Spark学习(二)win10部署Hadoop+Spark
2020-12-29 00:28
标签:配置 怎么 lin mil 启动 googl strong 文件管理 blog 基础只需要配置core-site.xml和hdfs-site.xml就行。 参考: https://www.jianshu.com/p/aa8cfaa26790【这个教程的core-site.xml和hdfs-site.xml的内容弄反了,交换一下就行】 http://dblab.xmu.edu.cn/blog/install-hadoop/【这是Linux的】 https://blog.csdn.net/Sylarjyd/article/details/91038732【这是包括yarn的配置】 命令行:hadoop namenode -format 启动:进入sbin目录,双击start-dfs.cmd【仅启动dfs】或者start-all.cmd【启动所有,包括yarn】 命令行:jps查看进程 通过http://127.0.0.1:8088/即可查看集群所有节点状态 https://blog.csdn.net/u011513853/article/details/52865076 查看:http://localhost:4040/jobs/ 我一个单机win10怎么弄另外一个master?!!!百度TMD两天,不如Google一下,我也是醉了!!我发誓,一定养成Google习惯,不是非要英语,而是搜索引擎不行!! ps:spark提交作业,支持多种 后来才发现,官方文档https://spark.apache.org/docs/1.6.0/submitting-applications.html也有一丢丢提示,却没给怎么设置! 原答案:http://damn.amsterdam/sparkonwindows/ 效果: Spark学习(二)win10部署Hadoop+Spark 标签:配置 怎么 lin mil 启动 googl strong 文件管理 blog 原文地址:https://www.cnblogs.com/sybil-hxl/p/13297635.html1.Hadoop
(1)安装配置
(2)开启Hadoop

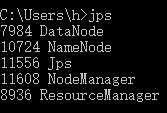
(3)查看
访问http://localhost:9870/即可查看Hadoop文件管理页面。
2.Spark
(1)安装
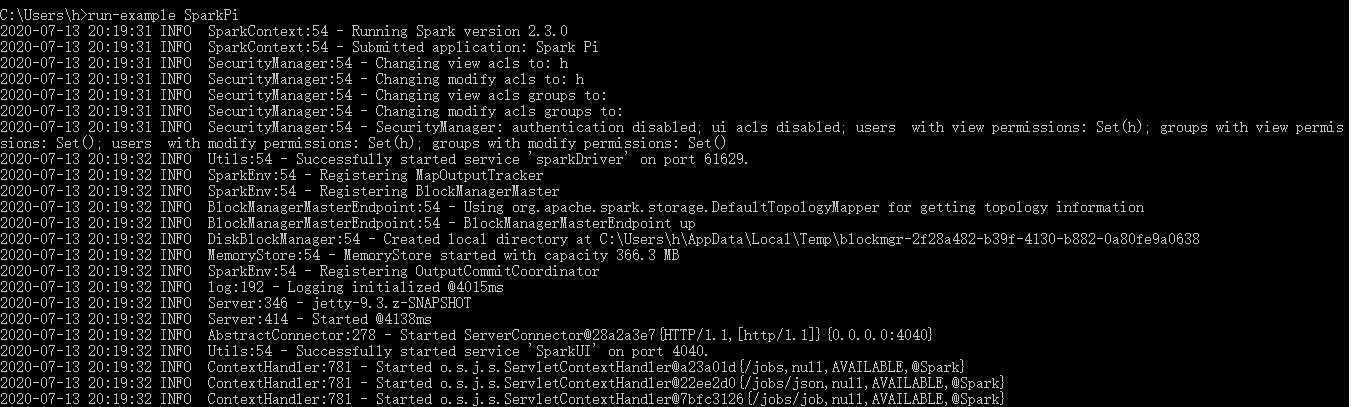
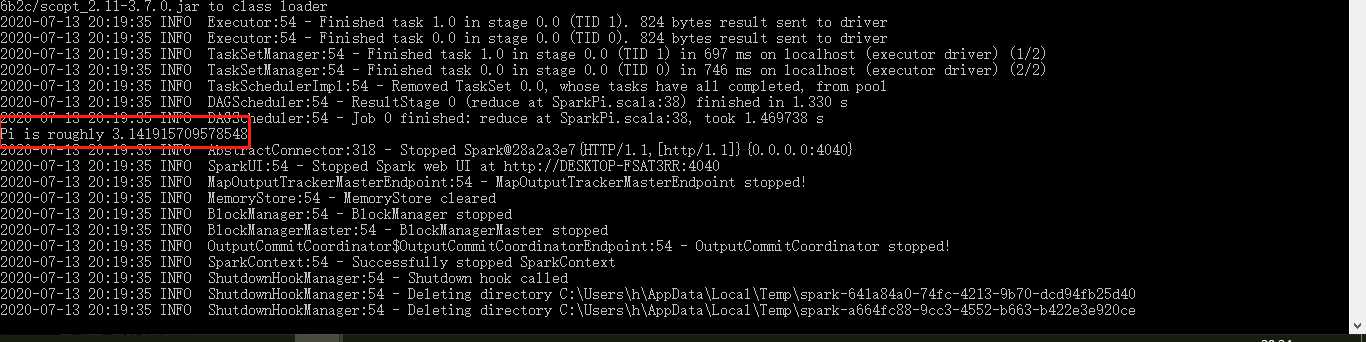
