数据结构与算法分析 - 9 - 并查集(不相交集)
2020-12-28 19:37
标签:rest 两种 入队 策略 com tail lse 意义 pat 并查集(Disjoint Sets),直译即不相交集。 离散数学中对等价关系的定义:满足自反性、对称性和传递性的关系。 集合A,∀(a,b),a,b∈A,满足aRb,则称R为A上的关系,若R满足以上三种性质,则为等价关系。 数学上的定义不必过多解释,只需知道,等价关系是用来对集合中的元素分类,以达到简化问题的目的的。 举个例子,a,b,c,d,e,f,g∈A,若对于A上的等价关系R,有aRb,aRc,aRd,eRf,fRg,则集合A被划分为两个等价类,即{{a,b,c,d},{e,f,g}}。 套用到实际应用中,a,b,c,d具有等价关系,则a,b,c,d可以被认为是同类事物,同理,e,f,g可以被认为是另一类事物。 并查集主要实现两个功能:并(Union)和查(Find) 等价关系一旦确立往往不会改变,但据此划分的等价类并不总是一成不变。 例如,朋友圈这种关系是长久存在的,a和b是朋友,c和d是朋友,于是形成了两个不同的圈子,即a和b,c和d分别同在一个等价类中。 某一天,a和c相遇了,他们觉得在一起ac很好玩(雾),于是进入了彼此的朋友圈,根据等价关系的传递性(朋友的朋友是朋友),b - a - c - d,这两个圈子有了交集,a,b,c,d形成了一个圈子,这就发生了等价类的合并(Union)。 尽管从朋友圈的定义来讲,b和d因为a和c的关系已经进入了同一个朋友圈,但是他们两个实际上还并未互相认识。 某一天,b和d也偶遇了,他们觉得bd是绝配(大雾),也想进入彼此的朋友圈,但是他们一看朋友圈(Find),发现原来他们已经是同一个圈子里的人了,两人相视一笑。 对于Find操作,最快的无疑是哈希(用数组保存等价类的名字),可以达到O(1)。 但是,如果采用这种数据结构,当执行Union时,将不得不扫描一遍数组,此时复杂度达到了O(N)。看上去还不错?然而实际应用中,Union往往是频繁的,当它的优势:Find的次数不够多时,O(N)的复杂度是无法被接受的。 对于Find操作,并不要求其返回特定的名字,而只要求当且仅当两个元素属于同一个集合时,他们能够返回同样的名字。 以朋友圈为例,没有人(大概)会在事先为自己所在的朋友圈专门命名,b和d要确认他们是否已经在同一个朋友圈,只需要说出他们朋友圈里一个共同的朋友(返回相同的名字)就可以了,至于这个共同的朋友是a还是c并不重要。 于是使用树来表示集合,树上的每一个元素都有相同的根,用根来命名所在的集合,这些树组成森林,即不相交集合森林。 这些树不一定必须是二叉树,其节点中唯一需要保存的信息是其父指针(秩充当了元素的名字)。 不相交集合森林储存在数组P中,P[i]的值表示i的父亲,若i为根,则P[i] = 0,所以,数组的所有的值被初始化为0。 Union:为使两个集合(设为集合i和集合j)合并,只需将其中一个节点中储存的父指针指向另外一个节点。