载链接进行下载: 解压到合适的目录下: 配置环境变量: 编辑配置文件: 测试 使用Flume的关键就是写配置文件: 所以首先创建一个配置文件: 启动agent: 然后通过 此时在flume的输出内容中会看到打印了接收到的数据: 同样的,先创建一个配置文件: 创建测试文件: 启动agent: 写入一些内容到 此时在flume的输出内容中会看到打印了监听文件的新增数据: 要实现这个需求,需要使用Avro的Source和SInk。流程图如下: 为了测试方便,我这里使用一台机器来进行模拟。首先机器A的配置文件如下: 机器B的配置文件如下: 先启动机器B的agent,否则机器A的agent监听不到目标机器的端口可能会报错: 启动机器A的agent: 写入一些内容到 此时机器B的agent在控制台输出的内容如下,如此一来我们就实现了将A服务器上的日志实时采集到B服务器的功能: 在上面的示例中,Agent B是将收集到的数据Sink到控制台上,但在实际应用中显然是不会这么做的,而是通常会将数据Sink到一个外部数据源中,如HDFS、ES、Kafka等。在实时流处理架构中,绝大部分情况下都会Sink到Kafka,然后下游的消费者(一个或多个)接收到数据后进行实时处理。如下图所示: 所以这里基于上一个例子,演示下如何整合Kafka。其实很简单,只需要将Logger Sink换成Kafka Sink就可以了。换成Kafka后的流程如下: 创建一个新的配置文件,内容如下: 配置完成后,启动该Agent: 然后启动另外一个Agent: 启动一个Kafka消费者,方便观察Kafka接收到的数据: 写入一些内容到 此时Kafka消费者端的控制台正常情况下会输出如下内容,证明Flume到Kafka已经整合成功了: 分布式日志收集器 - Flume 标签:单元 list 移动 eve archive array 就是 man port 原文地址:https://blog.51cto.com/zero01/2546278
Flume架构及核心组件
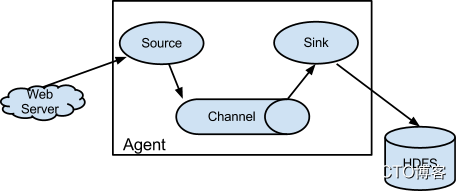
Flume部署
[root@hadoop01 ~]# java -version
java version "11.0.8" 2020-07-14 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)
[root@hadoop01 ~]#
[root@hadoop01 ~]# cd /usr/local/src
[root@hadoop01 /usr/local/src]# wget https://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.16.2.tar.gz
[root@hadoop01 /usr/local/src]# tar -zxvf flume-ng-1.6.0-cdh5.16.2.tar.gz -C /usr/local
[root@hadoop01 /usr/local/src]# cd /usr/local/apache-flume-1.6.0-cdh5.16.2-bin/
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# ls
bin CHANGELOG cloudera conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# [root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# vim ~/.bash_profile
export FLUME_HOME=/usr/local/apache-flume-1.6.0-cdh5.16.2-bin
export PATH=$PATH:$FLUME_HOME/bin
[root@hadoop01 /usr/local/apache-flume-1.6.0-cdh5.16.2-bin]# source ~/.bash_profile[root@hadoop01 ~]# cp $FLUME_HOME/conf/flume-env.sh.template $FLUME_HOME/conf/flume-env.sh
[root@hadoop01 ~]# vim $FLUME_HOME/conf/flume-env.sh
# 配置JDK
export JAVA_HOME=/usr/local/jdk/11
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"flume-ng命令:[root@hadoop01 ~]# flume-ng version
Flume 1.6.0-cdh5.16.2
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: df92badde3691ee3eb6074a177f0e96682345381
Compiled by jenkins on Mon Jun 3 03:49:33 PDT 2019
From source with checksum 9336bfa3ff8cfb5e20cd9d700135a2c1
[root@hadoop01 ~]#
Flume实战案例 - 从指定网络端口采集数据输出到控制台
[root@hadoop01 ~]# vim $FLUME_HOME/conf/netcat-example.conf
# a1是agent的名称
a1.sources = r1 # source的名称
a1.sinks = k1 # sink的名称
a1.channels = c1 # channel的名称
# 描述和配置source
a1.sources.r1.type = netcat # 指定source的类型为netcat
a1.sources.r1.bind = localhost # 指定source的ip
a1.sources.r1.port = 44444 # 指定source的端口
# 定义sink
a1.sinks.k1.type = logger # 指定sink类型,logger就是将数据输出到控制台
# 定义一个基于内存的channel
a1.channels.c1.type = memory # channel类型
a1.channels.c1.capacity = 1000 # channel的容量
a1.channels.c1.transactionCapacity = 100 # channel中每个事务的最大事件数
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1 # 指定r1这个source的channel为c1
a1.sinks.k1.channel = c1 # 指定k1这个sink的channel为c1
[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/netcat-example.conf -Dflume.root.logger=INFO,consoletelnet命令发送一些数据到44444端口:[root@hadoop01 ~]# telnet localhost 44444
...