(2)运行Spark自带的例子:run-example SparkPi
(3)启动master和slave
cluster manage 类型:Standalone,Apache Mesos,Hadoop YARN ,Kubernetes,这里采用Standalone的伪分布式。 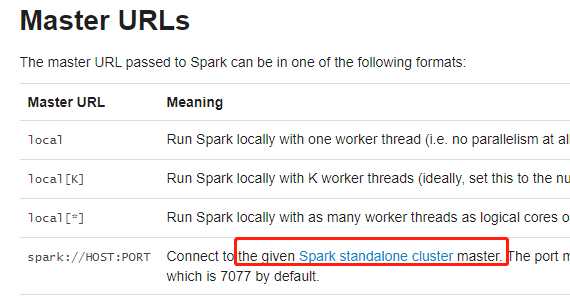
没有master,新开一个cmd窗口,造一个master,系统会给你分配一个master IP和端口
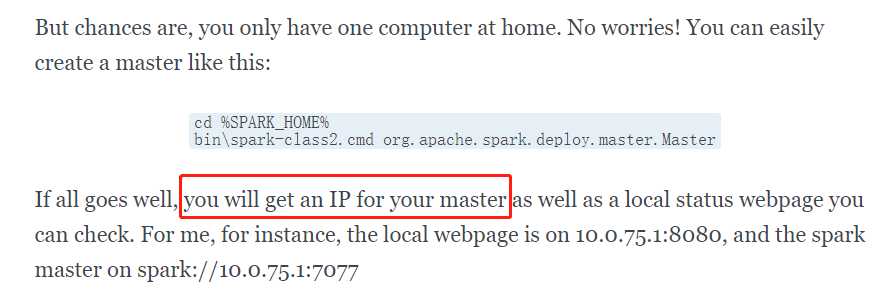
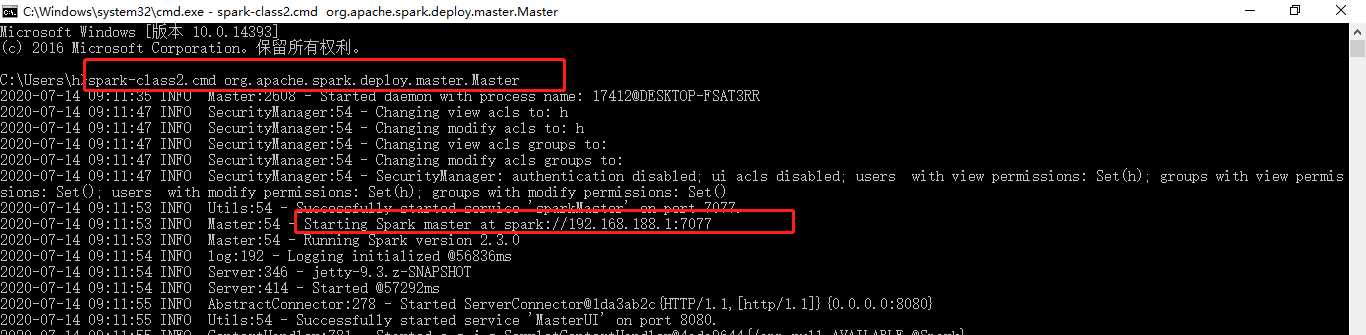
再开一个cmd窗口,造一个slave
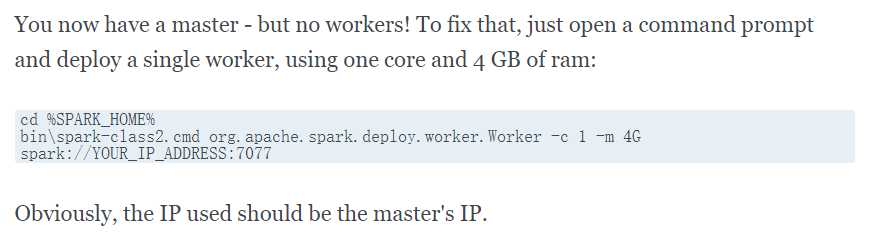
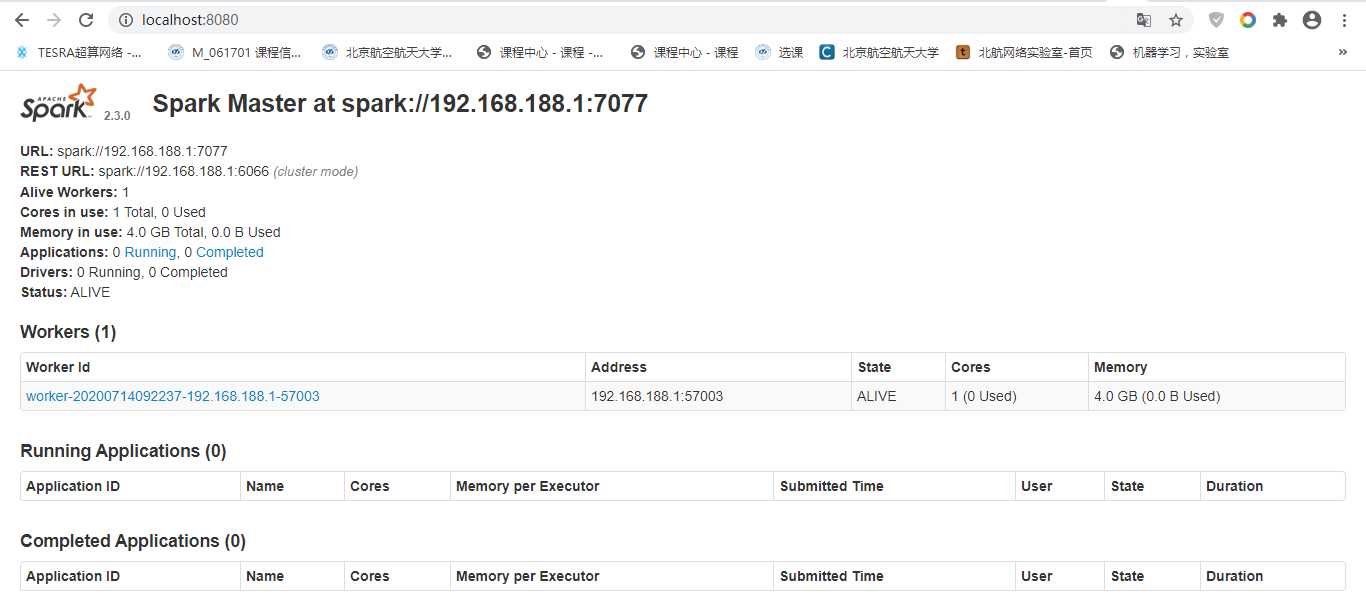
查看spark master的web ui:http://localhost:8080/
下一节:
Spark学习(三)Spark实验部分
文章标题:Spark学习(二)win10部署Hadoop+Spark
文章链接:http://soscw.com/index.php/essay/38947.html