kubernetes(十九) Ceph存储入门
2021-01-04 09:29
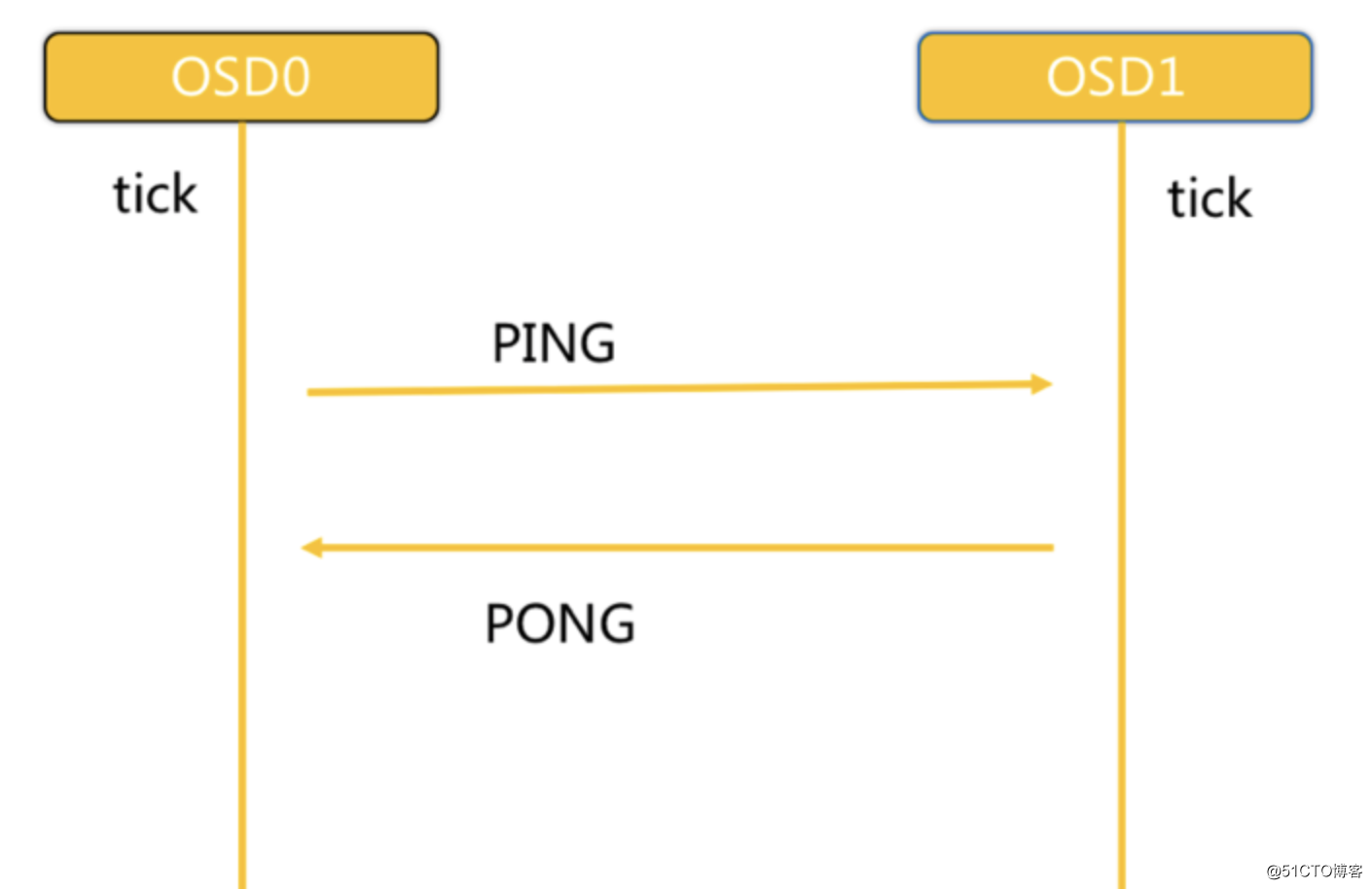
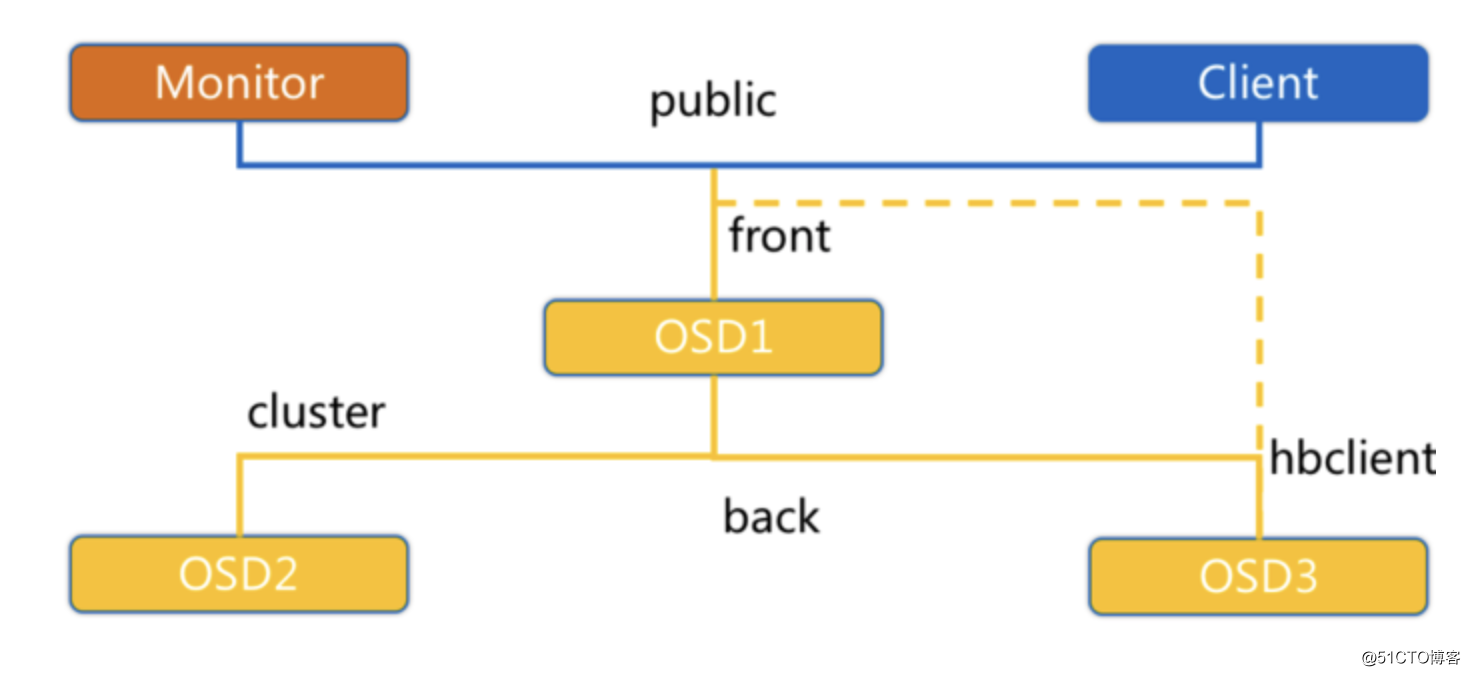
标签:影响 persist 系统 ++ 连接 enforce shanghai 好的 可视化 Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs),Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。目前也是OpenStack的主流后端存储,随着OpenStack在云计算领域的广泛使用,ceph也变得更加炙手可热。国内目前使用ceph搭建分布式存储系统较为成功的企业有华为,xsky,杉岩数据,中兴,华三,浪潮,中移动等。 Ceph设计思想:集群可靠性、集群可扩展性、数据安全性、接口统一性、充分发挥存储设备自身的计算能力、去除中心化 架构如下: Ceph使用RADOS提供对象存储,通过librados封装库提供多种存储方式的文件和对象转换。外层通过RGW(Object,有原生的API,而且也兼容Swift和S3的API,适合单客户端使用)、RBD(Block,支持精简配置、快照、克隆,适合多客户端有目录结构)、CephFS(File,Posix接口,支持快照,社会和更新变动少的数据,没有目录结构不能直接打开)将数据写入存储 RADOS 全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。 Librados Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持。 Crush Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。 Pool Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code); PG PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据; Object 简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利 于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。 Pool、PG和OSD的关系: 一个Pool里有很多PG; 一个PG里包含一堆对象,一个对象只能属于一个PG; OSD OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等; Monitor 一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责坚实整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权; MDS MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务; Mgr ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、promethus RGW RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。 Admin Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。 块存储(RBD) 优点: 2、文件存储(CephFS) 优点: 3、对象存储(Object)(适合更新变动较少的数据) 优点: (1)client 创建cluster handler; (2)client 读取配置文件; (3)client 连接上monitor,获取集群map信息; (4)client 读写io 根据crshmap 算法请求对应的主osd数据节点; (5)主osd数据节点同时写入另外两个副本节点数据; (6)等待主节点以及另外两个副本节点写完数据状态; (7)主节点及副本节点写入状态都成功后,返回给client,io写入完成。[强一致性] Ceph版本来源介绍 x.0.z - 开发版(给早期测试者和勇士们) x.1.z - 候选版(用于测试集群、高手们) x.2.z - 稳定、修正版(给用户们) x 将从 9 算起,它代表 Infernalis ( I 是第九个字母),这样第九个发布周期的第一个开发版就是 9.0.0 ;后续的开发版依次是 9.0.1 、 9.0.2 等等。 Luminous新版本特性 最少三台Centos7系统虚拟机用于部署Ceph集群。硬件配置:2C4G,另外每台机器最少挂载三块硬盘(每块盘5G) 192.168.56.14 cephnode01 1、编辑内网yum源,将yum源同步到其它节点并提前做好yum makecache 2、安装ceph-deploy,在node01执行(确认ceph-deploy版本是否为2.0.1,) 3、创建一个my-cluster目录,所有命令在此目录下进行,在node01执行(文件位置和名字可以随意) 4、创建一个Ceph集群,在node01执行 5、安装Ceph软件(每个节点执行) 6、生成monitor检测集群所使用的的秘钥 7、安装Ceph Cli,方便执行一些管理命令 8、部署mgr,用于管理集群 9、部署rgw (node01) 10、部署MDS(cephFS) 11、 添加osd 1、该配置文件采用init文件语法,#和;为注释,ceph集群在启动的时候会按照顺序加载所有的conf配置文件。 配置文件分为以下几大块配置。 2、配置文件可以从多个地方进行顺序加载,如果冲突将使用最新加载的配置,其加载顺序为。 3、配置文件还可以使用一些元变量应用到配置文件,如: 4、ceph.conf详细参数 RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型。RBD块设备类似磁盘可以被挂载。 RBD块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph集群的多个OSD中。 使用场景: (1)客户端创建一个pool,需要为这个pool指定pg的数量; 客户端写数据osd过程: 1、查看pools 2、创建rbd使用的pool (osd个数*100)/副本数 = 2的幂次方的数 3、创建一个块设备 4、 查看块设备 5、将块设备映射到系统内核 6、格式化块设备镜像 7、mount到本地 8、取消块设备和内核映射 9、删除RBD块设备 1、创建快照 2、列出创建的快照 3、查看快照详细信息 4、克隆快照(快照必须处于被保护状态才能被克隆) 5、查看快照的children 6、去掉快照的parent 7、恢复快照 8、删除快照 Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问. Jewel 版本 (10.2.0) 是第一个包含稳定 CephFS 的 Ceph 版本. CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问。 对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。 