hello flume
OK2020-11-02 16:08:47,965 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 0D hello flume. }
Flume实战案例 - 监控一个文件实时采集新增的数据输出到控制台
[root@hadoop01 ~]# vim $FLUME_HOME/conf/file-example.conf
# a1是agent的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /data/data.log
a1.sources.r1.shell = /bin/sh -c
# 定义sink
a1.sinks.k1.type = logger
# 定义一个基于内存的channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1[root@hadoop01 ~]# touch /data/data.log[root@hadoop01 ~]# flume-ng agent --name a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/file-example.conf -Dflume.root.logger=INFO,consoledata.log中:[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log2020-11-02 16:21:26,946 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 16:21:38,707 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
Flume实战案例 - 将A服务器上的日志实时采集到B服务器
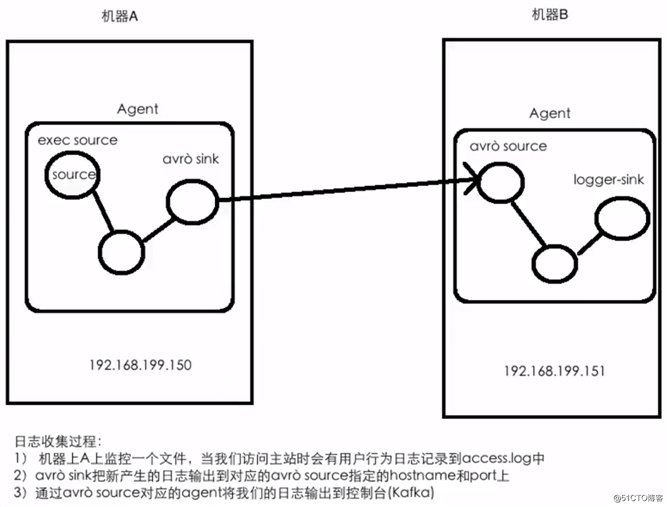
[root@hadoop01 ~]# vim $FLUME_HOME/conf/exec-memory-avro.conf
# 定义各个组件的名称
exec-memory-avro.sources = exec-source
exec-memory-avro.sinks = avro-sink
exec-memory-avro.channels = memory-channel
# 描述和配置source
exec-memory-avro.sources.exec-source.type = exec
exec-memory-avro.sources.exec-source.command = tail -f /data/data.log
exec-memory-avro.sources.exec-source.shell = /bin/sh -c
# 定义sink
exec-memory-avro.sinks.avro-sink.type = avro
exec-memory-avro.sinks.avro-sink.hostname = hadoop01
exec-memory-avro.sinks.avro-sink.port = 44444
# 定义一个基于内存的channel
exec-memory-avro.channels.memory-channel.type = memory
exec-memory-avro.channels.memory-channel.capacity = 1000
exec-memory-avro.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
exec-memory-avro.sources.exec-source.channels = memory-channel
