Webpack 原理浅析
2021-01-14 16:14
标签:bundle ams pil 依赖项 loader 实验 file 接收 equal 假设某一天,我们接到了需求,需要开发一个 背景
Webpack 迭代到4.x版本后,其源码已经十分庞大,对各种开发场景进行了高度抽象,阅读成本也愈发昂贵。但是为了了解其内部的工作原理,让我们尝试从一个最简单的 webpack 配置入手,从工具设计者的角度开发一款低配版的 Webpack。开发者视角
react 单页面应用,页面中包含一行文字和一个按钮,需要支持每次点击按钮的时候让文字发生变化。于是我们新建了一个项目,并且在 [根目录]/src 下新建 JS 文件。为了模拟 Webpack 追踪模块依赖进行打包的过程,我们新建了 3 个 React 组件,并且在他们之间建立起一个简单的依赖关系。// index.js 根组件
import React from ‘react‘
import ReactDom from ‘react-dom‘
import App from ‘./App‘
ReactDom.render(App />, document.querySelector(‘#container‘))
// App.js 页面组件
import React from ‘react‘
import Switch from ‘./Switch.js‘
export default class App extends React.Component {
constructor(props) {
super(props)
this.state = {
toggle: false
}
}
handleToggle() {
this.setState(prev => ({
toggle: !prev.toggle
}))
}
render() {
const { toggle } = this.state
return (
div>
h1>Hello, { toggle ? ‘NervJS‘ : ‘O2 Team‘}h1>
Switch handleToggle={this.handleToggle.bind(this)} />
div>
)
}
}
// Switch.js 按钮组件
import React from ‘react‘
export default function Switch({ handleToggle }) {
return (
button onClick={handleToggle}>Togglebutton>
)
}
接着我们需要一个配置文件让 Webpack 知道我们期望它如何工作,于是我们在根目录下新建一个文件 webpack.config.js 并且向其中写入一些基础的配置。(如果不太熟悉配置内容可以先学习webpack中文文档)
// webpack.config.js
const resolve = dir => require(‘path‘).join(__dirname, dir)
module.exports = {
// 入口文件地址
entry: ‘./src/index.js‘,
// 输出文件地址
output: {
path: resolve(‘dist‘),
fileName: ‘bundle.js‘
},
// loader
module: {
rules: [
{
test: /\.(js|jsx)$/,
// 编译匹配include路径的文件
include: [
resolve(‘src‘)
],
use: ‘babel-loader‘
}
]
},
plugins: [
new HtmlWebpackPlugin()
]
}
其中 module 的作用是在 test 字段和文件名匹配成功时就用对应的 loader 对代码进行编译,Webpack本身只认识 .js 、 .json 这两种类型的文件,而通过loader,我们就可以对例如 css 等其他格式的文件进行处理。
而对于 React 文件而言,我们需要将 JSX 语法转换成纯 JS 语法,即 React.createElement 方法,代码才可能被浏览器所识别。平常我们是通过 babel-loader 并且配置好 react 的解析规则来做这一步。
经过以上处理之后。浏览器真正阅读到的按钮组件代码其实大概是这个样子的。
...
