使用机器学习数据集构建销售预测Web应用程序
2020-12-28 20:34
标签:atp orm variable boot building 数据 如何使用 ring lazy 作者|Saurabh Mhatre 互联网上有很多资源可以找到关于机器学习数据集的见解和训练模型,但是关于如何使用这些模型构建实际应用程序的文章很少。 因此,今天我们将通过首先使用hackathon中的数据集来训练视频游戏销售预测模型,然后使用经过训练的模型来创建一个基本应用程序,根据用户输入为我们提供销售预测来学习此过程。 本文分为多个部分,你可以一个接一个地学习,而不必一口气完成它。从我第一次选择数据集以来,我花了整整一周的时间来完成应用程序。因此,请花时间专注于学习构建应用程序的各个方面,而不是只注意最终产品。 我们将使用在Machine Hack网站上运行的视频游戏销售预测hackathon中的数据集。首先,在MachineHack上创建一个帐户,然后在此链接上注册hackathon。 注册后,转到数据标签并下载zip文件,该文件将包含三个文件,即训练,测试和样品提交。 下一步将在Google Colab Notebook中介绍,你可以从以下链接打开和克隆该Notebook: 或者如果你想在本地或其他平台上下载并运行该Notebook,请从以下GitHub链接下载该Notebook:Jupyter Notebook链接 Notebook电脑的第一部分简要介绍了问题陈述。通过运行下面显示的下一个代码单元,上传我们收到的文件 在下一个代码单元中,我们导入所需的python包。它们中的大多数已预先安装在Google Colab中,因此无需安装它们中的任何一个。 因为我们无法在hackathon结束后提交测试数据进行评估,因此本文其余部分仅将数据用于Train.csv。请记住,Train.csv的行数少于通常用于正确训练模型的行数。但是,出于学习目的,我们可以使用行数较少的数据集。 现在让我们深入研究解决此机器学习问题… 步骤1:识别目标和独立特征 首先,让我们将Train.csv导入pandas数据框中,然后运行 从数据框中,我们可以看到目标列是 步骤2:清理资料集 首先,我们通过运行 我们可以看到数据集中没有空值。接下来,我们可以通过运行以下命令删除不必要的列 接下来,我们可以使用 步骤3:探索性数据分析 描述性统计信息 使用 在EDA部分中,我们使用 从EDA获得的一些见解是: PS3平台的销售额最高。之后是Xbox360: 动作类别的销售额最高,难题类别的销售额最低 2007年到2011年的销售额最高: 通常,我们在EDA之后进行特征工程或特征选择步骤。但是,我们的功能较少,着重于实际使用模型。因此,我们正在朝着下一步迈进。但是,请记住, 步骤4:建立模型 由于我们具有许多分类功能,因此我们将对数据集使用catboost回归模型。由于catboost可以直接作用于分类特征,因此跳过了对分类特征进行标签编码的步骤。 首先,我们使用 然后,我们创建一个分类特征列表,将其传递给模型,然后将模型拟合到训练数据集上: 步骤5:检查模型的准确性 首先,我们根据测试数据集创建真实的预测: 接下来,我们在测试数据集上运行训练良好的模型以获取模型预测并检查模型准确性 我们的RMSE值为1.5,这相当不错。