CephFS 库层包括 CephFS 库 libcephfs, 工作在 librados 的顶层, 代表着 Ceph 文件系统.最上层是能够访问 Ceph 文件系统的两类客户端. 要使用 CephFS, 至少就需要一个 metadata server 进程。可以手动创建一个 MDS, 也可以使用 ceph-deploy 或者 ceph-ansible 来部署 MDS。 部署一个 CephFS, 步骤如下: 在一个 Mon 节点上创建 Ceph 文件系统. 若使用 CephX 认证,需要创建一个访问 CephFS 的客户端 挂载 CephFS 到一个专用的节点. 以 kernel client 形式挂载 CephFS 以 FUSE client 形式挂载 CephFS 1、CephFS 需要两个 Pools - cephfs-data 和 cephfs-metadata, 分别存储文件数据和文件元数据 注:一般 metadata pool 可以从相对较少的 PGs 启动, 之后可以根据需要增加 PGs. 因为 metadata pool 存储着 CephFS 文件的元数据, 为了保证安全, 最好有较多的副本数. 为了能有较低的延迟, 可以考虑将 metadata 存储在 SSDs 上. 2、创建一个 CephFS, 名字为 cephfs: 3、验证至少有一个 MDS 已经进入 Active 状态 4、在 Monitor 上, 创建一个用户,用于访问CephFs 5、验证key是否生效 6、检查CephFs和mds状态 1、创建挂载目录 cephfs 2、挂载目录 3、开机自动挂载 1、安装ceph-common 2、安装ceph-fuse 3、将集群的ceph.conf拷贝到客户端 【ceph集群外节点需要这个操作,集群内不用】 4、使用 ceph-fuse 挂载 CephFS 5、验证 CephFS 已经成功挂载 6、自动挂载 7、卸载 (1)配置主主模式 (2)配置MDS多主模式 (3)配置备用MDS 但如果你确信你的MDS不会出现故障,可以通过以下设置来通知ceph不需要备用MDS,否则会出现insufficient standby daemons available告警信息: (4)还原单主MDS Ceph 的监控可视化界面方案很多----grafana、Kraken。但是从Luminous开始,Ceph 提供了原生的Dashboard功能,通过Dashboard可以获取Ceph集群的各种基本状态信息。 1、在 scrape_configs: 配置项下添加 2、重启promethus服务 3、检查prometheus服务器中是否添加成功 1、浏览器登录 grafana 管理界面 管理存储是管理计算的一个明显问题。PersistentVolume子系统为用户和管理员提供了一个API,用于抽象如何根据消费方式提供存储的详细信息。于是引入了两个新的API资源:PersistentVolume和PersistentVolumeClaim PersistentVolume(PV)是集群中已由管理员配置的一段网络存储。 集群中的资源就像一个节点是一个集群资源。 PV是诸如卷之类的卷插件,但是具有独立于使用PV的任何单个pod的生命周期。 该API对象包含存储的实现细节,即NFS,iSCSI或云提供商特定的存储系统。 PersistentVolumeClaim(PVC)是用户存储的请求。 它类似于pod。Pod消耗节点资源,PVC消耗存储资源。 pod可以请求特定级别的资源(CPU和内存)。 权限要求可以请求特定的大小和访问模式。 虽然PersistentVolumeClaims允许用户使用抽象存储资源,但是常见的是,用户需要具有不同属性(如性能)的PersistentVolumes,用于不同的问题。 管理员需要能够提供多种不同于PersistentVolumes,而不仅仅是大小和访问模式,而不会使用户了解这些卷的实现细节。 对于这些需求,存在StorageClass资源。 StorageClass为集群提供了一种描述他们提供的存储的“类”的方法。 不同的类可能映射到服务质量级别,或备份策略,或者由群集管理员确定的任意策略。 Kubernetes本身对于什么类别代表是不言而喻的。 这个概念有时在其他存储系统中称为“配置文件” 动态供给主要是能够自动帮你创建pv,需要多大的空间就创建多大的pv。k8s帮助创建pv,创建pvc就直接api调用存储类来寻找pv。 如果是存储静态供给的话,会需要我们手动去创建pv,如果没有足够的资源,找不到合适的pv,那么pod就会处于pending等待的状态。而动态供给主要的一个实现就是StorageClass存储对象,其实它就是声明你使用哪个存储,然后帮你去连接,再帮你去自动创建pv。 RBD支持ReadWriteOnce,ReadOnlyMany两种模式 (1)配置rbd-provider【k8s 集群上操作】 需要在k8s集群安装ceph-common 参考地址:https://github.com/kubernetes-retired/external-storage/tree/master/ceph/rbd/deploy/rbac (2)配置storageclass 【在cephnode01操作】 创建pod时,kubelet需要使用rbd命令去检测和挂载pv对应的ceph image,所以要在所有的worker节点安装ceph客户端ceph-common。将ceph的ceph.client.admin.keyring和ceph.conf文件拷贝到master的/etc/ceph目录下 (3) 创建 osd pool 在ceph的mon或者admin节点 【在cephnode01操作】 (4)创建k8s访问ceph的用户 在ceph的mon或者admin节点 【在cephnode01操作】 (5)查看key 在ceph的mon或者admin节点 【在cephnode01操作】 (6)创建 admin secret 【k8s Master上操作】 (7)配置StorageClass 【k8s Master上操作】 (8) 创建pvc (9) 测试(挂载nginx测试) (10) 文件修改测试 (11) 访问测试 (12)pvc扩容 pvc 只能扩容不能缩容 (12) 清理 CephFS方式支持k8s的pv的3种访问模式ReadWriteOnce,ReadOnlyMany ,ReadWriteMany (2)创建一个CephFS 【在cephnode01操作】 (3)使用社区提供的cephfs-provisioner (4)获取ceph key 【在cephnode01操作】 (5) 创建secret(一定要和storageclass在同一namespace) (6) 配置 StorageClass (7) 创建pvc测试 (8) 创建 nginx pod 挂载测试 (9) 修改文件内容 (10) 访问pod测试 (11) 清理 集群整体运行状态 说明: id:集群ID PG状态 Pool状态 OSD状态 Monitor状态和查看仲裁状态 集群空间用量 有时候需要更改服务的配置,但不想重启服务,或者是临时修改。这时候就可以使用tell和daemon子命令来完成此需求。 tell子命令格式 添加OSD 删除OSD 扩容PG 注: 列出存储池 创建存储池 设置存储池配额 删除存储池 查看存储池统计信息 存储池做快照 获取存储池选项值 调整存储池选项值 获取对象副本数 Ceph 把数据以对象的形式存于各存储池中。Ceph 用户必须具有访问存储池的权限才能够读写数据。另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。 添加用户 修改用户权限 删除用户 一个集群可以只有一个 monitor,推荐生产环境至少部署 3 个。 Ceph 使用 Paxos 算法的一个变种对各种 map 、以及其它对集群来说至关重要的信息达成共识。建议(但不是强制)部署奇数个 monitor 。Ceph 需要 mon 中的大多数在运行并能够互相通信,比如单个 mon,或 2 个中的 2 个,3 个中的 2 个,4 个中的 3 个等。初始部署时,建议部署 3 个 monitor。后续如果要增加,请一次增加 2 个。 基本概念