function Switch(_ref) {
var handleToggle = _ref.handleToggle;
return _nervjs["default"].createElement("button", {
onClick: handleToggle
}, "Toggle");
}
而至于 plugin 则是一些插件,这些插件可以将对编译结果的处理函数注册在 Webpack 的生命周期钩子上,在生成最终文件之前对编译的结果做一些处理。比如大多数场景下我们需要将生成的 JS 文件插入到 Html 文件中去。就需要使用到 html-webpack-plugin 这个插件,我们需要在配置中这样写。
const HtmlWebpackPlugin = require(‘html-webpack-plugin‘);
const webpackConfig = {
entry: ‘index.js‘,
output: {
path: path.resolve(__dirname, ‘./dist‘),
filename: ‘index_bundle.js‘
},
// 向plugins数组中传入一个HtmlWebpackPlugin插件的实例
plugins: [new HtmlWebpackPlugin()]
};
这样,html-webpack-plugin 会被注册在打包的完成阶段,并且会获取到最终打包完成的入口 JS 文件路径,生成一个形如 的 script 标签插入到 Html 中。这样浏览器就可以通过 html 文件来展示页面内容了。
ok,写到这里,对于一个开发者而言,所有配置项和需要被打包的工程代码文件都已经准备完毕,接下来需要的就是将工作交给打包工具 Webpack,通过 Webpack 将代码打包成我们和浏览器希望看到的样子
工具视角
首先,我们需要了解Webpack打包的流程
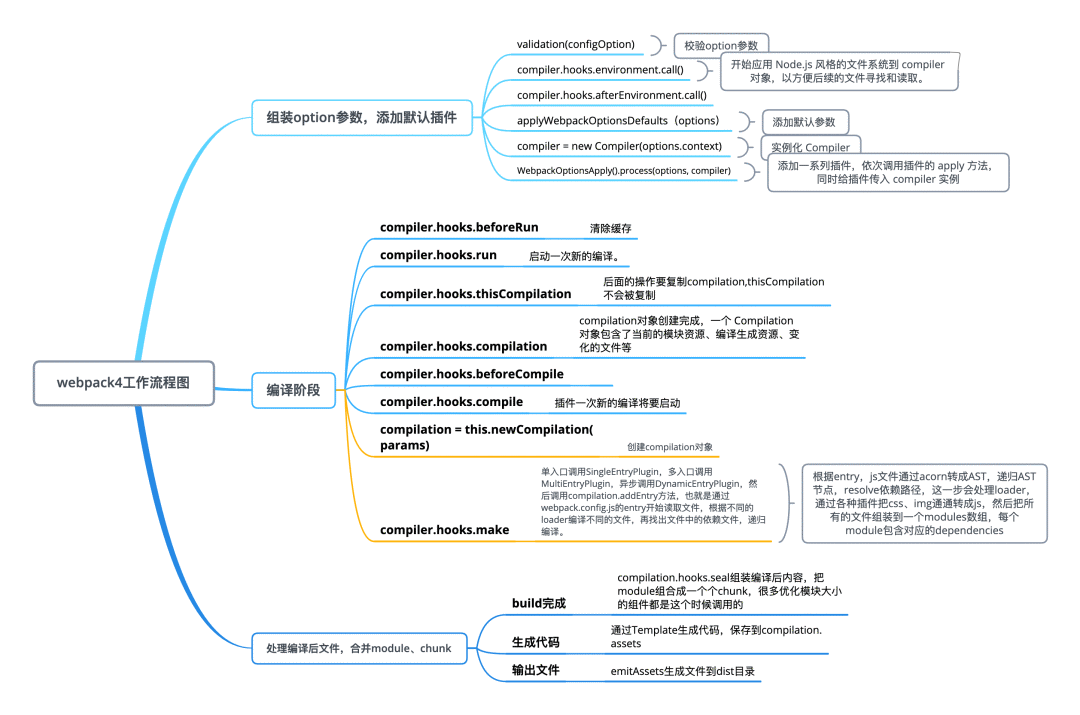
从 Webpack 的工作流程中可以看出,我们需要实现一个 Compiler 类,这个类需要收集开发者传入的所有配置信息,然后指挥整体的编译流程。我们可以把 Compiler 理解为公司老板,它统领全局,并且掌握了全局信息(客户需求)。在了解了所有信息后它会调用另一个类 Compilation 生成实例,并且将所有的信息和工作流程托付给它,Compilation 其实就相当于老板的秘书,需要去调动各个部门按照要求开始工作,而 loader 和 plugin 则相当于各个部门,只有在他们专长的工作( js , css , scss , jpg , png...)出现时才会去处理
为了既实现 Webpack 打包的功能,又只实现核心代码。我们对这个流程做一些简化
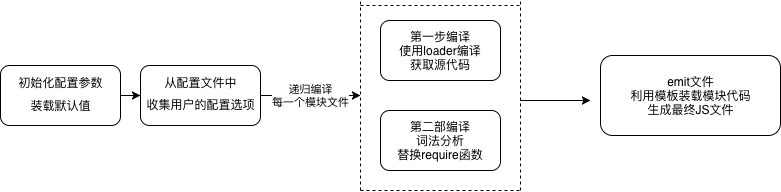
首先我们新建了一个 webpack 函数作为对外暴露的方法,它接受两个参数,其中一个是配置项对象,另一个则是错误回调。
const Compiler = require(‘./compiler‘)
function webpack(config, callback) {
// 此处应有参数校验
const compiler = new Compiler(config)
// 开始编译
compiler.run()
}
module.exports = webpack