有关在出现回归问题时准确性指标的更多信息,可以参考本文。 如果你想进一步改善模型或尝试组合各种模型,可以在本文中参考本次hackathon获胜者的方法: 步骤6:将模型保存到pickle文件中 现在,我们可以将模型保存到pickle文件中,然后将其保存在本地: 保存pickle文件后,你可以从Google Colab Notebook文件部分的左侧边栏中下载并保存在本地 额外提示 我们可以通过向模型添加更多数据来改善模型预测。我们可以使用一些在Kaggle上的相关的数据集。Kaggle:https://www.kaggle.com/gregorut/videogamesales 我们可以使用组合模型的堆栈来进一步提高模型效率。 如果你已完成此步骤,请轻拍一下自己的背,因为我们刚刚完成了项目的第一个主要部分。休息一会儿,拉伸一下,然后开始本文的下一部分。 我们将使用Python Flask创建后端API。 因此,首先在本地创建一个名为server的文件夹。另外,如果还没有,请在你的计算机上安装Python和pip软件包管理器。 接下来,我们需要在文件夹中创建一个虚拟环境。我在Linux上使用python3,因此我创建虚拟环境的命令为: 你可以在本文中查看适用于你的OS和Python版本的命令:Python venv:https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/ 接下来,我们将通过运行以下命令激活虚拟环境: 完成后,我们需要安装Flask pip软件包: 接下来,使用你喜欢的文本编辑器在服务器文件夹中创建一个名为“app.py”的文件,并添加以下代码以创建基本的API: 现在打开终端并运行 你应该在浏览器中打印出Hello World。如果不是,则在启动API时检查API是否在其他端口上运行或在终端上打印错误。 我们将调用 接下来,我们需要使用以下命令安装catboost,pandas和Flask-Cors pip软件包: 接下来,将我们在第1部分末尾下载的经过训练的模型的pickle文件(finalized_model.sav)复制到服务器文件夹中。 现在,使用以下代码更新 app.py: 在第6行中,我们将训练后的模型导入到我们的python文件中。 在第10行,我们初始化CORS模块以允许来自客户端API调用的请求。 在第11行,我们定义了一个错误处理程序,如果从服务器访问了任何未处理的异常或未定义的路径,它将发送错误响应。 对我们来说,主要的兴趣点是从第19行定义的get_prediction POST API。get_prediction方法是我们从客户端获取数据并提供响应的销售预测。 在第24行,我们将来自API请求的数据转换为pandas数据框。现在,我们的模型期望列以特定顺序提供正确的响应。因此,在第25行中,我们指定列顺序。在接下来的步骤中,以所需顺序重新排列列。 在第27行,model.predict用于从模型中获取预测,并将其作为响应传递给客户端。在这一步,我们准备好在本地使用该API。