由谁指向谁有多种策略,但毫无疑问,此时Union仅需花费常数时间O(1)。 Find:此时的Find操作是和树的深度正相关的,最坏的情况下,树的深度为N - 1,花费为O(N)。 套用到朋友圈的例子中就是,两个人为了确认是否已经在同一个朋友圈,通过朋友圈的传递性,在整个朋友圈绕了一大圈才发现彼此是朋友。 如上图,从4,9出发,不得不一直向上,直到找到1为止。 要避免最坏的情况出现,一则需要在Union时选取合适的策略,二则需要这棵树能做自优化,自动减小深度,即路径压缩算法。 树越深,则并查集的效率越差。 直接求并往往会导致树越来越深,类似二叉搜索树的不平衡。 有两种求并方法可以避免 1.按大小求并:用一个数组记录树的大小,合并时,总是让小的树并到大的树上。 2.按高度求并(按秩求并):记录树的高度,合并时,总是让矮的树并到高的树上。 记录高度是很麻烦的,所以只记录高度的估计,即用秩代替。按高度求并是事实上的按秩求并。 下图可以直观地感受到 直接求并和按大小求并的区别 按大小求并比直接求并少了一层。 记录树的大小并不难,似乎新开辟一个数组就可以办到。而事实上,甚至不需要额外的空间,基于存储树的数组就可以直接做到。 上面初步实现的并查集中,把所有数组元素初始化为0,代表i是根,除此之外0似乎没有什么意义。 事实上,在有的实现版本中,初始化时将它们初始化为对应的秩,即P[i] = i,以此代表i是根。 在经历合并之后,那些非根的数组元素变成父指针,但根对应的数组的值始终没有变化(总是为0)。 不妨让这部分值承担更多的责任,记录树的大小。 问题在于,记录树的大小会导致无法识别出根(该怎样区分数组中记录的是父指针还是树的大小呢?)。 不难发现,非根的结点对应数组的值,即父指针,所指向的是数组的秩,而秩总是非负的。所以,大可直接在根的数组元素中存储树的大小的负值,这需要在初始化时将所有数组元素设置为-1。 按大小Union实现如下 按大小求并的平均效率可达到O(1),因为执行过程中大部分合并都是很小的集合合并到大集合中。 在根数组元素中记录深度的负值,只需在按大小求并的基础上稍作修改即可。 在按高度求并算法中,只有当两棵树的高度相同时,树的高度才会增加1。 大多数情况下,上面实现的并查集完全可以被接受。但最坏情况仍然很容易发生。 《数据结构与算法分析——C语言描述》中举了这样一个例子 把所有的集合放到一个队列中,并重复地让前两个集合出队,同时让它们的并入队,最坏的情况就会发生。 如下图 此时无论选取哪种Union策略都是无法避免的,这就需要路径压缩。 路径压缩的思路非常简单,在进行一次Find(x)后,可以确定,x属于某个集合,与其下次Find时再次历尽千辛万苦从x找根,不如直接将x设置为根的子节点。其实现也很简单,只需在原有的基础上做一点微小的改动。 这一过程自动发生在Find中,与Union无关,所以与上述两种Union操作并不冲突。 