1. 构建配置信息
我们需要先在 Compiler 类的构造方法里面收集用户传入的信息
class Compiler {
constructor(config, _callback) {
const {
entry,
output,
module,
plugins
} = config
// 入口
this.entryPath = entry
// 输出文件路径
this.distPath = output.path
// 输出文件名称
this.distName = output.fileName
// 需要使用的loader
this.loaders = module.rules
// 需要挂载的plugin
this.plugins = plugins
// 根目录
this.root = process.cwd()
// 编译工具类Compilation
this.compilation = {}
// 入口文件在module中的相对路径,也是这个模块的id
this.entryId = getRootPath(this.root, entry, this.root)
}
}
同时,我们在构造函数中将所有的 plugin 挂载到实例的 hooks 属性中去。Webpack 的生命周期管理基于一个叫做 tapable 的库,通过这个库,我们可以非常方便的创建一个发布订阅模型的钩子,然后通过将函数挂载到实例上(钩子事件的回调支持同步触发、异步触发甚至进行链式回调),在合适的时机触发对应事件的处理函数。我们在 hooks 上声明一些生命周期钩子:
const { AsyncSeriesHook } = require(‘tapable‘) // 此处我们创建了一些异步钩子
constructor(config, _callback) {
...
this.hooks = {
// 生命周期事件
beforeRun: new AsyncSeriesHook([‘compiler‘]), // compiler代表我们将向回调事件中传入一个compiler参数
afterRun: new AsyncSeriesHook([‘compiler‘]),
beforeCompile: new AsyncSeriesHook([‘compiler‘]),
afterCompile: new AsyncSeriesHook([‘compiler‘]),
emit: new AsyncSeriesHook([‘compiler‘]),
failed: new AsyncSeriesHook([‘compiler‘]),
}
this.mountPlugin()
}
// 注册所有的plugin
mountPlugin() {
for(let i=0;ithis.plugins.length;i++) {
const item = this.plugins[i]
if (‘apply‘ in item && typeof item.apply === ‘function‘) {
// 注册各生命周期钩子的发布订阅监听事件
item.apply(this)
}
}
}
// 当运行run方法的逻辑之前
run() {
// 在特定的生命周期发布消息,触发对应的订阅事件
this.hooks.beforeRun.callAsync(this) // this作为参数传入,对应之前的compiler
...
