|
1.flume简介
Flume是Cloudera提供的日志收集系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
2.安装和使用说明:
2.1 安装
a. 下载: http://archive.cloudera.com/cdh/3/ flume-0.9.0+1.tar.gz
接着解压.暂时用$flume代表解压路径.
b. 用户文档:http://archive.cloudera.com/cdh/3/flume/UserGuide.html
c. 下载: http://archive.cloudera.com/cdh/3/ zookeeper-3.3.1.tar.gz
d. 安装zookeeper
yum install hadoop-zookeeper –y
yum install hadoop-zookeeper-server –y
修改/zookeeper-3.3.1/conf/ zoo_sample.cfg重命名为zoo.cfg
执行如下命令:
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.3.1
export FLUME_HOME=/home/hadoop/flume-0.9.0+1
export PATH=.:$FLUME_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
2.2 使用
执行>flume
输出如下:
usage: flume command [args...]
commands include:
dump Takes a specified source and dumps to console
node Start a Flume node/agent (with watchdog)
master Start a Flume Master server (with watchdog)
version Dump flume build version information
node_nowatch Start a flume node/agent (no watchdog)
master_nowatch Start a Flume Master server (no watchdog)
class Run specified fully qualified class using Flume environment (no watchdog)
ex: flume com.cloudera.flume.agent.FlumeNode
classpath Dump the classpath used by the java executables
shell Start the flume shell
启动flume的master节点执行:bin/flume master
通过flume打开文件
输入命令
$ flume dump ‘tail("/home/hadoop/log/bb.txt")‘
输出:
通过flume导入文件到hdfs
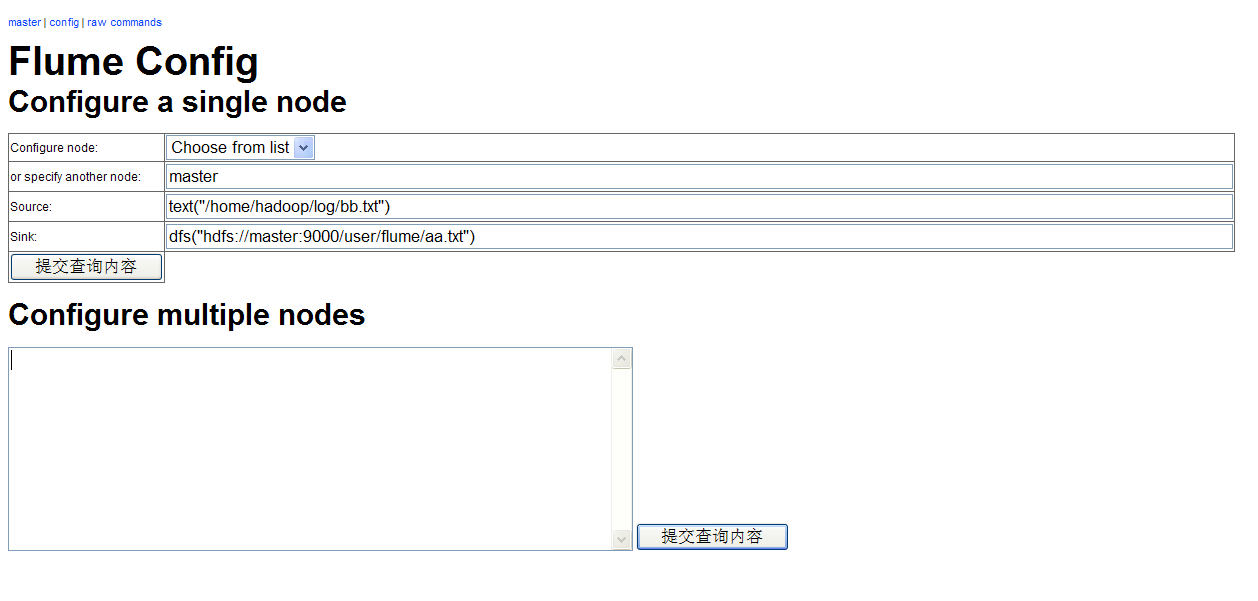
可打开http://10.1.27.30:35871/flumemaster.jsp 即可看到整理节点的情况
从上面URL打开的选项卡config,输入节点配置,然后点提交查询内容
如下:
Source为数据源,可有多种输入源,sink为接收器,当启动master节点时,会把文件写入到hdsf里
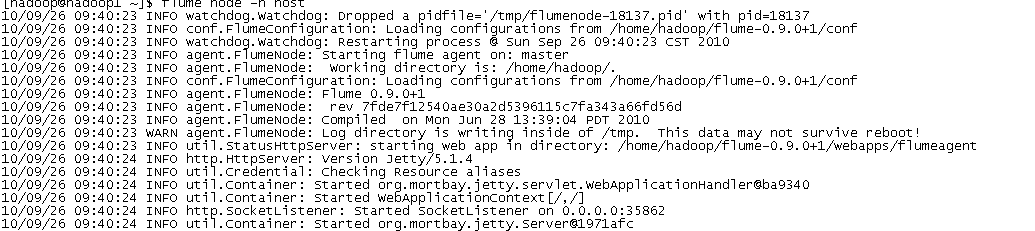
启动配置好的节点:bin/flume node –n master
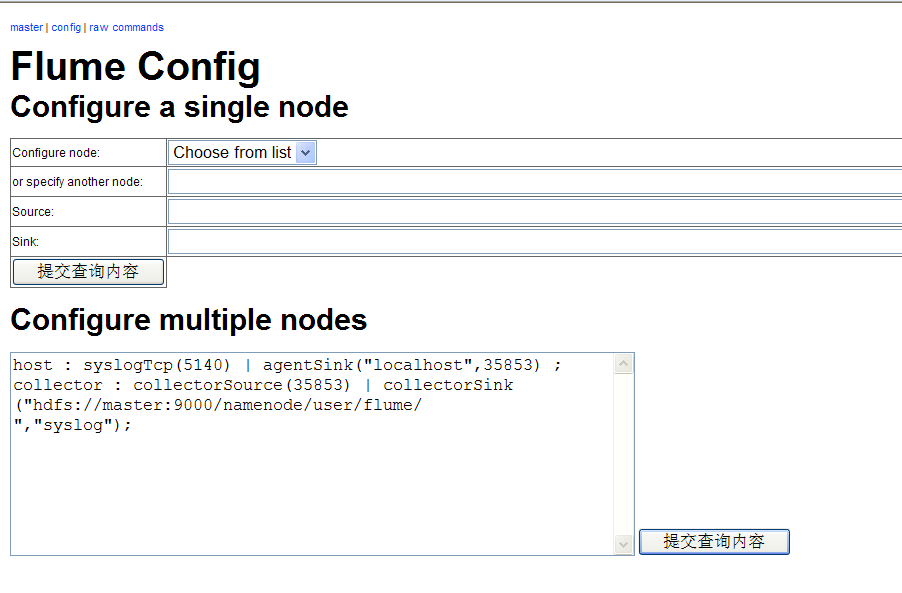
通过flume读取syslog-ng
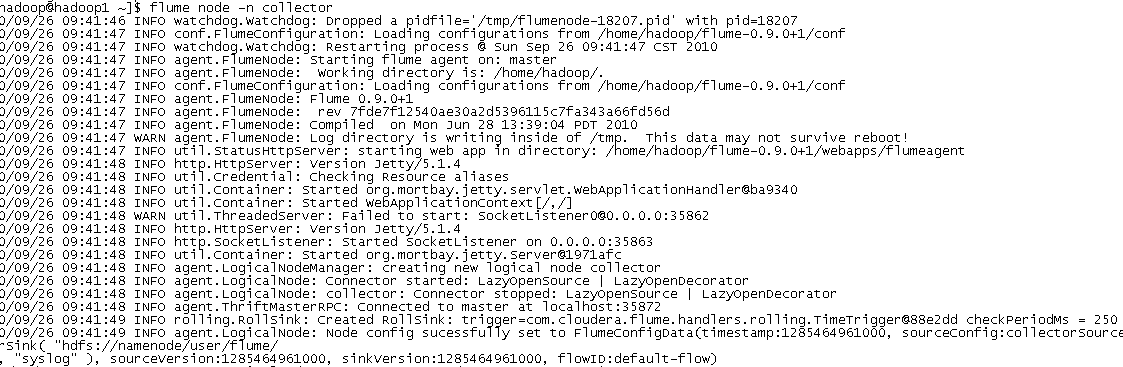
