超一流 | 从XLNet的多流机制看最新预训练模型的研究进展
2020-12-29 18:31
标签:去除 期望 语言 评估 连接 不同的 inpu art 不同 导读 ELMo, GPT and BERT 然而,MLM 虽然解决了传统 language model 仅能看到单向文本信息的问题,但不得不在预训练阶段引入了不低比例的 [MASK] 掩码 ID 占位。这样在语言模型学习中就存在信息丢失(被掩码的 token 彼此不可见)。同时,MLM 的样本构造方式与 fine-tuning 阶段的训练样本存在 gap,可能影响下游任务的使用效果。针对这两个问题,XLNet 提出了 Permuted Language Modeling(aka PLM) 预训练任务。为了实现PLM,作者提出了双流机制,也因此抛玉引玉,引出了更多应用并改进双流机制的工作。 本篇文章将从XLNet的双流机制讲起,带大家一览近期的优秀工作,它们是百度的ERNIE-GEN、微软的ProphetNet、UniLMv2和MPNet。 XLNet: PLM 和 双流机制 我们可以对 MLM 和 PLM 进行 “unified view” 的描述: 左:MLM、右:PLM (图自 MPNet ) XLNet 双流机制 以下为 PLM 对应输入的 self-attention 掩码矩阵,其中 context (x_1, x_3, x_6) 可以同时被 content/query stream 所有 tokens 可见。 目前,基于多流机制的预训练工作包括语言生成和语言理解两大类。 “超一流”定义 除了 Span-by-span 生成流,ERNIE-GEN 中还包括 Contextual 流(建模待生成语义单元前的上文信息)和一个 Word-by-Word 生成流。因此 ERNIE-GEN 设计了 Mulit-flow Attention 模块来进行多流的联合学习。 ERNIE-GEN: Multi-Flow Attention 实现 ERNIE-GEN 论文地址:https://paperswithcode.com/paper/ernie-gen-an-enhanced-multi-flow-pre-training ERNIE-GEN 开源地址:https://github.com/PaddlePaddle/ERNIE/tree/repro/ernie-gen ProphetNet (微软) ProphetNet 预训练时会同时建模多个不同粒度的语义单元。