Python数据分析帮你清晰的了解整理员工们的工作效率和整体满意度
2020-12-25 06:28
标签:学习 直接 adc 一个 min 允许 sum values aac 前言 本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。 项目背景 2018年,被称为互联网的寒冬之年。无论大小公司,纷纷走上了裁员之路,还有一些比较惨的,直接关门大吉。2019年上半年,甲骨文裁掉大量35岁左右的程序员,谁也没想到,IT界退休年龄这么早!而内心OS:我的房贷还没还清。。。。 假设你是人力资源总监,你该向谁开刀呢?先回答一下下面的问题。 此时,我们在上述结果中发现:寒冰、盖伦是重复数据条,在数据分析过程中,一定要注意重复数据带来的影响,所以我们要进行去重操作。 1.各部门有多少名员工? 2.员工总体流失率是多少? 3.员工平均薪资是多少? 由上图的结果可以看出,平均薪资在16800元,你达到了吗?!允许你去哭一会o(╥﹏╥)o! 4.公司任职时间最久的3名员工是谁? 6.员工整体满意度如何? 接下来,进行员工整体满意度分析。通过计算可以得出:70%员工都比较认可公司,但仍有30%员工对公司不满意。人力主管以及部门主管需要进一步探究清楚这30%员工的情况,因为不满意是否已经离职?还是存在隐患?是否处于核心岗位等等问题值得我们进一步探究。 Python数据分析帮你清晰的了解整理员工们的工作效率和整体满意度 标签:学习 直接 adc 一个 min 允许 sum values aac 原文地址:https://www.cnblogs.com/hhh188764/p/13207784.html

数据处理
import pandas as pd
data = pd.read_excel(r‘c:\Users\Administrator\Desktop\英雄联盟员工信息表.xlsx‘,index_col = u‘工号‘)
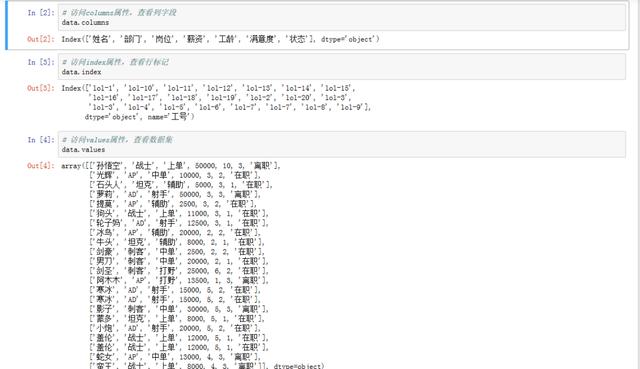
# 访问columns属性,查看列字段
data.columns
# 访问index属性,查看行标记
data.index