}
冷知识:
每一个plugin Class都必须实现一个apply方法,这个方法接收compiler实例,然后将真正的钩子函数挂载到compiler.hook的某一个声明周期上。
如果我们声明了一个hook但是没有挂载任何方法,在 call 函数触发的时候是会报错的。但是实际上Webpack的每一个生命周期钩子除了挂载用户配置的plugin,都会挂载至少一个Webpack自己的plugin,所以不会有这样的问题。更多关于tapable的用法也可以移步 Tapable
2. 编译
接下来我们需要声明一个 Compilation 类,这个类主要是执行编译工作。在 Compilation 的构造函数中,我们先接收来自老板 Compiler 下发的信息并且挂载在自身属性中。
class Compilation {
constructor(props) {
const {
entry,
root,
loaders,
hooks
} = props
this.entry = entry
this.root = root
this.loaders = loaders
this.hooks = hooks
}
// 开始编译
async make() {
await this.moduleWalker(this.entry)
}
// dfs遍历函数
moduleWalker = async () => {}
}
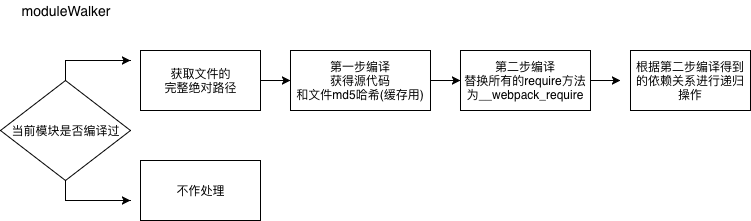
因为我们需要将打包过程中引用过的文件都编译到最终的代码包里,所以需要声明一个深度遍历函数 moduleWalker (这个名字是笔者取的,不是webpack官方取的),顾名思义,这个方法将会从入口文件开始,依次对文件进行第一步和第二步编译,并且收集引用到的其他模块,递归进行同样的处理。
编译步骤分为两步
- 第一步是使用所有满足条件的
loader对其进行编译并且返回编译之后的源代码 - 第二步相当于是
Webpack自己的编译步骤,目的是构建各个独立模块之间的依赖调用关系。我们需要做的是将所有的require方法替换成Webpack自己定义的__webpack_require__函数。因为所有被编译后的模块将被Webpack存储在一个闭包的对象moduleMap中,而__webpack_require__函数则是唯一一个有权限访问moduleMap的方法。
一句话解释 __webpack_require__的作用就是,将模块之间原本 文件地址 -> 文件内容 的关系替换成了 对象的key -> 对象的value(文件内容) 这样的关系。
在完成第二步编译的同时,会对当前模块内的引用进行收集,并且返回到 Compilation 中, 这样moduleWalker 才能对这些依赖模块进行递归的编译。当然其中大概率存在循环引用和重复引用,我们会根据引用文件的路径生成一个独一无二的 key 值,在 key 值重复时进行跳过。
i. moduleWalker 遍历函数
// 存放处理完毕的模块代码Map
moduleMap = {}
// 根据依赖将所有被引用过的文件都进行编译
async moduleWalker(sourcePath) {
if (sourcePath in this.moduleMap) return
// 在读取文件时,我们需要完整的以.js结尾的文件路径
sourcePath = completeFilePath(sourcePath)
const [ sourceCode, md5Hash ] = await this.loaderParse(sourcePath)