ProphetNet 把这种同时建模多种粒度的机制叫 “Future N-gram Prediction”。在实际预训练中,出于效果和效率的权衡,ProphetNet 仅使用 1-gram (word) 和 2-gram (bigram) 两个预测流。 此外,ProphetNet 在预训练中除绝对编码 embedding 外,还额外引入了相对位置编码 embedding,不过论文并没有做相关的消融实验。 ProphetNet 论文地址:https://arxiv.org/abs/2001.04063 ProphetNet 开源地址:https://github.com/microsoft/ProphetNet 多流预训练技术之语言理解 UniLMv2 (微软) UniLMv2 在 PLM 建模中还提出了 “partially autoregressive” 机制。传统的 “autoregressive” 预测是 token-by-token 的, “partially autoregressive” 的预测则是包含一个类似 Span 的概念(论文中称之为 block-wise masking),在生成的时候,组成 Span 的 token 是一起预测的,也即在 PLM 中进行 Span-by-Span 预测。 “partially autoregressive” 预测:(x_1, x_3, x_6) -> t=1, predict span by (x_4, x_5) -> t=2, predict token by (x_2) UniLMv2 15% mask 比例里,其中 40% 按 n-gram (span) 进行 mask, 60% 按 token 进行 mask。 UniLMv2 在论文做了非常完善的策略消歧实验,有兴趣的同学可以直接去围观。 UniLMv2 论文地址:https://arxiv.org/abs/2002.12804 UniLMv2 开源地址:https://github.com/microsoft/unilm MPNet (微软) MPNet 的实验做的比较扎实,消融实验分别验证了 “position compensation”([Maskl] 占位)、"output dependency” (PLM) 去除后的下游任务效果。 