我们可以通过发送POST-API调用来测试Postman客户端中的API,如截图所示: 你可以在上述请求的正文部分中添加一个JSON示例,可以在代码Github-gist中找到。 确保在主体和主体类型中选择raw和JSON选项(如屏幕截图所示),并在请求类型中选择POST。 如果在此步骤之前一切正常,那么恭喜你,你现在有了一个后端API,该API可根据输入参数根据经过训练的模型进行预测。 额外提示 在后端设计中不建议在单个文件中编写API,我们可以将路径和模型导入分隔到不同的文件夹中,以使代码更具模块化。如果将来引入其他API,这也将使我们能够以可管理的方式扩展代码。 在这一点上,我们可以再次休息一下,确保收藏了本文,以便轻松地重新开始本项目的下一部分。 到目前为止,我们的API在本地工作,但我们需要将其部署在远程服务器上,以供其他地方使用。为此,我们将使用Heroku作为我们的API托管平台。 我主要参考了来自stackabuse 的文章,将其部署到Heroku。我们将简要介绍这些步骤,但是如果你卡在了其中某个步骤,请在此处参阅原始文章: 首先,我们使用terminal命令安装gunicorn: 接下来,运行下面的命令将所有已安装的pip包,存储到require.txt文件: 你可以参考此处上传的requirements.txt文件以供参考: 接下来,Procfile使用以下代码在服务器文件夹中创建一个名称为 现在,在Heroku网站上注册,在该网站上创建一个应用,然后按照原始文章中的说明安装Heroku CLI 。 接下来,通过运行以下命令从本地终端登录Heroku: 使用以下命令添加你的Heroku应用git参考: 现在,使用以下命令将代码推送到Heroku: 在运行上述命令的最后,你将在终端输出中获得API URL,现在我们可以使用该URL从客户端进行调用。此时,我们还可以从PostMan应用程序发送API请求,以查看我们是否正确收到了与步骤2末尾所述类似的响应。 到目前为止的代码库可以在以下Github存储库中找到 现在,我们在服务器上托管了一个正常工作的API。如果一切正常,那么我们可以继续开发客户端应用程序。如果遇到任何问题,请在评论部分中提及你的问题。 我们将需要在我们的计算机上正确安装和设置Node.js。因此,请先下载并安装适用于你相关操作系统和系统的Node.js,然后再继续进行操作。另外,建议安装yarn管理器:yarn 安装 现在,在上一步中创建frontend的服务器文件夹外部创建一个新文件夹,并从终端进入该frontend文件夹内部。 接下来,我们将创建一个新的react应用程序,并通过在终端中运行以下命令来启动它: 你应该在浏览器中看到默认打开的浏览器选项卡,以及react.js默认模板应用程序。现在我们需要在我们最喜欢的编辑器中打开该项目(我正在使用VSCode),并开始进行更改以构建前端应用程序。 首先,我们需要在应用程序公共文件夹中的index.html文件中导入相关的引导程序文件。 我们需要按照bootstrap文档提供的说明在index.html文件中添加文件,如下所示: 我们的最终用户界面是集合下拉菜单项,其中单个项如下所示: 我们将在src文件夹中创建一个名称为optionsSources.json的JSON文件。