const modulePath = getRootPath(this.root, sourcePath, this.root)
// 获取模块编译后的代码和模块内的依赖数组
const [ moduleCode, relyInModule ] = this.parse(sourceCode, path.dirname(modulePath))
// 将模块代码放入ModuleMap
this.moduleMap[modulePath] = moduleCode
this.assets[modulePath] = md5Hash
// 再依次对模块中的依赖项进行解析
for(let i=0;iawait this.moduleWalker(relyInModule[i], path.dirname(relyInModule[i]))
}
}
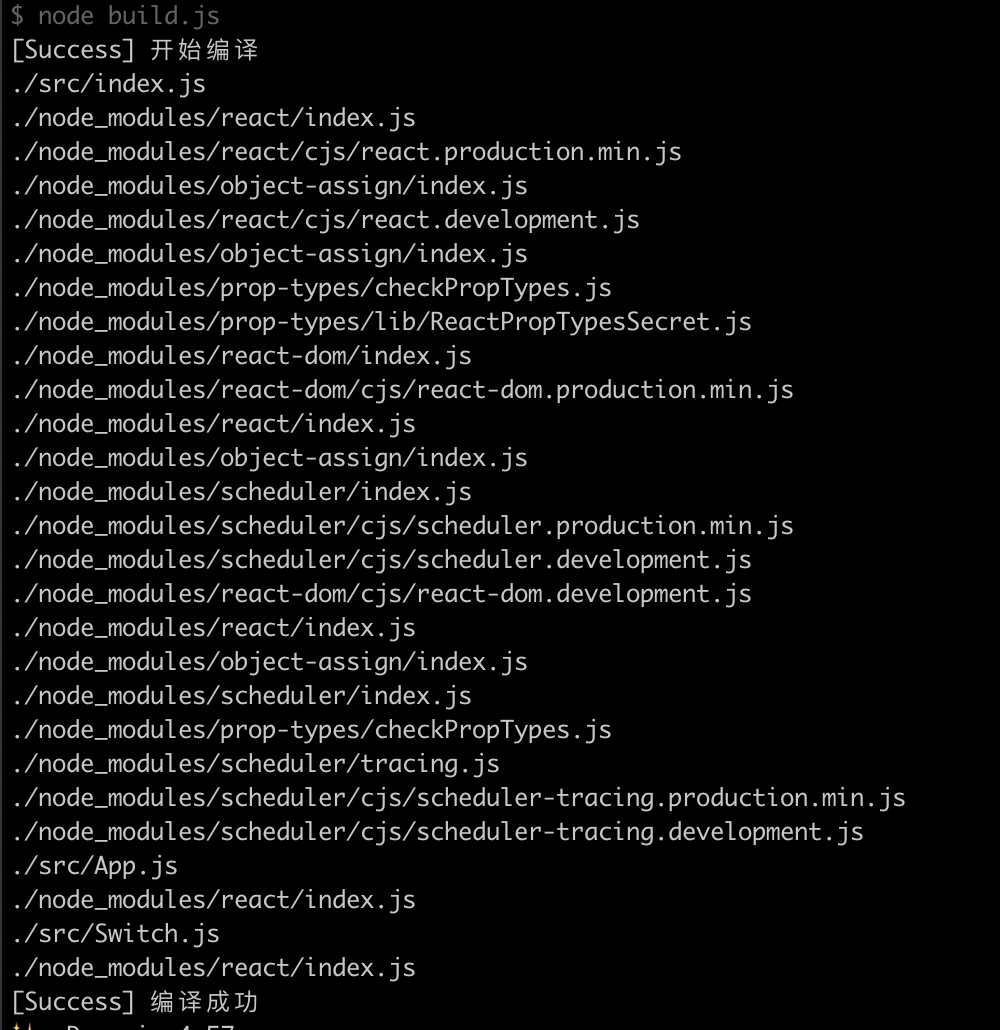
如果将dfs的路径给log出来,我们就可以看到这样的流程
ii. 第一步编译 loaderParse函数
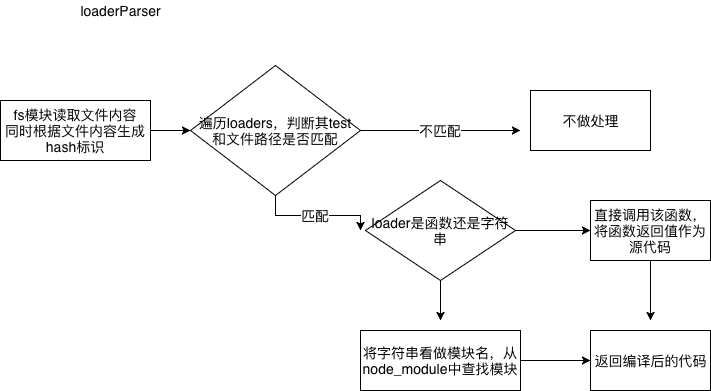
async loaderParse(entryPath) {
// 用utf8格式读取文件内容
let [ content, md5Hash ] = await readFileWithHash(entryPath)
// 获取用户注入的loader
const { loaders } = this
// 依次遍历所有loader
for(let i=0;iconst loader = loaders[i]
const { test : reg, use } = loader
if (entryPath.match(reg)) {
// 判断是否满足正则或字符串要求
// 如果该规则需要应用多个loader,从最后一个开始向前执行
if (Array.isArray(use)) {
while(use.length) {
const cur = use.pop(www.tengyao3zc.cn)
const loaderHandler =
typeof cur.loader === ‘string‘
// loader也可能来源于package包例如babel-loader
? require(cur.loader)
: (
typeof cur.loader === ‘function‘
? cur.loader : _ => _
)
content = loaderHandler(content)
}
} else if (typeof use.loader === ‘string‘) {
const loaderHandler = require(use.loader)
content = loaderHandler(content)
} else if (typeof use.loader === ‘function‘) {
const loaderHandler = use.loader
content =www.shentuylgw.cn loaderHandler(content)
}
}
}
return [ content, md5Hash ]
}
然而这里遇到了一个小插曲,就是我们平常使用的 babel-loader 似乎并不能在 Webpack 包以外的场景被使用,在 babel-loader 的文档中看到了这样一句话
This package allows transpiling JavaScript files using Babel and webpack.