MPNet 开源地址:https://github.com/microsoft/MPNet 总结 恩,一切都是那么美好。 超一流 | 从XLNet的多流机制看最新预训练模型的研究进展 标签:去除 期望 语言 评估 连接 不同的 inpu art 不同 原文地址:https://blog.51cto.com/15061930/2570319
关注小夕并星标,解锁自然语言处理
搜索、推荐与算法岗求职秘籍
作为 NLP 近两年来的当红炸子鸡,以 ELMo/BERT 为代表的语言预训练技术相信大家已经很熟悉了。简单回顾下 18 年以来几个预训练的重要工作: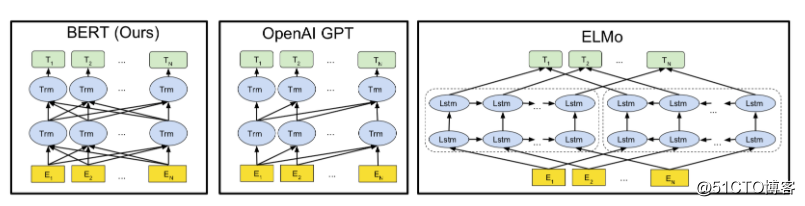
GPT 提出了 NLP 预训练技术使用时应该像 CV 预训练技术一样,在下游任务中通过 fine-tuning 微调的方式进行,在 GLUE 任务榜单上取得了突破。
BERT 在 GPT 的基础上,提出了改进的双向语言模型学习技术 Mask language model。相较传统语言模型,Mask language model (aka MLM) 能够更有效的利用文本的上下文信息,在 transformer 这种依赖全局 attention 表示机制的学习器中,更是如虎添翼。BERT 在通用语言理解评估(GLUE)中大幅刷新了基准水平,一举打破了 11 项 NLP 记录,成为新一代语言预训练技术的大成之作。
BERT 的发表引发了 NLP 学界和业界对语言预训练技术的极大热情,针对 BERT 的一系列改进工作也如雨后春笋般涌出。ERNIE(Baidu)/SpanBert 改进了 MLM 任务的 masking 机制, UniLM 把 GPT/BERT 进行联合训练实现了统一语言预训练,XLM 把 BERT 预训练技术扩展到多语言。
PLM 任务
PLM的做法是将输入的顺序打乱,比如将“夕小瑶的卖萌屋”,变成“屋小夕的瑶萌卖”后进行单向语言模型的训练,这样在预测“萌”时会用到“屋小夕的瑶”的信息,可以认为同时利用了上下文。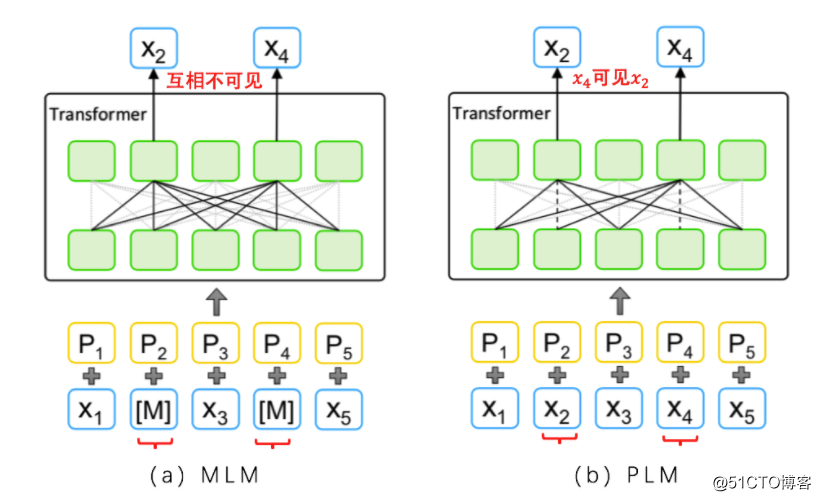