分别启动节点host和collector节点
3.附录:
Flume Event
Sources console
Stdin console
text("filename")
One shot text file source. One line is one event
tail("filename")
Similar to Unix’s tail -F. One line is one event. Stays open for more data and follows filename if file rotated.
multitail("file1"[, "file2"[, …]])
Similar to tail source but follows multiple files.
asciisynth(msg_count,msg_size)
A source that synthetically generates msg_count random messages of size msg_size. This converts all characters into printable ASCII characters.
syslogUdp(port)
Syslog over UDP port, port. This is syslog compatible.
syslogTcp(port)
Syslog over TCP port, port. This is syslog-ng compatible.
Flume Event Sinks
|
|
Null sink. Events are dropped.
|
|
|
Console sink. Display to console’s stdout. The "format" argument is optional and defaults to the "debug" output format.
|
text("txtfile"[,"format"])
|
Textfile sink. Write the events to text file txtfile using output format "format". The default format is "raw" event bodies with no metadata.
|
|
|
DFS seqfile sink. Write serialized Flume events to a dfs path such as hdfs://namenode/file or file:///file in Hadoop’s seqfile format. Note that because of the hdfs write semantics, no data for this sink write until the sink is closed.
|
|
|
Syslog TCP sink. Forward to events to host on TCP port port in syslog wire format (syslog-ng compatible), or to other Flume nodes setup to listen for syslogTcp.
|
默认端口如下:
TCP ports are used in all situations.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
flume.master.heartbeat.port
|
|
|
|
|
|
|
|
|
|
|
|
flume.master.zk.client.port
|
|
|
|
flume.master.zk.server.quorum.port
|
|
|
|
flume.master.zk.server.election.port
|
|
|