Python数据结构
2021-01-14 00:11
标签:遍历 other clear alt proc 结构 -- sleep 函数定义 循环遍历 可以通过成对的list/tuple来构造字典: 通过zip构造字典: from-keys构造字典: 组合字典: 等同于: 以下字典组合方式可能失败,原因在于此方式要求keyword必须为str: 合并两个字典: 支持非str类型的主键: 即便主键重复也没关系: 用lambda表达式来排序,更灵活: 一种最为简练的方式: 队列分类: 方法列表: q.put(): 用以插入数据到队列中 put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。 q.get(): 可以从队列读取并且删除一个元素 get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常. q.get_nowait(): 同q.get(False) q.put_nowait(): 同q.put(False) q.empty(): 调用此方法时q为空则返回True 该结果不可靠,比如在返回True的过程中,如果队列中又加入了项目。 q.full(): 调用此方法时q已满则返回True 该结果不可靠,比如在返回True的过程中,如果队列中的项目被取走。 q.qsize(): 返回队列中目前项目的正确数量 结果也不可靠,理由同q.empty()和q.full()一样 JoinableQueue与Queue一样也是multiprocessing模块中的一个类,也可以用于创建进程队列。 JoinableQueue创建可连接的共享进程队列,队列允许队列的消费者通知生产者,队列数据已被成功处理完成。通知过程是使用共享的信号和条件变量来实现的。 JoinableQueue除了与Queue相同的方法之外,还具有2个特有的方法: q.task_done() 消费者使用此方法发出信号,表示q.get()返回的项目已经被处理完成。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。 q.join() 生产者使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。 更类似C语言的数组,要求每个元素的类型一致。 当你使用 python 创建一个常规 tuple 时,其元素都是通用的,而且没有被命名。这使得你必须记住每个 tuple 元素的精确索引。 因此,namedtuple 让 tuple 的使用更简单、更可读且更有组织性。 Counter本质上是dict的子类,接收一个类似list的迭代器,然后返回一个Counter-Dict。 elements() 获取elements就是将其中的key值乘以出现次数全部打印出来,当然需要通过list或者其他方式将其所有元素全部展示出来(负数不会被打印)。 most_common([n]) 频率最高的前n个字符,输出为 subtract([iterable_or_mapping]) dict-like c += Counter() 这个是最神奇的,就是可以将负数和0的值对应的key项去掉 defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值。默认值由构造函数定义,例如int则默认值为0,list默认值为[]。 两个OrderedDict对象,如果其顺序不同那么Python也会把他们当做是两个不同的对象。 顺序字典的内存消耗大约为dict的两倍(且查询效率并不高),所以需要权衡使用。 Python数据结构 标签:遍历 other clear alt proc 结构 -- sleep 函数定义 原文地址:https://www.cnblogs.com/brt2/p/12945089.html
1. list
append()
extend()
>>> list=[‘a‘,‘b‘,‘c‘]
>>> list.append([‘d‘, ‘e‘])
[‘a‘, ‘b‘, ‘c‘, [‘d‘, ‘e‘] ]
>>> list.extend([‘d‘,‘e‘,‘f‘])
>>> list
[‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘]
pop(n_index)
clear()
remove(item)
reverse()
sort()
copy()
insert(i, x)
2. tuple
3. set
add() # 常见结构仅set有add()方法
update() # set.update(set2), 添加新的元素或集合到当前集合中
copy()
discard()
remove(item)
pop() # 随机删除
clear()
difference # set1-set2
difference_update() # 将差集更新至set1,而不是返回新集合
intersection() # set1 & set2
intersection_update()
isdisjoint() # 判断没有交集,返回True,否则,返回False
union() # 注意没有union_update()
symmetric_difference() # 差集
symmetric_difference_update()
issuperset() # 父集
issubset() # 子集
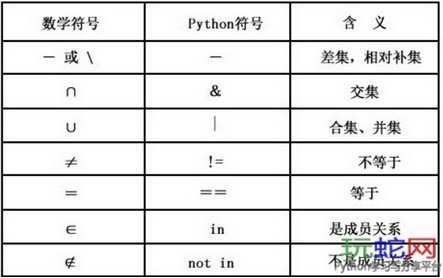
4. dict
d[key] = value
key not in d
del d[key]
get(key[, default])
items() # return: dict_items([(key,value), (key2, value2)...])