为什么要使用ceph
Ceph架构介绍
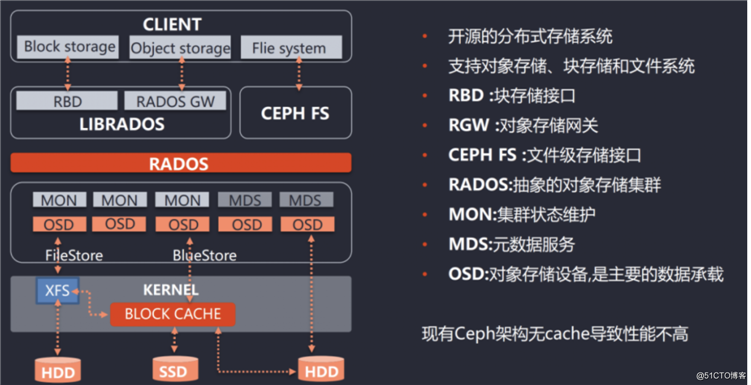
ceph特点
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据
a. 去中心化
b. 扩展灵活
c. 随着节点增加而线性增长
a. 支持三种存储接口:块存储、文件存储、对象存储
b. 支持自定义接口,支持多种语言驱动 ceph 核心概念
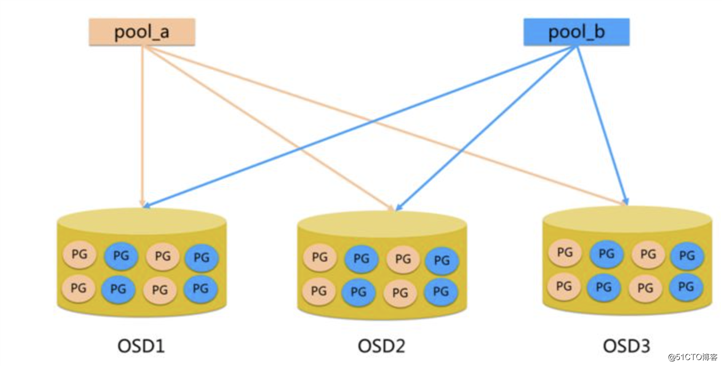
Ceph核心组件
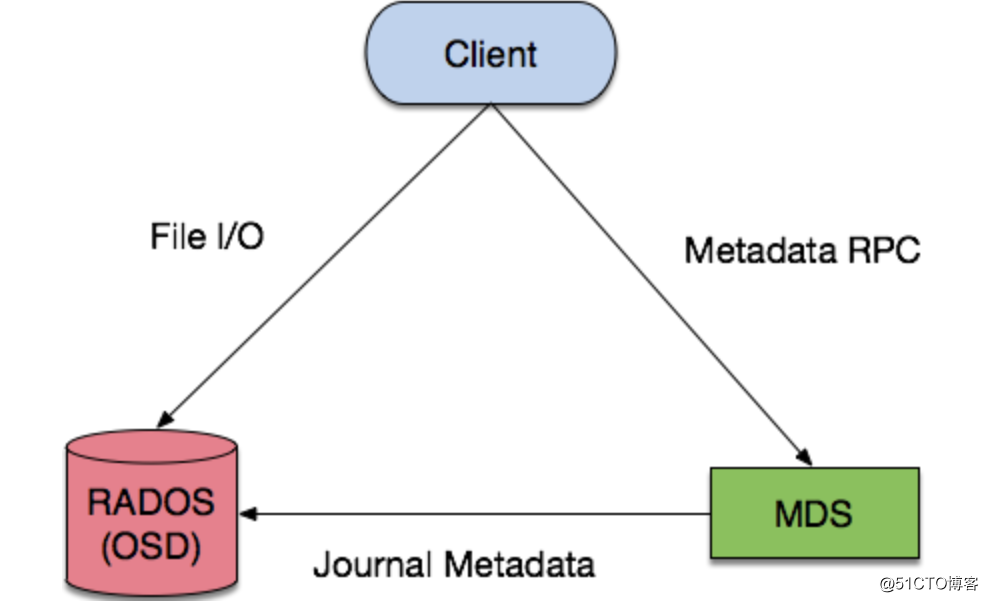
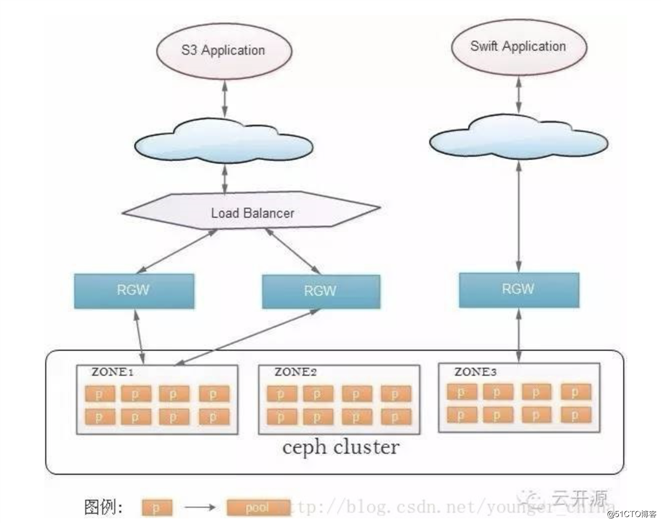
ceph三种存储类型
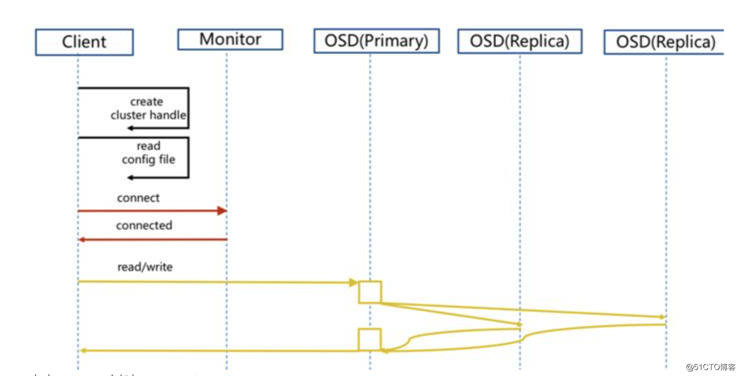
集群IO流程
Ceph安装
ceph版本选择
Ceph 社区最新版本是 14,而 Ceph 12 是市面用的最广的稳定版本。
第一个 Ceph 版本是 0.1 ,要回溯到 2008 年 1 月。多年来,版本号方案一直没变,直到 2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,为了避免 0.99 (以及 0.100 或 1.00 ?),制定了新策略。
版本名称
版本号
发布时间
Argonaut
0.48版本(LTS)
2012年6月3日
Bobtail
0.56版本(LTS)
2013年5月7日
Cuttlefish
0.61版本
2013年1月1日
Dumpling
0.67版本(LTS)
2013年8月14日
Emperor
0.72版本
2013年11月9
Firefly
0.80版本(LTS)
2014年5月
Giant
Giant
October 2014 - April 2015
Hammer
Hammer
April 2015 - November 2016
Infernalis
Infernalis
November 2015 - June 2016
Jewel
10.2.9
2016年4月
Kraken
11.2.1
2017年10月
Luminous
12.2.12
2017年10月
mimic
13.2.7
2018年5月
nautilus
14.2.5
2019年2月
BlueStore通过直接管理物理HDD或SSD而不使用诸如XFS的中间文件系统,来管理每个OSD存储的数据,这提供了更大的性能和功能。
安装前准备
192.168.56.15 cephnode02
192.168.56.16 cephnode03
(1)关闭防火墙:
$ systemctl stop firewalld
$ systemctl disable firewalld
(2)关闭selinux:
$ sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config
$ setenforce 0
(3)关闭NetworkManager
$ systemctl disable NetworkManager && systemctl stop NetworkManager
(4)添加主机名与IP对应关系:
$ vim /etc/hosts
192.168.56.14 cephnode01
192.168.56.15 cephnode02
192.168.56.16 cephnode03
(5)设置主机名:
hostnamectl set-hostname cephnode01
hostnamectl set-hostname cephnode02
hostnamectl set-hostname cephnode03
(6)同步网络时间和修改时区
systemctl restart chronyd.service && systemctl enable chronyd.service
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
(7)设置文件描述符
echo "ulimit -SHn 102400" >> /etc/rc.local
cat >> /etc/security/limits.conf > /etc/sysctl.conf /sys/block/sda/queue/read_ahead_kb
(11) 安装epel-release
yum -y install epel-release安装Ceph集群
$ vim /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/$basearch
gpgcheck=0
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch
gpgcheck=0
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-nautilus/el7/SRPMS
gpgcheck=0
priority=1$ yum install -y ceph-deploy$ mkdir /my-cluster
$ cd /my-cluster
$ yum -y install python2-pip$ ceph-deploy new cephnode01 cephnode02 cephnode03 $ wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
$ yum -y install epel-release
$ yum -y install ceph
$ ceph -v$ ceph-deploy mon create-initial$ ceph-deploy admin cephnode01 cephnode02 cephnode03$ ceph-deploy mgr create cephnode01 cephnode02 cephnode03$ yum install -y ceph-radosgw
$ ceph-deploy rgw create cephnode01$ ceph-deploy mds create cephnode01 cephnode02 cephnode03
$ ceph -s #查看集群状态$ ceph-deploy osd create --data /dev/sdb cephnode01
$ ceph-deploy osd create --data /dev/sdb cephnode02
$ ceph-deploy osd create --data /dev/sdb cephnode03ceph.conf