# 访问values属性,查看数据集
data.values
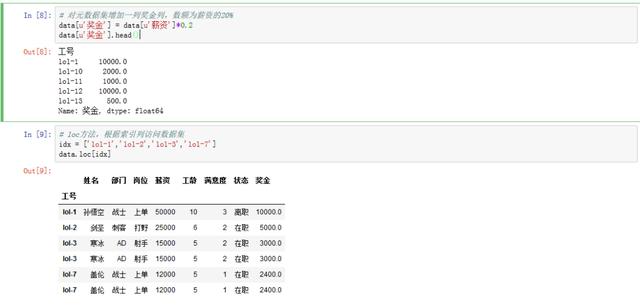
# 对元数据集增加一列奖金列,数额为薪资的20%
data[u‘奖金‘] = data[u‘薪资‘]*0.2
data[u‘奖金‘].head()
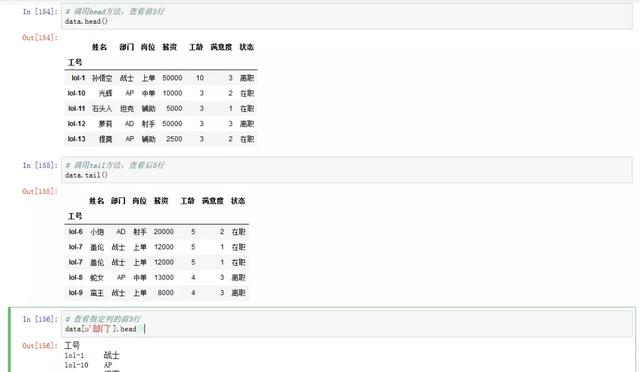
# loc方法,根据索引列访问数据集
idx = [‘lol-1‘,‘lol-2‘,‘lol-3‘,‘lol-7‘]
data.loc[idx]
# 对元数据集增加一列奖金列,数额为薪资的20%
data[u‘奖金‘] = data[u‘薪资‘]*0.2
data[u‘奖金‘].head()
# loc方法,根据索引列访问数据集
idx = [‘lol-1‘,‘lol-2‘,‘lol-3‘,‘lol-7‘]
data.loc[idx]
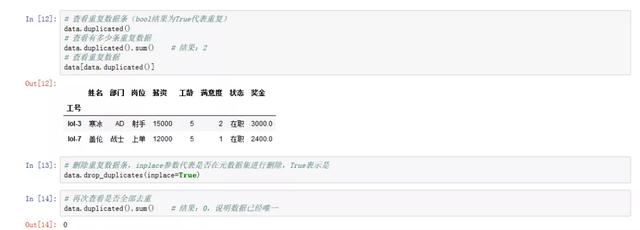
# 查看重复数据条(bool结果为True代表重复)
data.duplicated()
# 查看有多少条重复数据
data.duplicated().sum() # 结果:2
# 查看重复数据
data[data.duplicated()]
# 删除重复数据条,inplace参数代表是否在元数据集进行删除,True表示是
data.drop_duplicates(inplace=True)
# 再次查看是否全部去重
data.duplicated().sum() # 结果:0,说明数据已经唯一
数据分析
# 频数统计
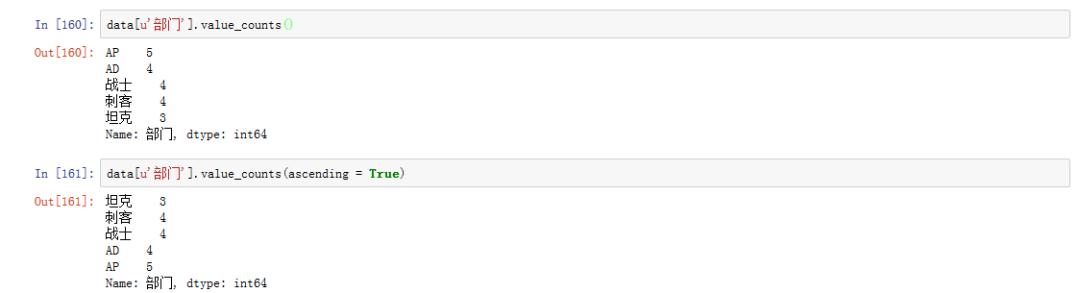
data[u‘部门‘].value_counts()
# ascending = True代表升序展示
data[u‘部门‘].value_counts(ascending = True)
# 频数统计
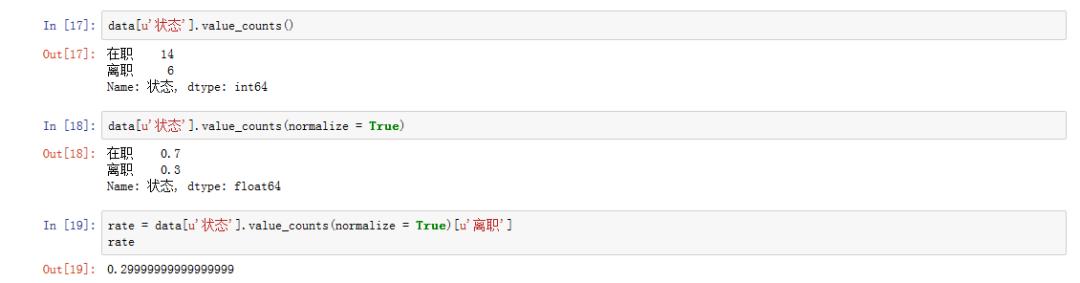
data[u‘状态‘].value_counts()
