Fully Convolutional Networks for Semantic Segmentation
2021-01-13 15:32
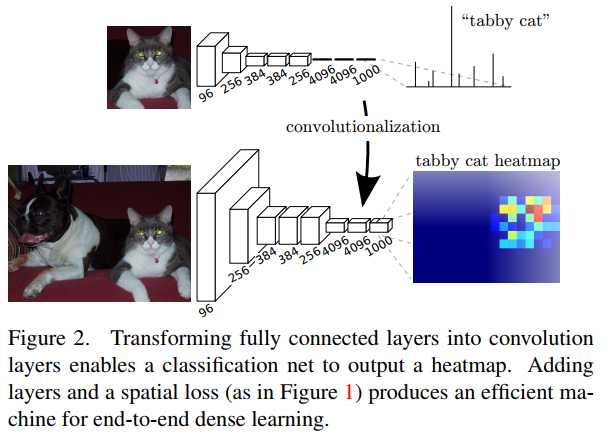
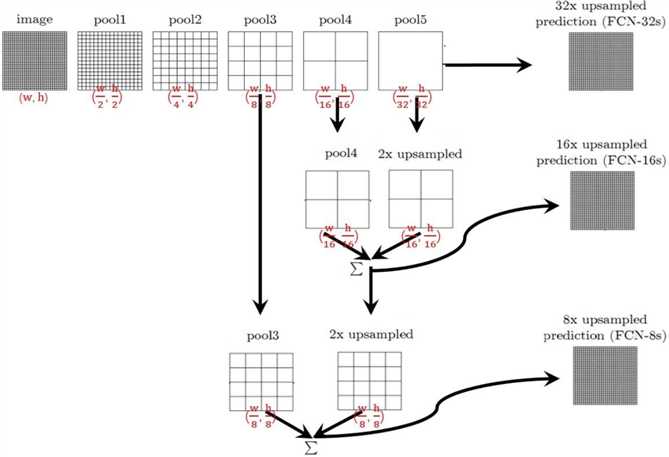
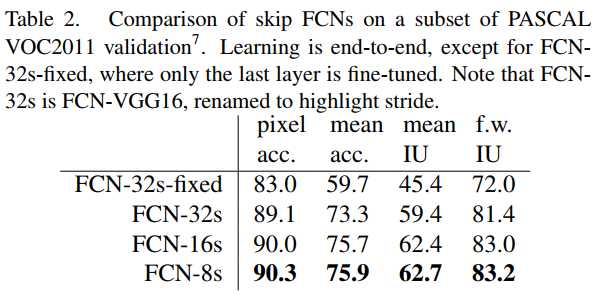
标签:自动 href mic turn ups soft ima return 求和 本文提出全卷积网络(Fully Convolutional Networks, FCN)用于图像语义分割。FCN主要思想是将一般的分类网络(如VGG,ResNet等)最后几层的全连接层替换成卷积层。FCN的好处是可以接受任意尺寸的输入图像。 其中, nij表示将本属于第i类的像素预测为属于第j类的像素数量;ncl表示像素的类别总数;ti表示属于第i类的像素总数, Fully Convolutional Networks for Semantic Segmentation 标签:自动 href mic turn ups soft ima return 求和 原文地址:https://www.cnblogs.com/hejunlin1992/p/13474940.html
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
from torch.utils import model_zoo
from torchvision import models
class FCN8(nn.Module):
def __init__(self, num_classes):
super().__init__()
feats = list(models.vgg16(pretrained=True).features.children())
self.feats = nn.Sequential(*feats[0:9])
self.feat3 = nn.Sequential(*feats[10:16])
self.feat4 = nn.Sequential(*feats[17:23])
self.feat5 = nn.Sequential(*feats[24:30])
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.requires_grad = False
self.fconn = nn.Sequential(
nn.Conv2d(512, 4096, 7),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Conv2d(4096, 4096, 1),
nn.ReLU(inplace=True),
nn.Dropout(),
)
self.score_feat3 = nn.Conv2d(256, num_classes, 1)
self.score_feat4 = nn.Conv2d(512, num_classes, 1)
self.score_fconn = nn.Conv2d(4096, num_classes, 1)
def forward(self, x):
feats = self.feats(x)
feat3 = self.feat3(feats)
feat4 = self.feat4(feat3)
feat5 = self.feat5(feat4)
fconn = self.fconn(feat5)
score_feat3 = self.score_feat3(feat3)
score_feat4 = self.score_feat4(feat4)
score_fconn = self.score_fconn(fconn)
score = F.upsample_bilinear(score_fconn, score_feat4.size()[2:])
score += score_feat4
score = F.upsample_bilinear(score, score_feat3.size()[2:])
score += score_feat3
return F.upsample_bilinear(score, x.size()[2:])

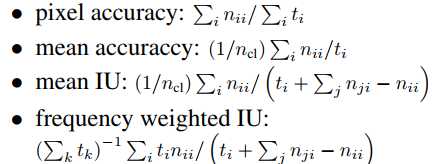
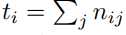
上一篇:前端实现大文件上传
下一篇:【WPF学习】第十四章 事件路由
文章标题:Fully Convolutional Networks for Semantic Segmentation
文章链接:http://soscw.com/index.php/essay/41458.html