global:全局配置。
osd:osd专用配置,可以使用osd.N,来表示某一个OSD专用配置,N为osd的编号,如0、2、1等。
mon:mon专用配置,也可以使用mon.A来为某一个monitor节点做专用配置,其中A为该节点的名称,ceph-monitor-2、ceph-monitor-1等。使用命令 ceph mon dump可以获取节点的名称。
client:客户端专用配置。$CEPH_CONF环境变量
-c 指定的位置
/etc/ceph/ceph.conf
~/.ceph/ceph.conf
./ceph.conf$cluster:当前集群名。
$type:当前服务类型。
$id:进程的标识符。
$host:守护进程所在的主机名。
$name:值为$type.$id。[global]#全局设置
fsid = xxxxxxxxxxxxxxx #集群标识ID
mon host = 10.0.1.1,10.0.1.2,10.0.1.3 #monitor IP 地址
auth cluster required = cephx #集群认证
auth service required = cephx #服务认证
auth client required = cephx #客户端认证
osd pool default size = 3 #最小副本数 默认是3
osd pool default min size = 1 #PG 处于 degraded 状态不影响其 IO 能力,min_size是一个PG能接受IO的最小副本数
public network = 10.0.1.0/24 #公共网络(monitorIP段)
cluster network = 10.0.2.0/24 #集群网络
max open files = 131072 #默认0#如果设置了该选项,Ceph会设置系统的max open fds
mon initial members = node1, node2, node3 #初始monitor (由创建monitor命令而定)
##############################################################
[mon]
mon data = /var/lib/ceph/mon/ceph-$id
mon clock drift allowed = 1 #默认值0.05#monitor间的clock drift
mon osd min down reporters = 13 #默认值1#向monitor报告down的最小OSD数
mon osd down out interval = 600 #默认值300 #标记一个OSD状态为down和out之前ceph等待的秒数
##############################################################
[osd]
osd data = /var/lib/ceph/osd/ceph-$id
osd mkfs type = xfs #格式化系统类型
osd max write size = 512 #默认值90 #OSD一次可写入的最大值(MB)
osd client message size cap = 2147483648 #默认值100 #客户端允许在内存中的最大数据(bytes)
osd deep scrub stride = 131072 #默认值524288 #在Deep Scrub时候允许读取的字节数(bytes)
osd op threads = 16 #默认值2 #并发文件系统操作数
osd disk threads = 4 #默认值1 #OSD密集型操作例如恢复和Scrubbing时的线程
osd map cache size = 1024 #默认值500 #保留OSD Map的缓存(MB)
osd map cache bl size = 128 #默认值50 #OSD进程在内存中的OSD Map缓存(MB)
osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier" #默认值rw,noatime,inode64 #Ceph OSD xfs Mount选项
osd recovery op priority = 2 #默认值10 #恢复操作优先级,取值1-63,值越高占用资源越高
osd recovery max active = 10 #默认值15 #同一时间内活跃的恢复请求数
osd max backfills = 4 #默认值10 #一个OSD允许的最大backfills数
osd min pg log entries = 30000 #默认值3000 #修建PGLog是保留的最大PGLog数
osd max pg log entries = 100000 #默认值10000 #修建PGLog是保留的最大PGLog数
osd mon heartbeat interval = 40 #默认值30 #OSD ping一个monitor的时间间隔(默认30s)
ms dispatch throttle bytes = 1048576000 #默认值 104857600 #等待派遣的最大消息数
objecter inflight ops = 819200 #默认值1024 #客户端流控,允许的最大未发送io请求数,超过阀值会堵塞应用io,为0表示不受限
osd op log threshold = 50 #默认值5 #一次显示多少操作的log
osd crush chooseleaf type = 0 #默认值为1 #CRUSH规则用到chooseleaf时的bucket的类型
##############################################################
[client]
rbd cache = true #默认值 true #RBD缓存
rbd cache size = 335544320 #默认值33554432 #RBD缓存大小(bytes)
rbd cache max dirty = 134217728 #默认值25165824 #缓存为write-back时允许的最大dirty字节数(bytes),如果为0,使用write-through
rbd cache max dirty age = 30 #默认值1 #在被刷新到存储盘前dirty数据存在缓存的时间(seconds)
rbd cache writethrough until flush = false #默认值true #该选项是为了兼容linux-2.6.32之前的virtio驱动,避免因为不发送flush请求,数据不回写
#设置该参数后,librbd会以writethrough的方式执行io,直到收到第一个flush请求,才切换为writeback方式。
rbd cache max dirty object = 2 #默认值0 #最大的Object对象数,默认为0,表示通过rbd cache size计算得到,librbd默认以4MB为单位对磁盘Image进行逻辑切分
#每个chunk对象抽象为一个Object;librbd中以Object为单位来管理缓存,增大该值可以提升性能
rbd cache target dirty = 235544320 #默认值16777216 #开始执行回写过程的脏数据大小,不能超过 rbd_cache_max_dirtyRBD
RBD介绍
Ceph RBD IO流程