对于 PLM 来讲,给定一段文本 x = (x1,x2,··· ,xn),就有 n 的阶乘中排列组合。在 PLM 的理想世界里,虽然对于特定序列的文本 x_i,语言模型仍然只能看到位于 x_i 之前的单向文本(上文),但考虑 x_i 之前的序列可能包含整段文本的所有组合,因此仍可认为 PLM 是有能力建模上下文信息的。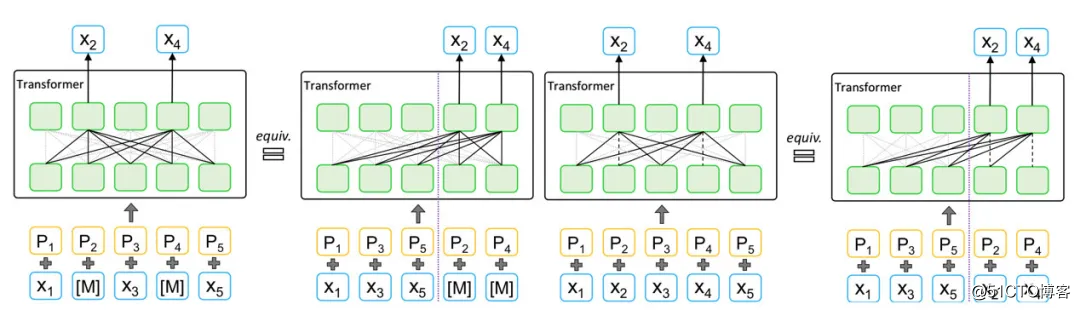
双流机制
XLNet 为了实现 PLM 提出了双流机制。可以看到 PLM 任务的是通过 Query stream 进行学习的。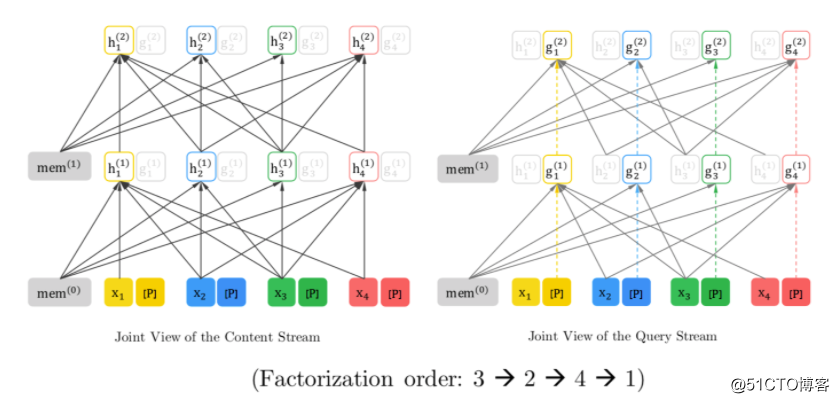
为了更容易理解,我们重新整理 XLNet 的双流输入,在上节 PLM content stream 输入的基础上补充 query stream 输入。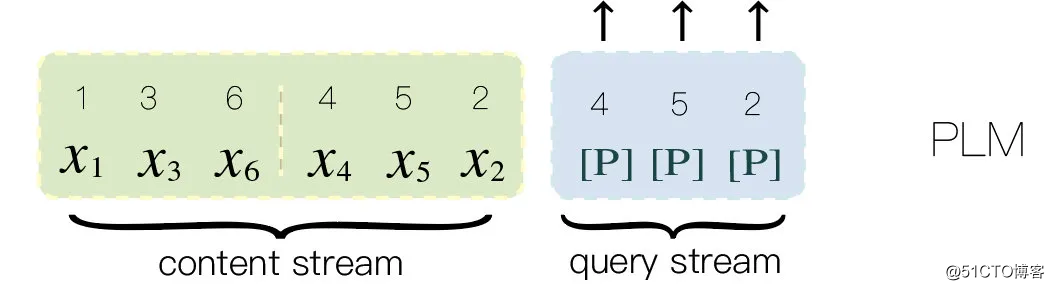
其中 [P] 占位符代表 PLM 中待预测的 Token,预测顺序为 4 -> 5 -> 2。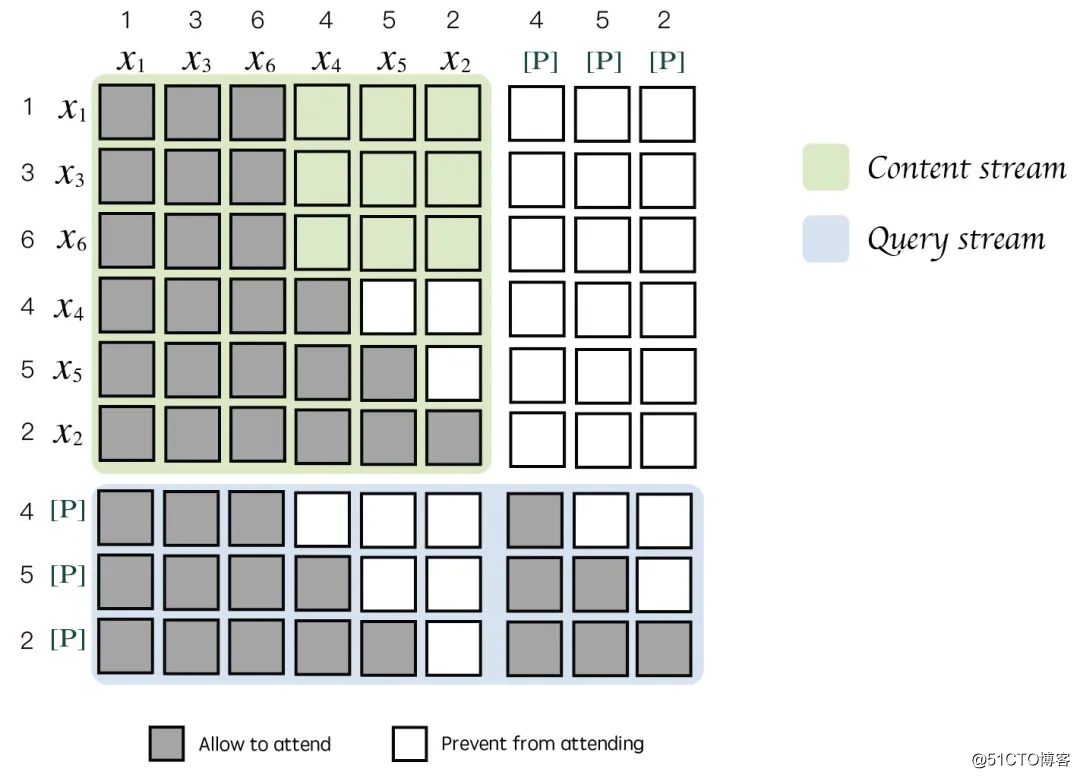
“超一流”预训练模型
XLNet 定义的双流机制,其中 query stream 把“预测任务”和输入文本(content stream)进行了分离,具有很强的通用性。事实上,我们可以定义不同的 query stream 预训练任务,甚至定义多个 query stream (多流)。今年以来,涌现出了不少基于多流机制的预训练工作,其中包括刷新多个语言生成任务 SOTA 的语言生成预训练技术 ERNIE-GEN(百度)和第二代统一语言预训练技术 UniLMv2 (微软)。
现有工作
多流预训练技术之语言生成
ERNIE-GEN (Baidu)
ERNIE-GEN 是百度研究者提出的语言生成预训练模型。ERNIE-GEN 继承了通用语言理解预训练技术 ERNIE1.0 的思想,率先在语言生成预训练中引入了 Span-by-span 生成流,使得预训练模型具有的直接生成 Span 级(bigrams/trigrams)完整语义单元的能力。
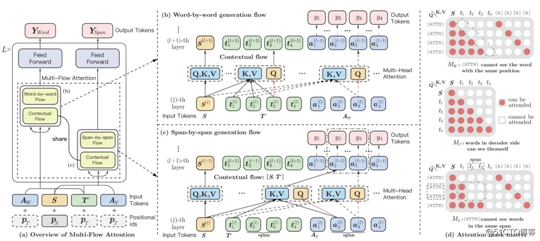