HDUOJ 1232 畅通工程 LeetCode 547 朋友圈 LeetCode 1466 重新规划路线 题解:挖坑待填 参考资料:《数据结构与算法分析——C语言描述》 不相交集ADT Mark Allen Weiss 超有爱的并查集~ 数据结构与算法分析 - 9 - 并查集(不相交集) 标签:rest 两种 入队 策略 com tail lse 意义 pat 原文地址:https://www.cnblogs.com/CofJus/p/13024352.html等价关系
并(Union) 查(Find)
基本数据结构
不相交集合森林(Disjoint Set Forest)
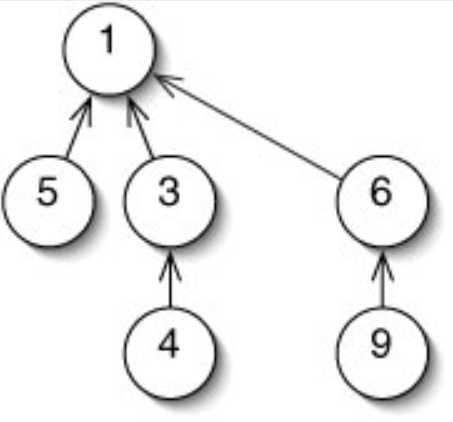
并查集的初步实现
const int maxn = 1000;
int pre[maxn];
void init(int n)
{
for(int i = n; i > 0; i--)
pre[i] = 0;
}
int find(int x)
{
if(0==pre[x])
return x;
else
return find(pre[x]);
}
//y->x,并非最优
void setUnion(int x, int y)
{
x = find(x);
y = find(y);
pre[y] = x;
}求并策略
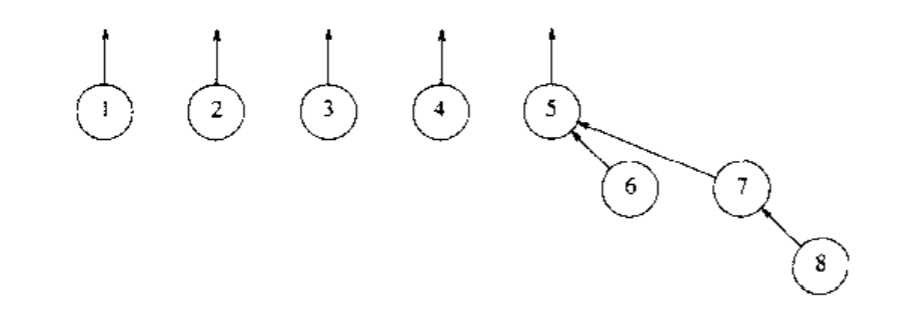
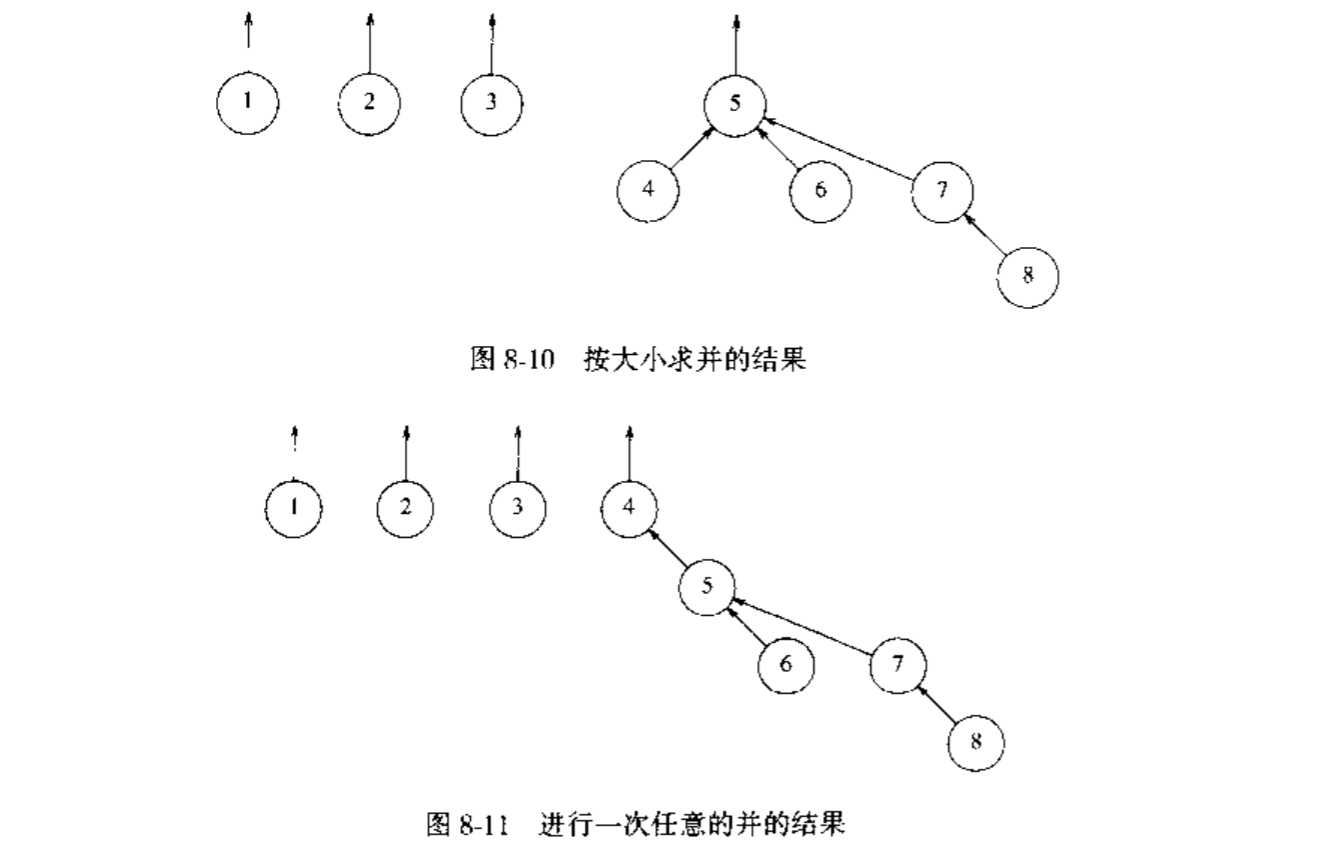
按大小求并
void init(int n)
{
for(int i = n; i > 0; i--)
pre[i] = -1;
}
void setUnion(int x, int y)
{
x = find(x);
y = find(y);
//负数,值小的树更大
if(pre[x]pre[y])
{
pre[x]+=pre[y];
pre[y]=x;
}
else
{
pre[y]+=pre[x];
pre[x]=y;
}
}按秩求并
void init(int n)
{
for(int i = n; i > 0; i--)
pre[i] = 0;
}
void setUnion(int x, int y)
{
x = find(x);
y = find(y);
//负数,值小的树更高
if(pre[x]pre[y])
pre[y]=x;
else
{
if(pre[x]==pre[y])
pre[x]--;
pre[y] = x;
}
}
路径压缩
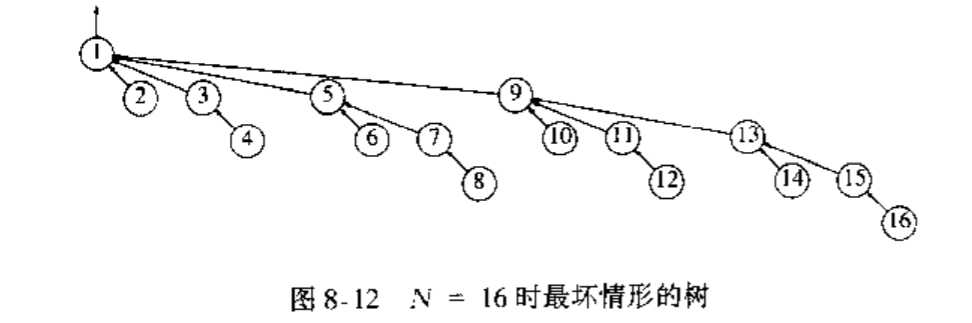
int find(int x)
{
if(0==pre[x])
return x;
//顺便将x设为根的子节点
else
return pre[x] = find(pre[x]);
}
例题
文章标题:数据结构与算法分析 - 9 - 并查集(不相交集)
文章链接:http://soscw.com/index.php/essay/38900.html