exec-memory-avro.sinks.avro-sink.channel = memory-channel[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-logger.conf
# 定义各个组件的名称
avro-memory-logger.sources = avro-source
avro-memory-logger.sinks = logger-sink
avro-memory-logger.channels = memory-channel
# 描述和配置source
avro-memory-logger.sources.avro-source.type = avro
avro-memory-logger.sources.avro-source.bind = hadoop01
avro-memory-logger.sources.avro-source.port = 44444
# 定义sink
avro-memory-logger.sinks.logger-sink.type = logger
# 定义一个基于内存的channel
avro-memory-logger.channels.memory-channel.type = memory
avro-memory-logger.channels.memory-channel.capacity = 1000
avro-memory-logger.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-logger.sources.avro-source.channels = memory-channel
avro-memory-logger.sinks.logger-sink.channel = memory-channel[root@hadoop01 ~]# flume-ng agent --name avro-memory-logger -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-logger.conf -Dflume.root.logger=INFO,console[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,consoledata.log中:[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello world" >> /data/data.log
[root@hadoop01 ~]# echo "hello avro" >> /data/data.log2020-11-02 17:05:20,929 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 66 6C 75 6D 65 hello flume }
2020-11-02 17:05:21,486 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 77 6F 72 6C 64 hello world }
2020-11-02 17:05:51,505 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 20 61 76 72 6F hello avro }
整合Flume和Kafka完成实时数据采集
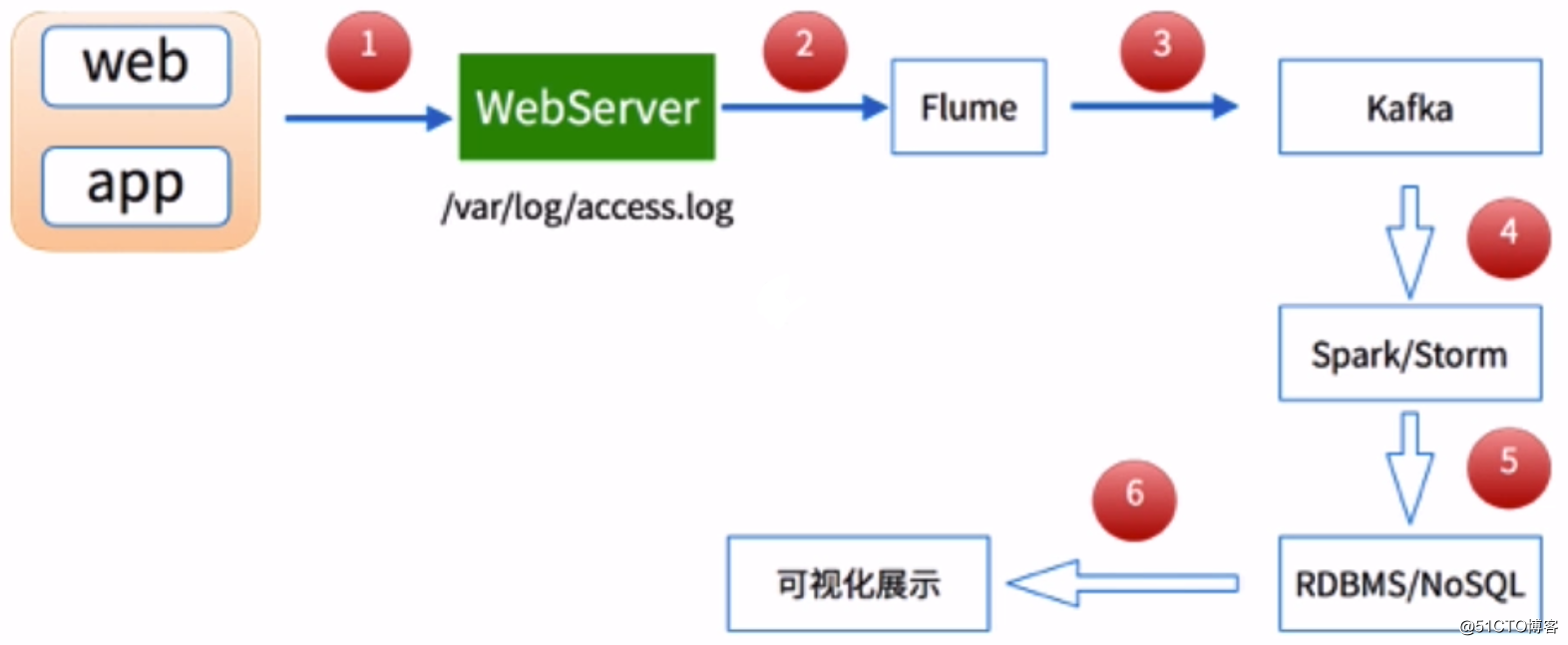
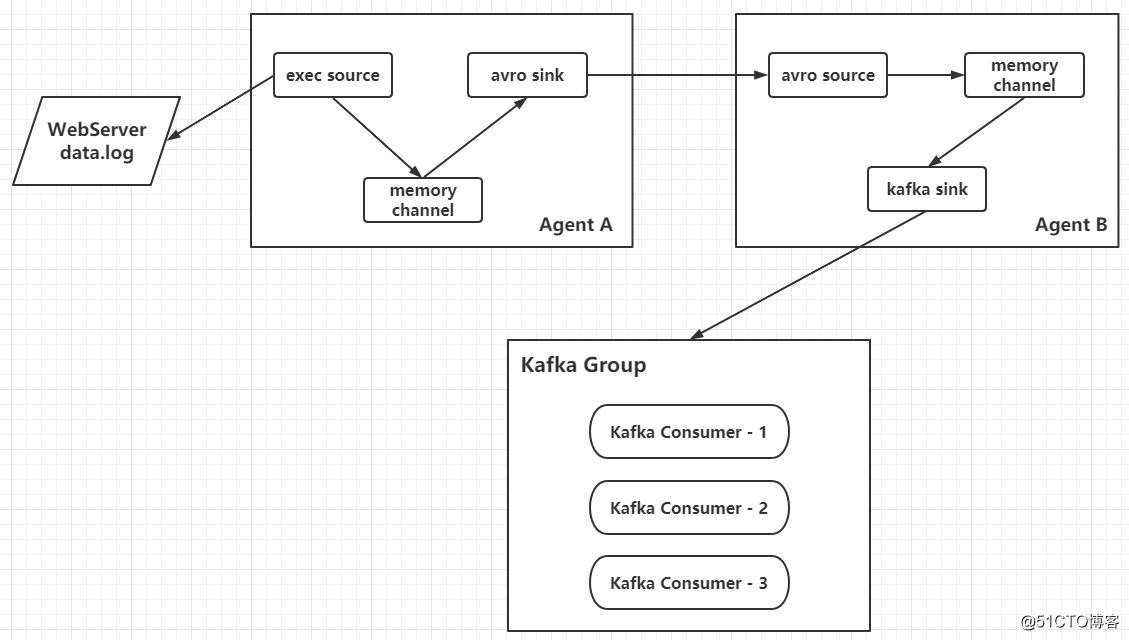
[root@hadoop01 ~]# vim $FLUME_HOME/conf/avro-memory-kafka.conf