JSON文件中的每个条目都包含以下对象: 下拉菜单中显示的选项位于options数组中,下拉菜单选项左侧显示的图标和标签位于icon和dropDownPlaceholder项。我们需要创建多个这样的下拉列表,因此要添加的完整JSON文件如以下文件所示: 接下来,我们需要在我们的应用程序中实现下拉组件。在src文件夹中创建一个名为components的文件夹,并在components文件夹中创建一个名为OptionSelection.js的文件 我们将编写一个功能组件,该组件返回一个下拉项,如下所示: 在上面的组件中,我们itemKey从第3行的父组件中获得prop(param)值。我们假设itemKey从父组件接收的是CONSOLE。在第4行和第5行,我们首先提取显示在下拉菜单左侧的标题和图标。然后,根据Boostrap文档在创建下拉列表时,在第6行的返回函数中使用HTML标签。 接下来,我们需要实现renderOptionsDrop在返回函数中定义的函数,如下所示: 在第5行,我们从optionSources JSON对象获取特定项的 然后在第6行,我们使用map函数迭代数组并显示下拉选择项。我们必须在第10行使用 然后实现onClick处理程序中的函数 我们在第1行输入了useState hook。它是一个内部函数,允许我们使用状态变量的概念动态更新值。关于这个函数的更多信息可以在这里找到: 在第7行,我们更新下拉列表的选定选项。在第8行中,我们将选择的值传递回父函数以进行进一步处理。 这个组件的完整代码可以在这里找到:https://github.com/codeclassifiers/video-salesprediction-frontend/blob/master/src/components/ConsoleSelection.js 然后我们在src文件夹中导入此选项并对服务器进行API调用。完整的代码可以在这里找到: 然后在 我们正在使用Axios npm模块对后端Heroku服务器进行POST API调用。确保在process.env.REACT_APP_HEROKU_SERVER_URL占位符的第8行上添加自己的Heroku服务器URL,以接收来自服务器API的响应。 最好将API URL变量保存在 在此处找到Github上的前端应用程序的完整资源: 这使我们有了在线部署Web应用程序的最后一步。因此,请耐心一些,让我们开始项目的最后一步。 Netlify是一个可以轻松在线部署静态网站的平台。在部署使用createreact app模块生成的应用程序时,它有一个非常简单的过程。我们将利用此服务在线托管我们的web应用程序。 首先,我们需要在Github上创建一个帐户。 然后,我们需要将前端文件夹上传到Github存储库。我们可以按照官方文档中显示的步骤将项目部署到Github:官方文档(https://docs.github.com/en/github/importing-your-projects-to-github/adding-an-existing-project-to-github-using-the-command-line) 一旦该项目在GitHub上进行部署,通过遵循以下官方文档即可简单,直接地完成netlify的过程:Netlify Deploy(https://www.netlify.com/blog/2016/09/29/a-step-by-step-guide-deploying-on-netlify/) 如果你已在上一步中将环境变量用于服务器URL,请确保如本文档所示将其添加到netlify dashboard中。 