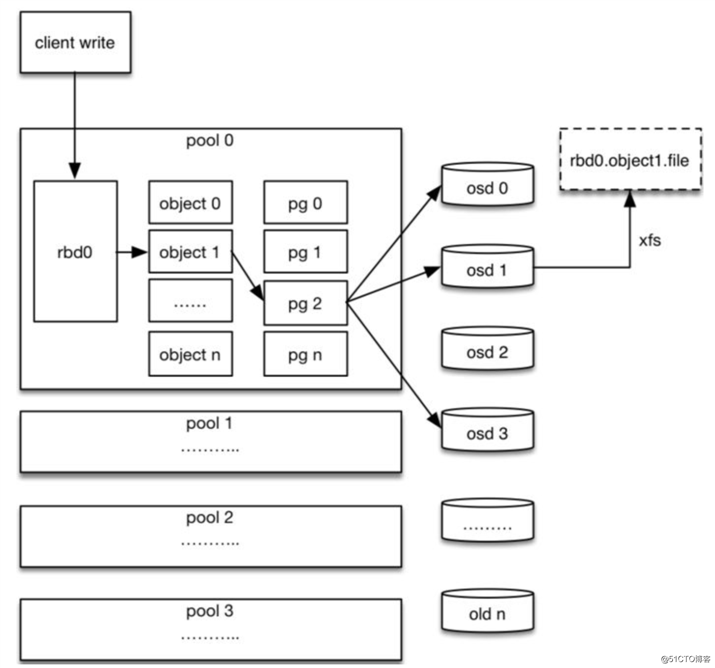
(2)创建pool/image rbd设备进行挂载;
(3)用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号;
(4)将每个object通过pg进行副本位置的分配;
(5)pg根据cursh算法会寻找3个osd,把这个object分别保存在这三个osd上;
(6)osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统;
(7)object的存储就变成了存储一个文rbd0.object1.file; 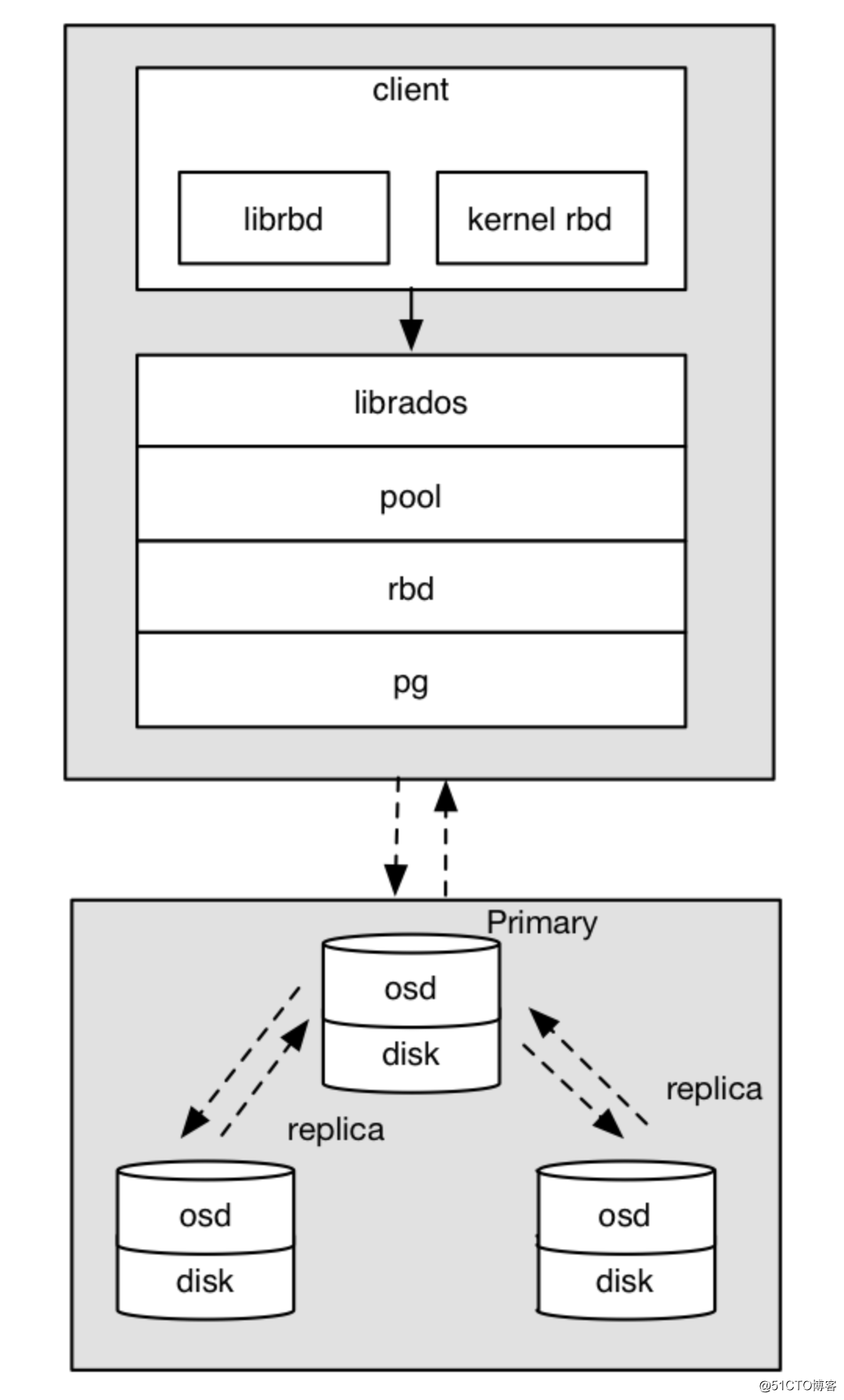
RBD常用命令
命令
功能
rbd create
创建块设备映像
rbd ls
列出 rbd 存储池中的块设备
rbd info
查看块设备信息
rbd diff
可以统计 rbd 使用量
rbd map
映射块设备
rbd showmapped
查看已映射块设备
rbd remove
删除块设备
rbd resize
更改块设备的大小
RBD配置操作
rados lspools# ceph osd pool create rbd 32 32
# ceph osd pool application enable rbd rbd # rbd create --size 10240 image01 # rbd ls
# rbd info image01# rbd feature disable image01 exclusive-lock, object-map, fast-diff, deep-flatten # 禁用当前系统内核不支持的feature
# rbd map image01 # mkfs.xfs /dev/rbd0# mount /dev/rbd0 /mnt
# umount /mnt# rbd unmap image01 # rbd rm image01快照配置
# rbd create --size 10240 image02
# rados -p rbd ls
# rbd snap create image02@image02_snap01# rbd snap list image02
或
# rbd ls -l# rbd info image02@image02_snap01# rbd snap protect image02@image02_snap01
# ceph osd pool create kube 32 32
# rbd clone rbd/image02@image02_snap01 kube/image02_clone01
# rados -p kube ls# rbd children image02# rbd flatten kube/image02_clone01# rbd snap rollback image02@image02_snap01# rbd snap unprotect image02@image02_snap01
# rbd snap remove image02@image02_snap01CephFs
CephFs介绍
CephFS 架构
底层是核心集群所依赖的, 包括:
Ceph 存储集群的协议层是 Ceph 原生的 librados 库, 与核心集群交互.配置 CephFS MDS
登录到ceph-deploy工作目录执行
# ceph-deploy mds create $hostname部署Ceph文件系统
创建一个 Ceph 文件系统# ceph osd pool create cephfs-data 16 16
# ceph osd pool create cephfs-metadata 16 16# ceph fs new cephfs cephfs-metadata cephfs-data# ceph fs status cephfs# ceph auth get-or-create client.cephfs mon ‘allow r‘ mds ‘allow rw‘ osd ‘allow rw pool=cephfs-data, allow rw pool=cephfs-metadata‘
[client.cephfs]
key = AQCzlk9fNV+VJBAAjVOx54CRjZoFe5kIVmVjDA==# ceph auth get client.cephfsceph mds stat
ceph fs ls
ceph fs statuskernel client 形式挂载 CephFS
# mkdir /cephfs # mount -t ceph 192.168.56.14:6789,192.168.56.15:6789,192.168.56.16:6789:/ /cephfs/ -o name=cephfs,secret=AQCzlk9fNV+VJBAAjVOx54CRjZoFe5kIVmVjDA==$ vim /etc/ceph/cephfs.key
[client.cephfs]
key = AQCzlk9fNV+VJBAAjVOx54CRjZoFe5kIVmVjDA==
$ vim /etc/fstab
192.168.56.14:6789,192.168.56.15:6789,192.168.56.16:6789:/ /cephfs/ -o name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0FUSE client 形式挂载 CephFS
yum install -y ceph-commonyum install -y ceph-fusescp root@192.168.56.14:/etc/ceph/ceph.conf /etc/ceph/
chmod 644 /etc/ceph/ceph.conf$ ceph auth get client.cephfs
[client.cephfs]
key = AQCzlk9fNV+VJBAAjVOx54CRjZoFe5kIVmVjDA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
# 其他节点执行如下的挂载命令
$ vim /etc/ceph/ceph.client.cephfs.keyring
[client.cephfs]
key = AQCzlk9fNV+VJBAAjVOx54CRjZoFe5kIVmVjDA==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
$ ceph-fuse --keyring /etc/ceph/ceph.client.cephfs.keyring --name client.cephfs -m 192.168.56.14:6789,192.168.56.15:6789,192.168.56.16:6789 /cephfs/stat -f /cephfsecho "none /cephfs fuse.ceph ceph.id=cephfs[,ceph.conf=/etc/ceph/ceph.conf],_netdev,defaults 0 0"| sudo tee -a /etc/fstab
或