# 定义各个组件的名称
avro-memory-kafka.sources = avro-source
avro-memory-kafka.sinks = kafka-sink
avro-memory-kafka.channels = memory-channel
# 描述和配置source
avro-memory-kafka.sources.avro-source.type = avro
avro-memory-kafka.sources.avro-source.bind = hadoop01
avro-memory-kafka.sources.avro-source.port = 44444
# 定义sink
avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
avro-memory-kafka.sinks.kafka-sink.brokerList = kafka01:9092
avro-memory-kafka.sinks.kafka-sink.topic = flume-topic
# 一个批次里发送多少消息
avro-memory-kafka.sinks.kafka-sink.batchSize = 5
# 指定采用的ack模式,可以参考kafka的ack机制
avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1
# 定义一个基于内存的channel
avro-memory-kafka.channels.memory-channel.type = memory
avro-memory-kafka.channels.memory-channel.capacity = 1000
avro-memory-kafka.channels.memory-channel.transactionCapacity = 100
# 将source和sink绑定到channel上,即将三者串连起来
avro-memory-kafka.sources.avro-source.channels = memory-channel
avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
[root@hadoop01 ~]# flume-ng agent --name avro-memory-kafka -c $FLUME_HOME/conf -f $FLUME_HOME/conf/avro-memory-kafka.conf -Dflume.root.logger=INFO,console[root@hadoop01 ~]# flume-ng agent --name exec-memory-avro -c $FLUME_HOME/conf -f $FLUME_HOME/conf/exec-memory-avro.conf -Dflume.root.logger=INFO,console[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginningdata.log中:[root@hadoop01 ~]# echo "hello kafka sink" >> /data/data.log
[root@hadoop01 ~]# echo "hello flume" >> /data/data.log
[root@hadoop01 ~]# echo "hello agent" >> /data/data.log[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server kafka01:9092 --topic flume-topic --from-beginning
hello kafka sink
hello flume
hello agent