神经网络 - VGGNet 15
2021-01-01 23:28
标签:python3 opened als 尺寸 mamicode mes abd try mode 1. 走向深度:VGGNet 随着AlexNet在2012年ImageNet大赛上大放异彩后, 卷积网络进入了飞速的发展阶段, 而2014年的ImageNet亚军结构VGGNet(Visual Geometry Group Network) 则将卷积网络进行了改良, 探索了网络深度与性能的关系, 用更小的卷积核与更深的网络结构, 取得了较好的效果, 成为卷积结构发展史上较为重要的一个网络。
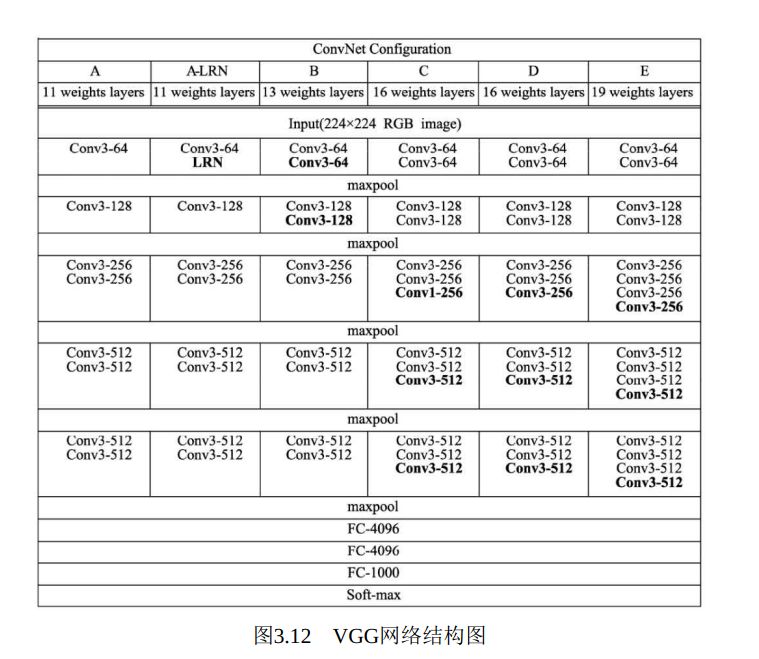
VGGNet网络结构组成如图3.12所示, 一共有6个不同的版本, 最常用的是VGG16。 从图3.12中可以看出, VGGNet采用了五组卷积与三个全连接层, 最后使用Softmax做分类。 VGGNet有一个显著的特点: 每次经过池化层(maxpool) 后特征图的尺寸减小一倍, 而通道数则增加一倍(最后一个池化层除外) 。
AlexNet中有使用到5×5的卷积核, 而在VGGNet中, 使用的卷积核基本都是3×3, 而且很多地方出现了多个3×3堆叠的现象, 这种结构的优点在于, 首先从感受野来看, 两个3×3的卷积核与一个5×5的卷积核是一样的; 其次, 同等感受野时, 3×3卷积核的参数量更少。 更为重要的是, 两个3×3卷积核的非线性能力要比5×5卷积核强, 因为其拥有两个激活函数, 可大大提高卷积网络的学习能力。
下面使用PyTorch来搭建VGG16经典网络结构, 新建一个vgg.py文件, 并输入以下内容 : 在终端中进入上述vgg.py文件的同级目录, 输入python3进入交互式环境, 利用下面代码调用该模块。 神经网络 - VGGNet 15 标签:python3 opened als 尺寸 mamicode mes abd try mode 原文地址:https://www.cnblogs.com/zhaopengpeng/p/13674554.html

1 import torch
2 from torch import nn
3
4 class VGG(nn.Module):
5
6 def __init__(self, num_classes=1000):
7 super(VGG, self).__init__()
8 layers = []
9 in_dim = 3
10 out_dim = 64
11
12 # 循环构造卷积层, 一共有13个卷积层
13 for i in range(13):
14 layers += [nn.Conv2d(in_dim, out_dim, 3, 1, 1), nn.ReLU(inplace=True)]
15 in_dim = out_dim
16 # 在第2、 4、 7、 10、 13个卷积层后增加池化层
17 if i==1 or i==3 or i==6 or i==9 or i==12:
18 layers += [nn.MaxPool2d(2, 2)]
19 # 第10个卷积后保持和前边的通道数一致, 都为512, 其余加倍
20 if i!=9:
21 out_dim*=2
22
23 self.features = nn.Sequential(*layers)
24 # VGGNet的3个全连接层, 中间有ReLU与Dropout层
25 self.classifier = nn.Sequential(
26 nn.Linear(512*7*7, 4096),
27 nn.ReLU(True),
28 nn.Dropout(),
29 nn.Linear(4096, 4096),
30 nn.ReLU(True),
31 nn.Dropout(),
32 nn.Linear(4096, num_classes),
33 )
34
35 def forward(self, x):
36 x = self.features(x)
37 # 这里是将特征图的维度从[1, 512, 7, 7]变到[1, 512*7*7]
38 x = x.view(x.size(0), -1)
39 x = self.classifier(x)
40 return x
1 import torch
2 from vgg import VGG
3
4 vgg = VGG(21).cuda()
5 input = torch.randn(1, 3, 224, 224).cuda()
6 print(input.shape)
7 >> torch.Size([1, 3, 224, 224]
8
9 scores = vgg(input)
10 print(scores.shape)
11 >> torch.Size([1, 21])
12
13 features = vgg.features(input)
14 print(features.shape)
15 >> torch.Size([1, 512, 7, 7])
16 print(vgg.features)
17 >> Sequential(
18 (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
19 (1): ReLU(inplace=True)
20 (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
21 (3): ReLU(inplace=True)
22 (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
23 (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
24 (6): ReLU(inplace=True)
25 (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
26 (8): ReLU(inplace=True)
27 (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
28 (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
29 (11): ReLU(inplace=True)
30 (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
31 (13): ReLU(inplace=True)
32 (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
33 (15): ReLU(inplace=True)
34 (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
35 (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
36 (18): ReLU(inplace=True)
37 (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
38 (20): ReLU(inplace=True)
39 (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
40 (22): ReLU(inplace=True)
41 (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
42 (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
43 (25): ReLU(inplace=True)
44 (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
45 (27): ReLU(inplace=True)
46 (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
47 (29): ReLU(inplace=True)
48 (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
49 )