echo "id=cephfs,conf=/etc/ceph/ceph.conf /mnt/ceph2 fuse.ceph _netdev,defaults 0 0"| sudo tee -a /etc/fstabfusermount -u /cephfsMDS主备与主主切换
# ceph fs set cephfs max_mds 2
即使有多个活动的MDS,如果其中一个MDS出现故障,仍然需要备用守护进程来接管。因此,对于高可用性系统,实际配置max_mds时,最好比系统中MDS的总数少一个。# ceph fs set
设置max_mds# ceph fs set cephfs max_mds 1Ceph Dashboard
mimic版 (nautilus版) dashboard 安装。如果是 (nautilus版) 需要安装 ceph-mgr-dashboard 配置Ceph Dashboard
1、在每个mgr节点安装
# yum install ceph-mgr-dashboard -y
2、开启mgr功能
# ceph mgr module enable dashboard
3、生成并安装自签名的证书
# ceph dashboard create-self-signed-cert
4、创建一个dashboard登录用户名密码(guest administrator权限)
# ceph dashboard ac-user-create guest 1q2w3e4r administrator
5、禁用SSL
# ceph config set mgr mgr/dashboard/ssl false
6、查看服务访问方式
# ceph mgr services修改默认配置命令(存在问题,无法修改)
指定集群dashboard的访问端口
# ceph config set mgr mgr/dashboard/server_port 7000
指定集群 dashboard的访问IP
# ceph config set mgr mgr/dashboard/server_addr 192.168.56.14dashboard登陆测试
$ ceph mgr services
{
"dashboard": "https://cephnode03:8443/"
}
$ vim /etc/hosts
192.168.56.16 cephnode03
开启Object Gateway管理功能
1、创建rgw用户
# radosgw-admin user create --uid=user01 --display-name=user01 --system
2、提供Dashboard证书
# ceph dashboard set-rgw-api-access-key $access_key
# ceph dashboard set-rgw-api-secret-key $secret_key
3、配置rgw主机名和端口
# ceph dashboard set-rgw-api-host 192.168.56.14
# ceph dashboard set-rgw-api-port 7480
4、刷新web页面Promethus+Grafana
安装grafana
1、配置yum源文件
# vim /etc/yum.repos.d/grafana.repo
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
2.通过yum命令安装grafana
# yum -y install grafana
3.启动grafana并设为开机自启
# systemctl start grafana-server.service
# systemctl enable grafana-server.service安装promethus
1、下载安装包,下载地址
wget https://github.com/prometheus/prometheus/releases/download/v2.20.1/prometheus-2.20.1.linux-amd64.tar.gz
2、解压压缩包
# tar prometheus-2.20.1.linux-amd64.tar.gz
3、将解压后的目录改名
# mv prometheus-2.20.1.linux-amd64 /opt/prometheus
4、查看promethus版本
# /opt/prometheus/prometheus --version
5、配置系统服务启动
# tee /etc/systemd/system/prometheus.service ceph mgr prometheus插件配置
# ceph mgr module enable prometheus
# netstat -nltp | grep mgr 检查端口
# curl 192.168.56.16:9283/metrics 测试返回值配置promethus
# vim /opt/prometheus/prometheus.yml
- job_name: ‘ceph_cluster‘
honor_labels: true
scrape_interval: 5s
static_configs:
- targets: [‘192.168.56.16:9283‘]
labels:
instance: ceph# systemctl restart prometheus# 浏览器-》 http://x.x.x.x:9090 -》status -》Targets配置grafana
2、添加data sources,点击configuration--》data sources
3、添加dashboard,点击HOME--》find dashboard on grafana.com
4、搜索ceph的dashboard (2842)
5、点击HOME--》Import dashboard, 选择合适的dashboard,记录编号
K8s对接Ceph存储
PV、PVC概述
POD动态供给
POD使用CephRBD做为持久数据卷
$ tee /etc/yum.repos.d/ceph.repo $ cat > external-storage-rbd-provisioner.yaml $ scp /etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.conf root@192.168.56.11:/etc/ceph/ceph osd pool create kube 32 32
rados lspools
ceph osd pool ls$ ceph auth get-or-create client.kube mon ‘allow r‘ osd ‘allow class-read object_prefix rbd_children, allow rwx pool=kube‘ -o ceph.client.kube.keyring
$ cat ceph.client.kube.keyring
[client.kube]
key = AQBqUlNftVySFBAAFcXEwMJDmFiTfAEYKILlKw==ceph auth get-key client.admin
ceph auth get-key client.kube
ceph auth get-key client.admin | base64 (这里获取的值要给k8s创建secret使用,也就是如下操作)