# normalize = True 获得标准化计数结果
data[u‘状态‘].value_counts(normalize = True)
# 展示出员工总体流失率
rate = data[u‘状态‘].value_counts(normalize = True)[u‘离职‘]
rate

# describe方法也是常用的一种方法,而且结果更全面。
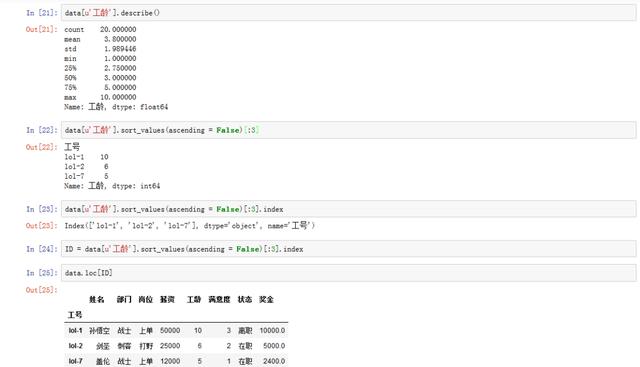
data[u‘工龄‘].describe()
# 通过降序排序、切片操作,找到待的最久的三名员工
data[u‘工龄‘].sort_values(ascending = False)[:3]
ID = data[u‘工龄‘].sort_values(ascending = False)[:3].index
data.loc[ID]
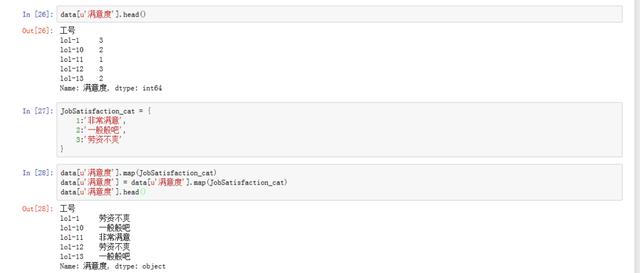
data[u‘满意度‘].head()
# 通过查看满意度前五行发现,不太直观,我们可以用map进行映射,先建立一个映射字典
JobSatisfaction_cat = {
1:‘非常满意‘,
2:‘一般般吧‘,
3:‘劳资不爽‘
}
data[u‘满意度‘].map(JobSatisfaction_cat)
# 对元数据集进行满意度映射
data[u‘满意度‘] = data[u‘满意度‘].map(JobSatisfaction_cat)
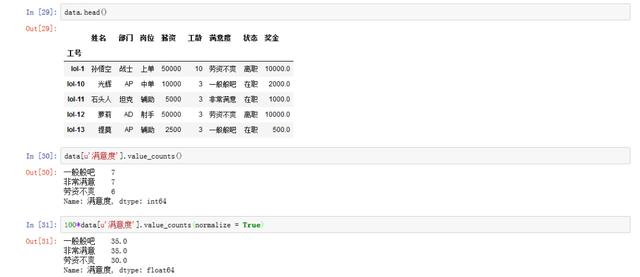
data[u‘满意度‘].head()
data.head()
# 频数统计
data[u‘满意度‘].value_counts()
# 获得标准化计数结果,考虑到百分比更能说明满意度情况,所以乘100展示
100*data[u‘满意度‘].value_counts(normalize = True)
文章标题:Python数据分析帮你清晰的了解整理员工们的工作效率和整体满意度
文章链接:http://soscw.com/index.php/essay/38095.html