不过好在 @babel/core 和 webpack 并无联系,所以只能辛苦一下,再手写一个 loader 方法去解析 JS 和 ES6 的语法。
const babel = require(‘@babel/core‘)
module.exports www.jujinyule.com= function BabelLoader (source) {
const res = babel.transform(source, {
sourceType: ‘module‘ // 编译ES6 import和export语法
})
return res.code
}
当然,编译规则可以作为配置项传入,但是为了模拟真实的开发场景,我们需要配置一下 babel.config.js文件
module.exports = function (api) {
api.cache(true)
return {
"presets": [
[‘@babel/preset-env‘, {
targets: {
"ie": "8"
},
}],
‘@babel/preset-react‘, www.ued3zc.cn // 编译JSX
],
"plugins": [
["@babel/plugin-transform-template-literals", {
"loose": true
}]
],
"compact": true
}
}
于是,在获得了 loader 处理过的代码之后,理论上任何一个模块都已经可以在浏览器或者单元测试中直接使用了。但是我们的代码是一个整体,还需要一种合理的方式来组织代码之间互相引用的关系。
上面也解释了我们为什么要使用 __webpack_require__ 函数。这里我们得到的代码仍然是字符串的形式,为了方便我们使用 eval 函数将字符串解析成直接可读的代码。当然这只是求快的方式,对于 JS 这种解释型语言,如果一个一个模块去解释编译的话,速度会非常慢。事实上真正的生产环境会将模块内容封装成一个 IIFE(立即自执行函数表达式)
总而言之,在第二部编译 parse 函数中我们需要做的事情其实很简单,就是将所有模块中的 require 方法的函数名称替换成 __webpack_require__ 即可。我们在这一步使用的是 babel 全家桶。 babel 作为业内顶尖的JS编译器,分析代码的步骤主要分为两步,分别是词法分析和语法分析。简单来说,就是对代码片段进行逐词分析,根据当前单词生成一个上下文语境。然后进行再判断下一个单词在上下文语境中所起的作用。
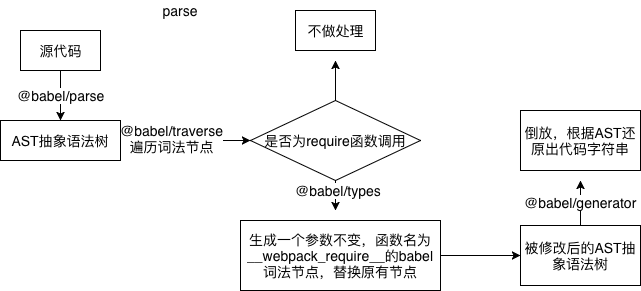
注意,在这一步中我们还可以“顺便”搜集模块的依赖项数组一同返回(用于 dfs 递归)
const parser = require(‘@babel/parser‘)
const traverse www.yunzeyle.cn= require(‘@babel/traverse‘).default
const types = require(‘@babel/types‘)
const generator = require(‘@babel/generator‘).default
...