ceph auth get-key client.kube | base64 (这里获取的值要给k8s创建secret使用)$ vim secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret-admin
namespace: kube-system
type: "kubernetes.io/rbd"
data:
# ceph auth get-key client.admin | base64
key: QVFDR05FNWZDMit0TVJBQUhMaTNrWEZhMVRScjM4UXFQcW1adXc9PQ==
---
apiVersion: v1
kind: Secret
metadata:
name: ceph-secret
namespace: kube-system
type: "kubernetes.io/rbd"
data:
# ceph auth add client.kube mon ‘allow r‘ osd ‘allow rwx pool=kube‘
# ceph auth get-key client.kube | base64
key: QVFCcVVsTmZ0VnlTRkJBQUZjWEV3TUpEbUZpVGZBRVlLSUxsS3c9PQ==$ tee storageclass-cephfs.yaml $ cat >ceph-rdb-pvc-test.yaml$ cat > nginx-test-pod.yaml $ kubectl exec -ti nginx-pod1 -- /bin/sh -c ‘echo this is from Ceph RBD!!! > /usr/share/nginx/html/index.html‘$ curl 10.244.206.81
this is from Ceph RBD!!!$ vim storageclass-cephfs.yaml
allowVolumeExpansion: true
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: dynamic-ceph-rdb
provisioner: ceph.com/rbd
parameters:
monitors: 192.168.56.14:6789,192.168.56.15:6789,192.168.56.16:6789
pool: kube
adminId: admin
adminSecretNamespace: kube-system
adminSecretName: ceph-secret-admin
userId: kube
userSecretNamespace: kube-system
userSecretName: ceph-secret
fsType: ext4
imageFormat: "2"
imageFeatures: layering
$ vim ceph-rdb-pvc-test.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: ceph-rdb-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: dynamic-ceph-rdb
resources:
requests:
storage: 4Gi
$ kubectl apply -f ceph-rdb-pvc-test.yaml
$ kubectl exec -it nginx-pod1 -- sh
/ # df -Th
/dev/rbd0 ext4 2.9G 3.0M 2.9G 0% /usr/share/nginx/htmlkubectl delete -f nginx-pod.yaml
kubectl delete -f ceph-rdb-pvc-test.yamlPOD使用CephFS做为持久数据卷
(1)如下操作在ceph的mon或者admin节点 【在cephnode01操作】
CephFS需要使用两个Pool来分别存储数据和元数据ceph osd pool create fs_data 16 16
ceph osd pool create fs_metadata 8 8
ceph osd lspools$ ceph fs new cephfs fs_metadata fs_data
$ ceph fs ls # 查看cephfs
name: cephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]$ mkdir ~/lesson/ceph/cephfs -pv && cd ~/lesson/ceph/cephfs
$ cat >external-storage-cephfs-provisioner.yaml$ ceph auth get-key client.admin | base64
QVFDR05FNWZDMit0TVJBQUhMaTNrWEZhMVRScjM4UXFQcW1adXc9PQ==$ cd ~/lesson/ceph/cephfs
$ cat > secret.yaml $ cd ~/lesson/ceph/cephfs
$ cat >storageclass-cephfs.yaml$ cd ~/lesson/ceph/cephfs
$ cat >cephfs-pvc-test.yaml$ cd ~/lesson/ceph/cephfs
$ cat >nginx-pod.yaml$ kubectl exec -ti nginx-pod2 -- /bin/sh -c ‘echo This is from CephFS!!! > /usr/share/nginx/html/index.html‘$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-pod2 1/1 Running 0 81s 10.244.206.88 k8s-master1 $ kubectl delete -f nginx-pod.yaml
$ kubectl delete -f cephfs-pvc-test.yaml日常运维管理
集群监控管理
$ ceph -s
cluster:
id: 56f6429d-eff6-4b52-a8b7-54169c6a5bff
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 2h)
mgr: cephnode03(active, since 44h), standbys: cephnode02, cephnode01
mds: cephfs:1 {0=cephnode03=up:active} 2 up:standby
osd: 3 osds: 3 up (since 45h), 3 in (since 5d)
rgw: 1 daemon active (cephnode01)
task status:
scrub status:
mds.cephnode03: idle
data:
pools: 10 pools, 248 pgs
objects: 305 objects, 70 MiB
usage: 3.2 GiB used, 12 GiB / 15 GiB avail
pgs: 248 active+clean
health:集群运行状态,这里有一个警告,说明是有问题,意思是pg数大于pgp数,通常此数值相等。