最后,我们将提供一个如下所示的网络应用程序: 额外提示 老实说,上面的UI非常简单。它没有很好的配色方案(主要是因为像我这样的开发人员不是优秀的设计师)。你可以改善设计并调整CSS,以更好地查看网页。 这样就完成了从机器学习hackathon数据集创建销售预测Web应用程序的过程。 如果你在完成项目的过程中没有遇到任何麻烦,那么你的分析和编码技能将受到赞誉。但是,如果你确实遇到了困难,那么,像往常一样,可以寻求Google和StackOverflow的帮助。如果你仍然无法找到解决问题的方法,请随时在评论中提及它们或在LinkedIn或Twitter上与我联系。 原文链接:https://www.analyticsvidhya.com/blog/2020/08/building-sales-prediction-web-application-using-machine-learning-dataset/ 欢迎关注磐创AI博客站: sklearn机器学习中文官方文档: 欢迎关注磐创博客资源汇总站: 使用机器学习数据集构建销售预测Web应用程序 标签:atp orm variable boot building 数据 如何使用 ring lazy 原文地址:https://www.cnblogs.com/panchuangai/p/13830645.html
编译|Flin
来源|analyticsvidhya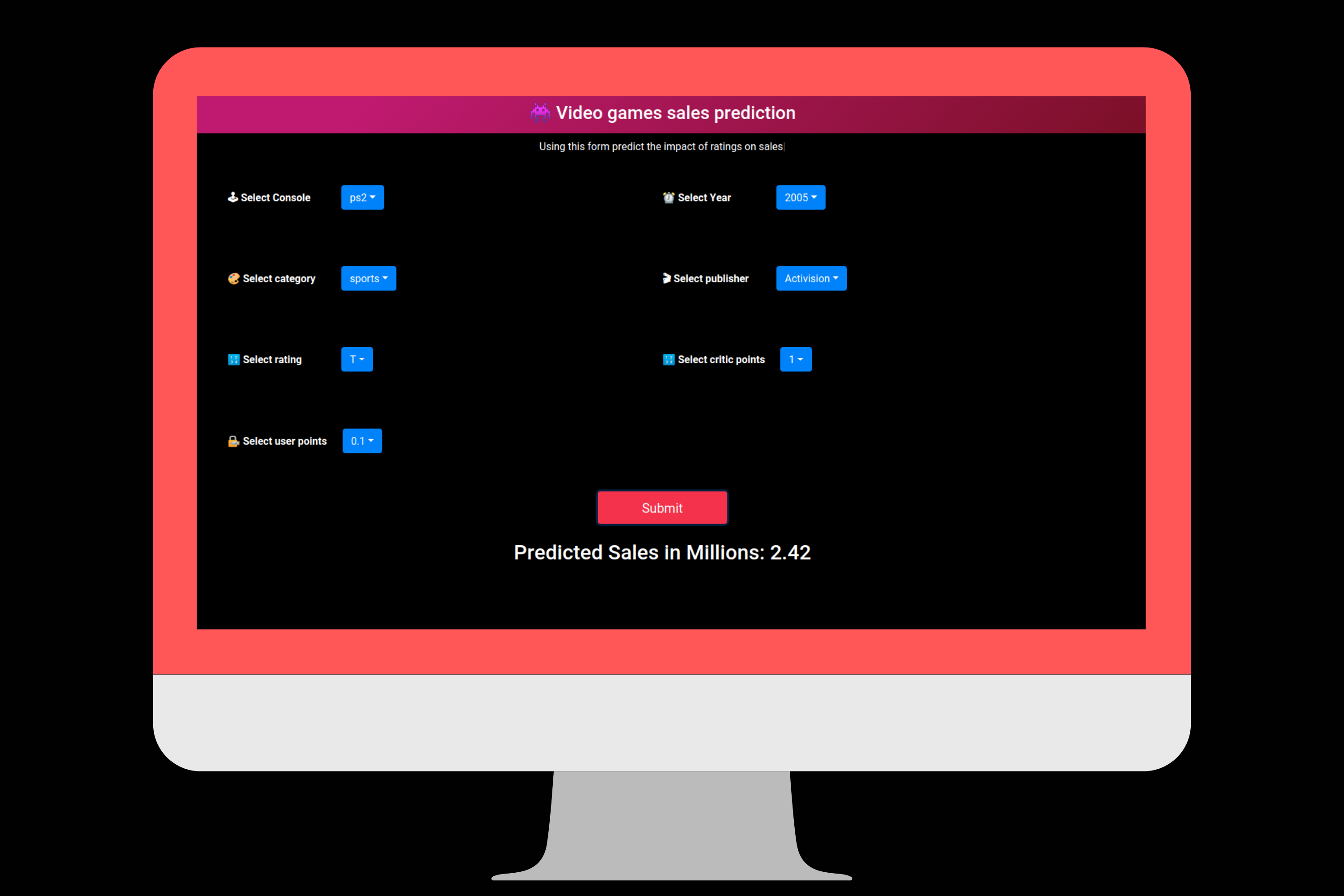
介绍
第1部分:生成模型
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print(‘User uploaded file "{name}" with length {length} bytes‘.format(
name=fn, length=len(uploaded[fn])))
df.head()以查看数据集中的列。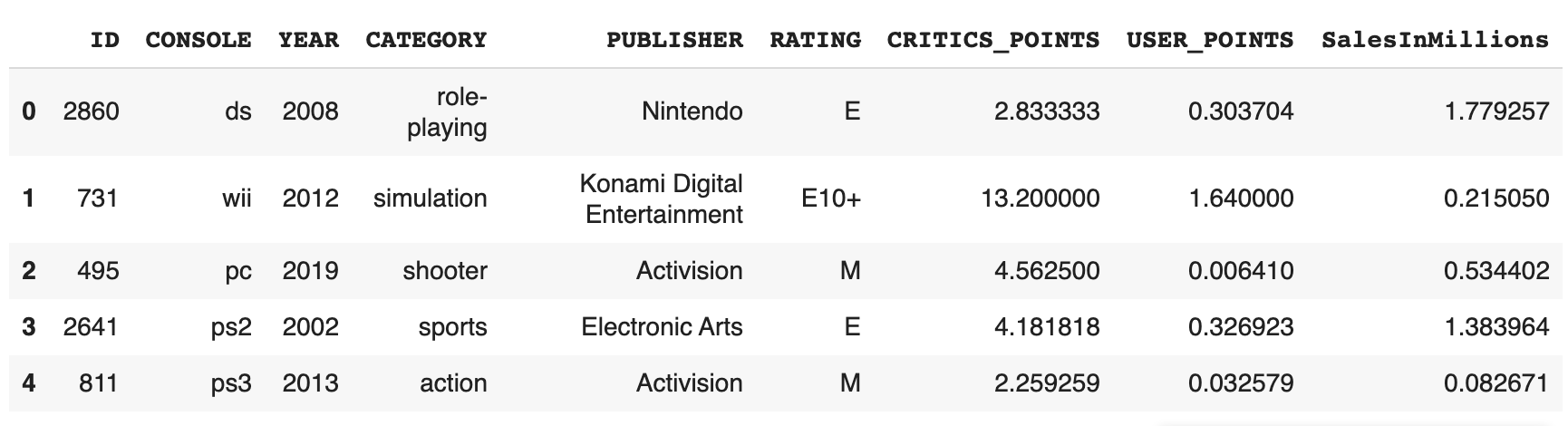
SalesInMillions,其余列是独立特征input.isnull().sum()命令检查null值。input.isnull().sum()
#Output:
ID 0
CONSOLE 0
YEAR 0
CATEGORY 0
PUBLISHER 0
RATING 0
CRITICS_POINTS 0
USER_POINTS 0
SalesInMillions 0
dtype: int64
ID,因为它在目标销售中不起作用:input = input.drop(columns=[‘ID‘])train_test_split命令将数据框分为训练和测试数据集:train, test = train_test_split(input, test_size=0.2, random_state=42, shuffle=True)