同时,ERNIE-GEN 在预训练阶段即有意识的设计了填充生成 (Infilling generation) 和噪音感知 (Noise-aware) 机制,来缓解 Sequence-to-Sequence 生成框架面临的曝光偏差问题。
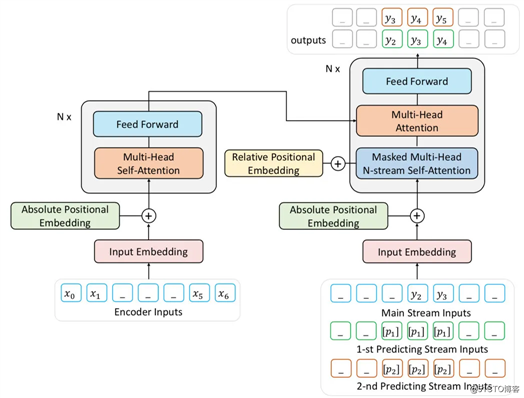
ProphetNet 是微软研究者提出的语言生成预训练模型。与 ERNIE-GEN 类似的,ProphetNet 同样关注了语言生成中模型建模完整语义单元的能力,并提出了 N-gram stream 多流机制来解决该问题。
*
接下来我们介绍基于多流机制的语言理解预训练模型。
UniLMv2 是微软研究者提出的第二代统一语言预训练模型。与 UniLM v1 相比,v2 保留了 v1 版本的 MLM 任务,但把传统 language model 任务替换成了 PLM 任务。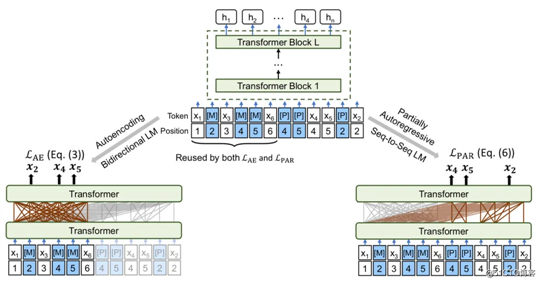
UniLMv2 中,MLM 和 PLM 的联合建模是通过类似 XLNet 的多流机制实现的。
MPNet 也是微软研究者的工作。这篇工作和 UniLMv2 比较神似,都是在探讨如何融合 MLM 和 PLM 这两种任务。MPNet 论文首先从统一的视角对 MLM 和 PLM 进行对比:
MPNet 在输入上保留了 MLM 的掩码 [M] 进行占位,而输出仅进行 PLM 的学习。因此,在输入上 MPNet 和 UniLMv2 是非常相似的,主要的区别是 UniLMv2 的输出也进行 MLM 的学习。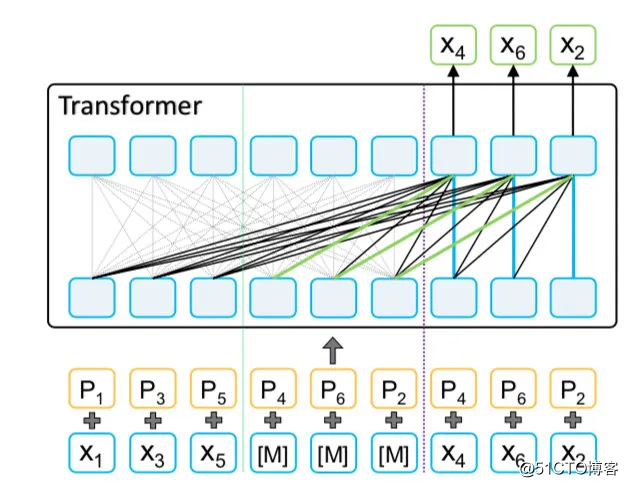
MPNet:输入包含 MLM 的掩码占位、输出仅进行 PLM 的学习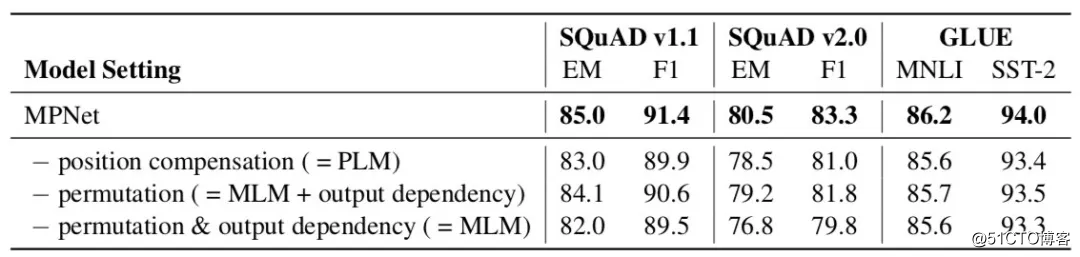
MPNet 论文地址:
https://arxiv.org/abs/2004.09297
BERT 横空出世一年多以来,语言预训练技术不断发展融合。XLNet 提出的 PLM,以及实现 PLM 的双流机制,在更多的语言预训练后起之秀的手中不断发扬光大。
上一篇:aiohttp
文章标题:超一流 | 从XLNet的多流机制看最新预训练模型的研究进展
文章链接:http://soscw.com/index.php/essay/39108.html