mon:Monitors运行状态。
osd:OSDs运行状态。
mgr:Managers运行状态。
mds:Metadatas运行状态。
pools:存储池与PGs的数量。
objects:存储对象的数量。
usage:存储的理论用量。
pgs:PGs的运行状态$ ceph -w
$ ceph health detail
查看pg状态查看通常使用下面两个命令即可,dump可以查看更详细信息,如。$ ceph pg dump
$ ceph pg stat$ ceph osd pool stats $ ceph osd stat
$ ceph osd dump
$ ceph osd tree
$ ceph osd df$ ceph mon stat
$ ceph mon dump
$ ceph quorum_status$ ceph df
$ ceph df detail集群配置管理(临时和全局,服务平滑重启)
daemon子命令命令格式:
# ceph daemon {daemon-type}.{id} config show
命令举例:
# ceph daemon osd.0 config show
# ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false
使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集群的角色进行设置。而出现节点异常无法设置时候,只会在命令行当中进行报错,不太便于查找。命令格式:
# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]
命令举例:
# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1
集群进程操作
1、格式化磁盘
ceph-volume lvm zap /dev/sd1、调整osd的crush weight为 0
ceph osd crush reweight osd.ceph osd pool set {pool-name} pg_num 128
ceph osd pool set {pool-name} pgp_num 128
1、扩容大小取跟它接近的2的N次方
2、在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的pg_num,就需要同时增加pgp_num,保持它们大小一致,这样集群才能正常rebalancing。Pool操作
ceph osd lspools命令格式:
# ceph osd pool create {pool-name} {pg-num} [{pgp-num}]
命令举例:
# ceph osd pool create rbd 32 32命令格式:
# ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
命令举例:
# ceph osd pool set-quota rbd max_objects 10000ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]rados dfceph osd pool rmsnap {pool-name} {snap-name}ceph osd pool get {pool-name} {key}ceph osd pool set {pool-name} {key} {value}
size:设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本存储池。
min_size:设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用于副本存储池。
pg_num:计算数据分布时的有效 PG 数。只能大于当前 PG 数。
pgp_num:计算数据分布时使用的有效 PGP 数量。小于等于存储池的 PG 数。
hashpspool:给指定存储池设置/取消 HASHPSPOOL 标志。
target_max_bytes:达到 max_bytes 阀值时会触发 Ceph 冲洗或驱逐对象。
target_max_objects:达到 max_objects 阀值时会触发 Ceph 冲洗或驱逐对象。
scrub_min_interval:在负载低时,洗刷存储池的最小间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_min_interval 。
scrub_max_interval:不管集群负载如何,都要洗刷存储池的最大间隔秒数。如果是 0 ,就按照配置文件里的 osd_scrub_max_interval 。
deep_scrub_interval:“深度”洗刷存储池的间隔秒数。如果是 0 ,就按照配置文件里的 osd_deep_scrub_interval 。ceph osd dump | grep ‘replicated size‘用户管理
查看用户信息查看所有用户信息
# ceph auth list
获取所有用户的key与权限相关信息
# ceph auth get client.admin
如果只需要某个用户的key信息,可以使用pring-key子命令
# ceph auth print-key client.admin # ceph auth add client.john mon ‘allow r‘ osd ‘allow rw pool=liverpool‘
# ceph auth get-or-create client.paul mon ‘allow r‘ osd ‘allow rw pool=liverpool‘
# ceph auth get-or-create client.george mon ‘allow r‘ osd ‘allow rw pool=liverpool‘ -o george.keyring
# ceph auth get-or-create-key client.ringo mon ‘allow r‘ osd ‘allow rw pool=liverpool‘ -o ringo.key# ceph auth caps client.john mon ‘allow r‘ osd ‘allow rw pool=liverpool‘
# ceph auth caps client.paul mon ‘allow rw‘ osd ‘allow rwx pool=liverpool‘
# ceph auth caps client.brian-manager mon ‘allow *‘ osd ‘allow *‘
# ceph auth caps client.ringo mon ‘ ‘ osd ‘ ‘# ceph auth del {TYPE}.{ID}
其中, {TYPE} 是 client,osd,mon 或 mds 的其中一种。{ID} 是用户的名字或守护进程的 ID 。增加和删除Monitor
新增一个monitor# ceph-deploy mon create $hostname
注意:执行ceph-deploy之前要进入之前安装时候配置的目录。/my-cluster
上一篇:JS 宏任务和微任务
文章标题:kubernetes(十九) Ceph存储入门
文章链接:http://soscw.com/index.php/essay/40018.html