// 解析源码,替换其中的require方法来构建ModuleMap
parse(source, dirpath) {
const inst = this
// 将代码解析成ast
const ast = parser.parse(source)
const relyInModule = [www.shangdu2zc.cn] // 获取文件依赖的所有模块
traverse(ast, {
// 检索所有的词法分析节点,当遇到函数调用表达式的时候执行,对ast树进行改写
CallExpression(p) {
// 有些require是被_interopRequireDefault包裹的
// 所以需要先找到_interopRequireDefault节点
if (p.node.callee && p.node.callee.name === ‘_interopRequireDefault‘) {
const innerNode = p.node.arguments[0]
if (innerNode.callee.name === ‘require‘) {
inst.convertNode(innerNode, dirpath, relyInModule)
}
} else if (p.node.callee.name === ‘require‘) {
inst.conv www.lecaixuanzc.cn ertNode(p.node, dirpath, relyInModule)
}
}
})
// 将改写后的ast树重新组装成一份新的代码, 并且和依赖项一同返回
const moduleCode = generator(ast).code
return [ moduleCode, relyInModule ]
}
/**
* 将某个节点的name和arguments转换成我们想要的新节点
*/
convertNode = (node, dirpath, relyInModule) => {
node.callee.name = ‘__webpack_require__‘
// 参数字符串名称,例如‘react‘, ‘./MyName.js‘
let moduleName = node.arguments[0].value
// 生成依赖模块相对【项目根目录】的路径
let moduleKey = completeFilePath(getRootPath(dirpath, moduleName, this.root))
// 收集module数组
relyInModule.push(moduleKey)
// 替换__webpack_require__的参数字符串,因为这个字符串也是对应模块的moduleKey,需要保持统一
// 因为ast树中的每一个元素都是babel节点,所以需要使用‘@babel/types‘来进行生成
node.arguments = [www.lcx528.cn types.stringLiteral(moduleKey) ]
}
3. emit 生成bundle文件
执行到这一步, compilation 的使命其实就已经完成了。如果我们平时有去观察生成的 js 文件的话,会发现打包出来的样子是一个立即执行函数,主函数体是一个闭包,闭包中缓存了已经加载的模块 installedModules ,以及定义了一个 __webpack_require__ 函数,最终返回的是函数入口所对应的模块。而函数的参数则是各个模块的 key-value 所组成的对象。
我们在这里通过 ejs 模板去进行拼接,将之前收集到的 moduleMap 对象进行遍历,注入到ejs模板字符串中去。
模板代码
// template.ejs
(function(modules) { // webpackBootstrap
// The module cache
var installedModules = {};
// The require function
function __webpack_require__(moduleId) {
// Check if module is in cache
if(installedModules[moduleId]) {www.leguojizc.cn
return installedModules[moduleId].exports;
}
// Create a new module (and put it into the cache)
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
// Execute the module function
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
// Flag the module as loaded
module.l = true;
// Return the exports of the module
return module.exports;
}
// Load entry module and return exports
return __webpack_require__(www.leyouzaixan.cn__webpack_require__.s = "");
})({
for(let key in modules) {%>
"":
(function(module, exports, __webpack_require__) {
eval(
``
);
}),
});
生成bundle.js
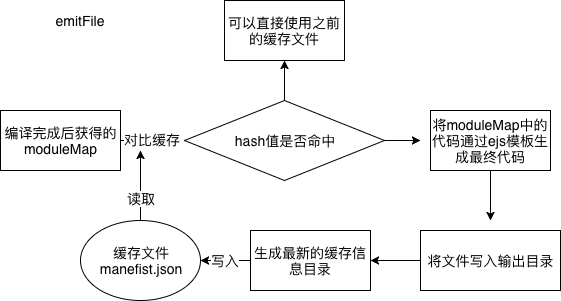
/**
* 发射文件,生成最终的bundle.js
*/
emitFile() { // 发射打包后的输出结果文件
// 首先对比缓存判断文件是否变化
const assets = this.compilation.assets
const pastAssets = this.getStorageCache()
if (loadsh.isEqual(assets, pastAssets)) {
// 如果文件hash值没有变化,说明无需重写文件
// 只需要依次判断每个对应的文件是否存在即可
// 这一步省略!