keys() # return: dict_keys([1,2,3])
values() # return: dict_values([value1, value2 ...])
pop(key[, default]) # 注意,不同于list的序数删除,也不同于set的随机删除
popitem() # 随机删除某一项,用于逐一删除每个item
update([other]) # dict.update(dict2), 把字典dict2的键/值对更新到dict里
for key in self.dict_:
for key in self.dict_.keys():
for key, value in self.dict_.items():
4.1. 多种方式构造字典对象
items=[(‘name‘,‘earth‘),(‘port‘,‘80‘)]
dict2=dict(items) # {‘name‘: ‘earth‘, ‘port‘: ‘80‘}
dict(zip((‘a‘,‘b‘,‘c‘,‘d‘,‘e‘),(1,2,3,4,5)))
{}.fromkeys((‘x‘,‘y‘),-1) # {‘x‘: -1, ‘y‘: -1}
{}.fromkeys((‘x‘,‘y‘)) # {‘x‘:None, ‘y‘:None}
dictMerged2 = dict(dict1, **dict2)
dictMerged=dict1.copy()
dictMerged.update(dict2)

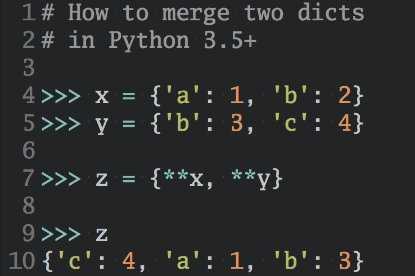
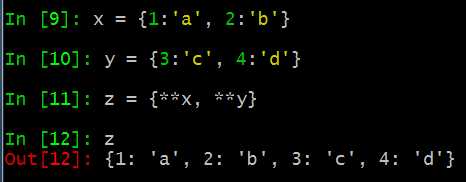
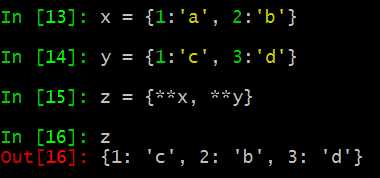
4.2. 字典排序
def func_dict_sort(dict_, sort_type):
""" return a list of sorted """
if sort_type == "ascii":
"""
list_keys = list(dict_.keys())
list_keys.sort()
return [(key, dict_[key]) for key in list_keys]
"""
return [(key, dict_[key]) for key in sorted(dict_.keys())]
elif sort_type == "value":
"""
set_tuple = dict_.items()
list_items_charge = [(tuple_[1], tuple_[0]) for tuple_ in set_tuple]
list_items_charge.sort()
print(list_items_charge)
return [(key[1], key[0]) for key in list_items_charge]
"""
list_items_charge = [(tuple_[1], tuple_[0]) for tuple_ in dict_.items()]
return [(key[1], key[0]) for key in sorted(list_items_charge)]
sorted(d.items(), lambda x, y: cmp(x[1], y[1]))
# 或反序
sorted(d.items(), lambda x, y: cmp(x[1], y[1]), reverse=True)
# 按照key进行排序
print sorted(dict1.items(), key=lambda d: d[0])
# 按照value进行排序
print sorted(dict1.items(), key=lambda d: d[1])
5. Queue
5.1. queue.Queue
5.2. multiprocessing.Queue
5.3. JoinableQueue
from multiprocessing import Process,JoinableQueue
import time,random
def consumer(q):
while True:
time.sleep(random.randint(1,5))
res=q.get()
print(‘消费者拿到了 %s‘ %res)
q.task_done()
def producer(seq,q):
for item in seq:
time.sleep(random.randrange(1,2))
q.put(item)
print(‘生产者做好了 %s‘ %item)
q.join() # 阻塞,直到队列为空(完全消费)
if __name__ == ‘__main__‘:
q=JoinableQueue()
seq=(‘包子%s‘ %i for i in range(10))
p=Process(target=consumer,args=(q,))
p.daemon=True #设置为守护进程,在主线程停止时p也停止,但是不用担心,producer内调用q.join保证了consumer已经处理完队列中的所有元素
p.start()
producer(seq, q)
print(‘主进程结束‘)
6. array
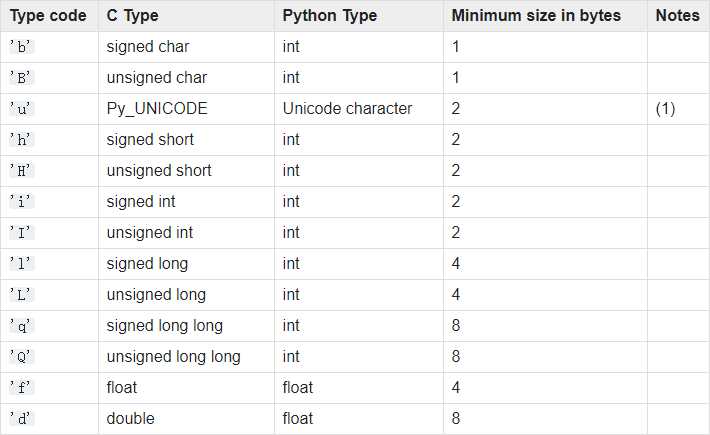
array.itemsize