df.shape命令我们可以找到数据集中的总行数,并且可以使用命令df.nunique()在每个列中查找唯一值。CONSOLE 17
YEAR 23
CATEGORY 12
PUBLISHER 184
RATING 6
CRITICS_POINTS 1499
USER_POINTS 1877
SalesInMillions 2804
pandas profiling和matplotlib包生成各种列的图形,并观察它们与目标列的关系。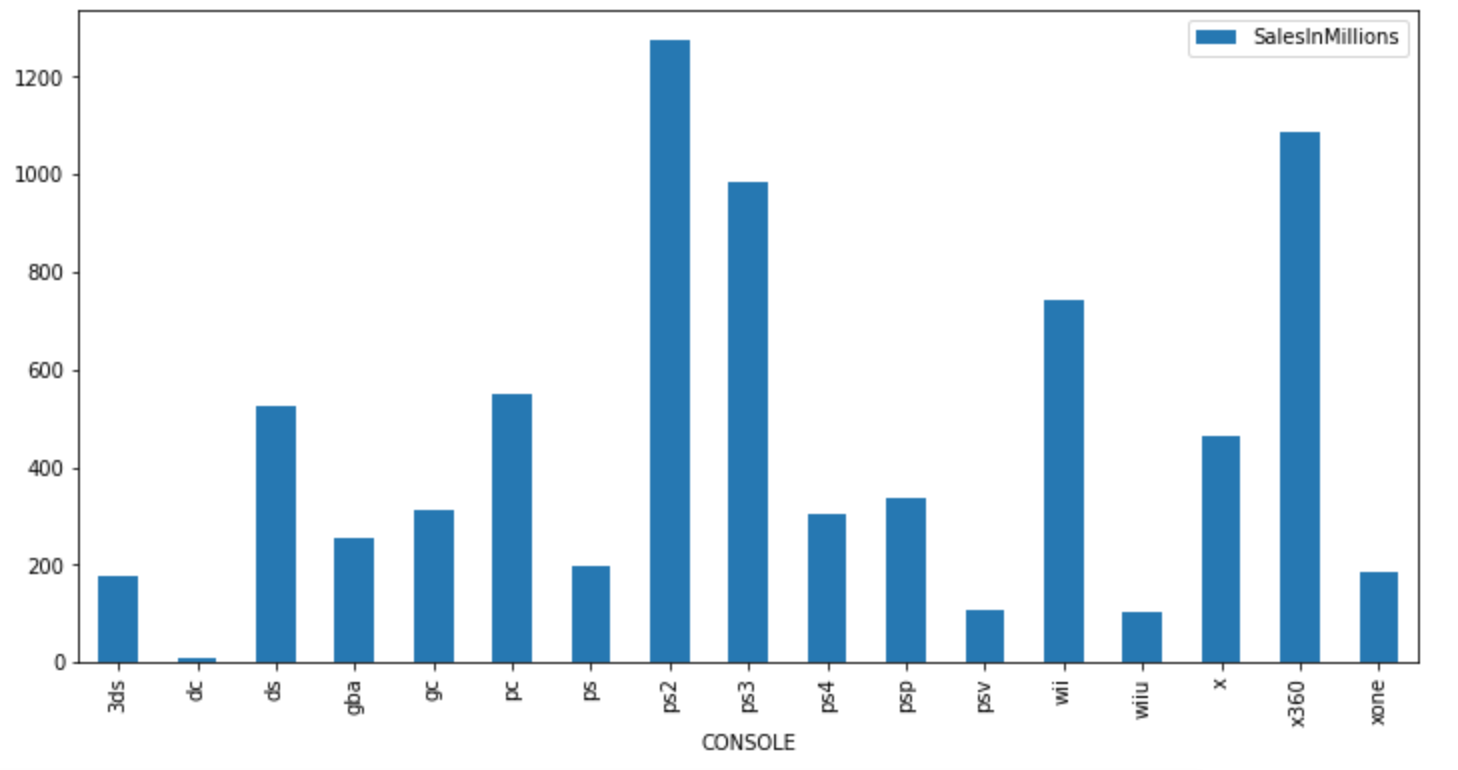
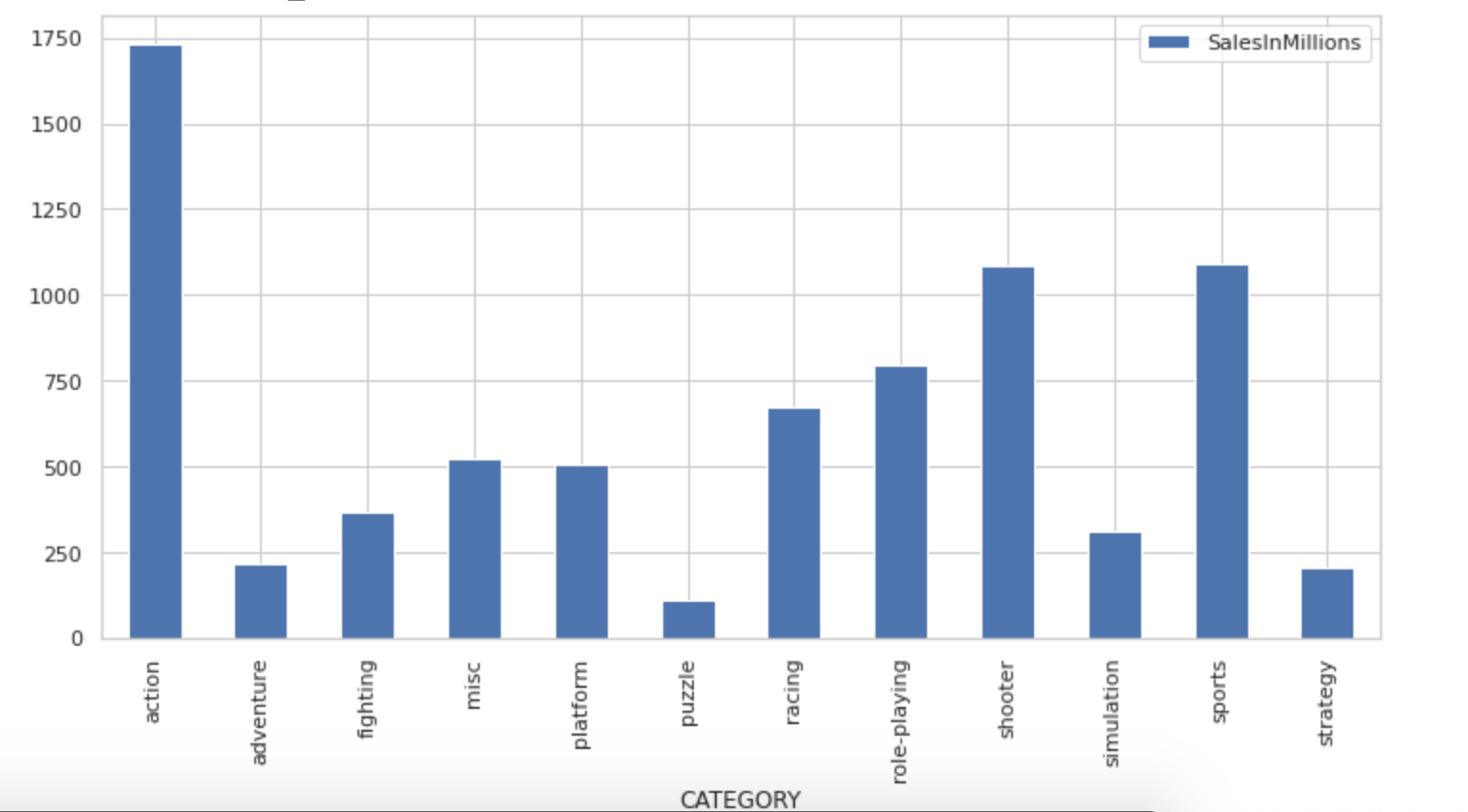
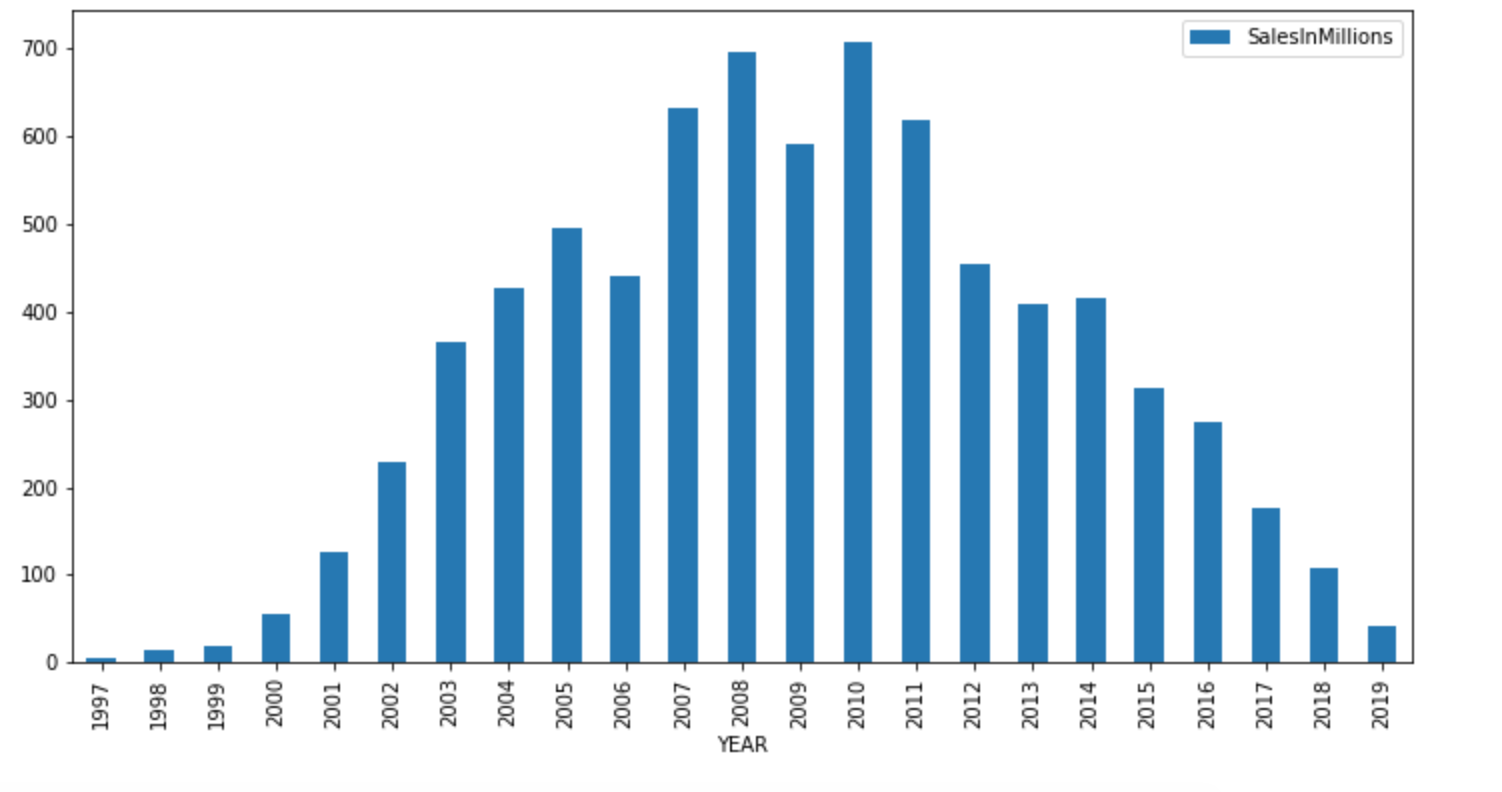
USER_POINTS和CRITICS_POINTS列可用于派生其他功能。pip install命令安装catboost软件包。import catboost as cat
cat_feat = [‘CONSOLE‘,‘CATEGORY‘, ‘PUBLISHER‘, ‘RATING‘]
features = list(set(train.columns)-set([‘SalesInMillions‘]))
target = ‘SalesInMillions‘
model = cat.CatBoostRegressor(random_state=100,cat_features=cat_feat,verbose=0)
model.fit(train[features],train[target])
y_true= pd.DataFrame(data=test[target], columns=[‘SalesInMillions‘])
test_temp = test.drop(columns=[target])
y_pred = model.predict(test_temp[features])
from sklearn.metrics import mean_squared_error
from math import sqrt
rmse = sqrt(mean_squared_error(y_true, y_pred))
print(rmse)
#Output: 1.5555409360901584
import pickle
filename = ‘finalized_model.sav‘
pickle.dump(model, open(filename, ‘wb‘))

第2部分:根据模型创建后端API
python3 -m venv server。source server/bin/activatepip install -U Flaskfrom flask import Flask, jsonify, make_response, request, abort
app = Flask(__name__)
@app.route("/")
def hello():
return "Hello World!"
if __name__ == "__main__":
app.run()
python3 app.py以启动服务器。这将主要在5000端口上启动服务器。为了测试API,请在浏览器中打开此链接:http://localhost:5000/POST API,因此最好在继续进行之前安装Postman工具。使用此工具将向服务器发送POST请求。pip install catboost pandas Flask-Corsfrom flask import Flask, jsonify, make_response, request, abort
import pandas as pd
import catboost
import pickle
from flask_cors import CORS,cross_origin
model = pickle.load(open( "finalized_model.sav", "rb"))
app = Flask(__name__)
app.config[‘CORS_HEADERS‘] = ‘Content-Type‘
cors = CORS(app)
@app.errorhandler(404)
def not_found(error):
return make_response(jsonify({‘error‘: ‘Not found‘}), 404)
@app.route("/")
def hello():
return "Hello World!"
@app.route("/get_prediction", methods=[‘POST‘,‘OPTIONS‘])
@cross_origin()
def get_prediction():
if not request.json:
abort(400)
df = pd.DataFrame(request.json, index=[0])
cols=["CONSOLE","RATING","CRITICS_POINTS","CATEGORY","YEAR","PUBLISHER","USER_POINTS"]
df = df[cols]
return jsonify({‘result‘: model.predict(df)[0]}), 201
if __name__ == "__main__":
app.run()
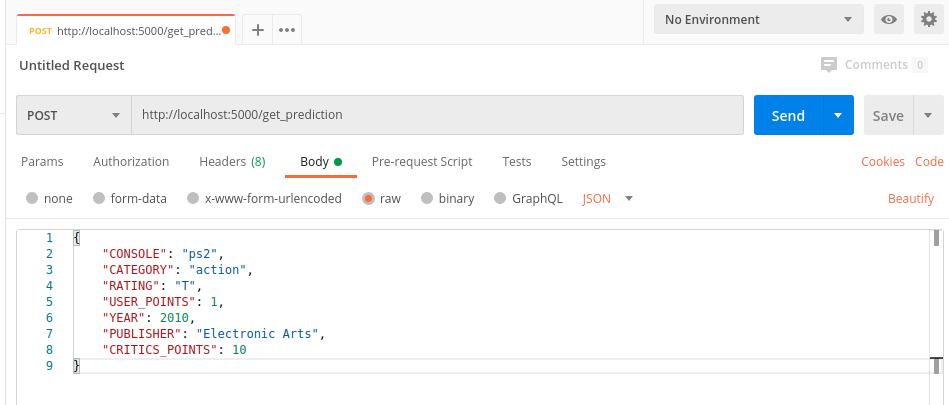
第3部分:将后端API部署到Heroku
pip install gunicornpip freeze > requirements.txt
Procfile的文件:web: gunicorn app:appheroku login -iheroku git:remote -a {your-project-name}git push heroku master
第4部分:使用react和bootstrap创建客户端应用程序
npx create-react-app sales-prediction-app
cd sales-prediction-app
npm start
...
...
...
...
...
{
"CONSOLE": {
"options": [
"ps2","x360","ps3","pc"
],
"icon": "???",
"dropDownPlaceholder": "Select Console"
}
}
import React,{ useState } from ‘react‘;
import optionSources from ‘../optionsSources.json‘;
function OptionSelection({itemKey, setOptionInObject}) {
const title = optionSources[itemKey].dropDownPlaceholder;
const icon = optionSources[itemKey].icon;
return(
import optionSources from ‘../optionsSources.json‘;
function OptionSelection({itemKey, setOptionInObject}) {
...
const renderOptionsDropdown = () => {
const selectionOptions = optionSources[itemKey].options;
return selectionOptions.map((selectionOption, index)=>{
return (
options数组,并将其存储在selectionOptions变量中。onClick函数更新下拉项的选定值。handleDropDownSelection,如下所示:import React,{ useState } from ‘react‘;
...
function OptionSelection({itemKey, setOptionInObject}) {
const [currentSelectedOption, setSelectedOption] = useState(null);
const handleDropDownSelection = (consoleOption) => {
setSelectedOption(consoleOption)
setOptionInObject(itemKey, consoleOption)
}
...