array.typecode
array.array(typecode[, initializer])
array.frombytes(s)
array.fromlist(list)
array.fromstring()
array.fromunicode(s)
array.tobytes()
array.tolist()
array.tostring()
array.tounicode()
array.count(x)
array.append(x)
array.extend(iterable)
array.pop([i])
array.remove(x)
7. enum
from enum import Enum
>>> class Color(Enum):
... RED = 1
... GREEN = 2
... BLUE = 3
>>> print(Color.RED) # or Color[‘RED‘]
>>> from enum import Enum
>>> Month = Enum(‘Month‘,(‘Jan‘,‘Feb‘,‘Mar‘,‘Apr‘,‘May‘,‘Jun‘,‘Jul‘,‘Aug‘,‘Sep‘,‘Oct‘,‘Nov‘,‘Dec‘))
>>> for name,member in Month.__members__.items():
print(name,‘=>‘,member,‘,‘,member.value)
(‘Jan‘, ‘=>‘, 8. collections
8.1. collections.namedtuple
namedtuple 就可以解决这个问题。Point = namedtuple(‘My_Point‘, [‘x‘, ‘y‘])
>>> p = Point(11, y=22) # p = My_Point(x=11, y=22)
>>> p[0] + p[1] # indexable like the plain tuple (11, 22)
33
>>> p.x + p.y # fields also accessible by name
33
8.2. collections.deque
clear()
copy()
count(x)
append(x)
appendleft(x)
extend(iterable)
extendleft(iterable)
insert(i, x)
index(x[, start[, stop]])
pop()
popleft()
remove(value)
reverse()
8.3. collections.Counter
>>> from collections import Counter
>>> c = Counter()
>>> for ch in ‘programming‘:
... c[ch] = c[ch] + 1
...
>>> c
Counter({‘g‘: 2, ‘m‘: 2, ‘r‘: 2, ‘a‘: 1, ‘i‘: 1, ‘o‘: 1, ‘n‘: 1, ‘p‘: 1})

[(key,value), (k2,v2), ...]c.subtract(d)
8.4. collections.defaultdict
from collections import defaultdict
dict_int = defaultdict(int)
dict_int[2] = ‘two‘
dict_str = defaultdict(str)
dict_set = defaultdict(set)
dict_list = defaultdict(list)
print(dict_int[1]) # 0
print(dict_int[2]) # "two"
print(dict_int) # defaultdict(from collections import defaultdict
test_0 = defaultdict(int, {
0: 13,
1: 14,
2: 15,
})
test_1 = defaultdict(int, {
1: 23,
2: 24,
4: 77,
})
output = test_0.copy()
for key, value in test_1.items():
output[key] += value
print(output)
8.5. collections.OrderedDict
OrderedDict([(‘apple‘, 4), (‘banana‘, 3), (‘orange‘, 2), (‘pear‘, 1)])
OrderedDict(sorted(dict_test.items(), key=lambda t: t[0]))
keys()
values()
items()
from collections import OrderedDict
d = OrderedDict()
d[‘foo‘] = 1
d[‘bar‘] = 2
d[‘spam‘] = 3
d[‘grok‘] = 4
# OrderedDict的使用与dict相同,这也是设计的初衷
for key in d.keys():
# for key in d: # 同上
print(key)
for value in d.values():
print(value)
for key, value in d.items():
print(key, value)
下一篇:多线程详解_1