}
handleInputSubmission函数中对后端进行API调用,如下所示:import React, {useState} from ‘react‘;
import axios from ‘axios‘;
function App() {
...
const handleInputSubmission = () => {
if(selectedObject && Object.keys(selectedObject).length === 7) {
...
axios.post(process.env.REACT_APP_HEROKU_SERVER_URL, selectedObject)
.then(function (response) {
setPredictionLoading(false)
setModelPrediction(response.data.result)
})
.catch(function (error) {
setPredictionLoading(false)
setRequestFailed("Some error ocurred while fetching prediction")
});
} else {
setRequestFailed("Please select all fields before submitting request")
}
}
}
.env文件中,然后在部署环境中进行设置。可以在这里找到更多详细信息:
第5部分:将客户端应用程序部署到Netlify
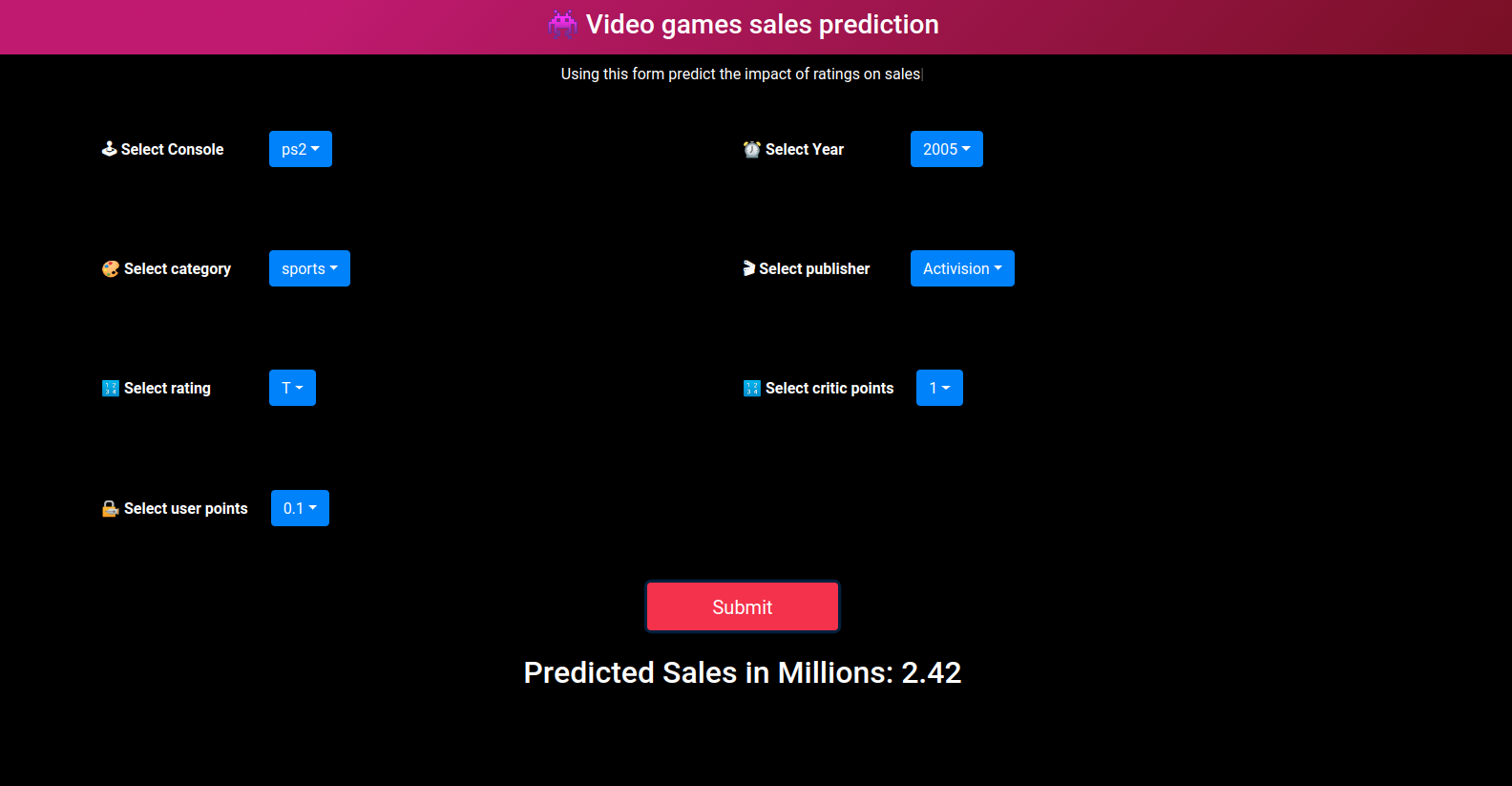
尾注
http://panchuang.net/
http://sklearn123.com/
http://docs.panchuang.net/
上一篇:Nginx禁止html等缓存
文章标题:使用机器学习数据集构建销售预测Web应用程序
文章链接:http://soscw.com/index.php/essay/38909.html