} else www.guanghuiyl.cn{
// 缓存未能命中
// 获取输出文件路径
const outputFile = path.join(this.distPath, this.distName);
// 获取输出文件模板
// const templateStr = this.generateSourceCode(path.join(__dirname, ‘..‘, "bundleTemplate.ejs"));
const templateStr = fs.readFileSync(path.join(__dirname, ‘..‘, "template.ejs"), ‘utf-8‘);
// 渲染输出文件模板
const code = ejs.render(templateStr, {entryId: this.entryId, modules: this.compilation.moduleMap});
this.assets = {};
this.assets[outputFile] = code;
// 将渲染后的代码写入输出文件中
fs.writeFile(outputFile, this.assets[outputFile], function(e) {
if (www.fanhji.cn) {
console.log(‘[Error] ‘ + e)
} else {
console.log(‘[Success] 编译成功‘)
}
});
// 将缓存信息写入缓存文件
fs.writeFileSync(resolve(this.distPath, ‘manifest.json‘), JSON.stringify(assets, null, 2))
}
}
在这一步中我们根据文件内容生成的 Md5Hash 去对比之前的缓存来加快打包速度,细心的同学会发现 Webpack 每次打包都会生成一个缓存文件 manifest.json,形如
{
"main.js": "./js/main7b6b4.js",
"main.css": www.txinyl.cn"./css/maincc69a7ca7d74e1933b9d.css",
"main.js.map": "./js/main7b6b4.js.map",
"vendors~main.js": "./js/vendors~main3089a.js",
"vendors~main.css": "./css/vendors~maincc69a7ca7d74e1933b9d.css",
"vendors~main.js.map": "./js/vendors~main3089a.js.map",
"js/28505f.js": "./js/28505f.js",
"js/28505f.js.map": "./js/28505f.js.map",
"js/34c834.js": "./js/34c834.js",
"js/34c834.js.map": "./js/34c834.js.map",
"js/4d218c.js": "./js/4d218c.js",
"js/4d218c.js.map":www.yinm3zc.cn "./js/4d218c.js.map",
"index.html": "./index.html",
http://www.jintianxuesha.com/?id=885
"static/initGlobalSize.js": "./static/initGlobalSize.js"
}
这也是文件断点续传中常用到的一个判断,这里就不做详细的展开了
检验
做完这一步,我们已经基本大功告成了(误:如果不考虑令人智息的debug过程的话),接下来我们在 package.json 里面配置好打包脚本
"scripts": {
"build": "node build.js"
}
运行 yarn build
(@ο@) 哇~激动人心的时刻到了。
然而...
看着打包出来的这一坨奇怪的东西报错,心里还是有点想笑的。检查了一下发现是因为反引号遇到注释中的反引号于是拼接字符串提前结束了。好吧,那么我在 babel traverse 时加了几句代码,删除掉了代码中所有的注释。但是随之而来的又是一些其他的问题。
好吧,可能在实际 react 生产打包中还有一些其他的步骤,但是这不在今天讨论的话题当中。此时,鬼魅的框架涌上心头。我脑中想起了京东凹凸实验室自研的高性能,兼容性优秀,紧跟 react 版本的类react框架 NervJS ,或许 NervJS 平易近人(误)的代码能够支持这款令人抱歉的打包工具
于是我们在 babel.config.js 中配置alias来替换 react 依赖项。(React项目转NervJS就是这么简单)
module.exports = function (api) {
api.cache(true)
return {
...
"plugins": [
...
[
"module-resolver", {
"root": ["."],
"alias": {
"react": "nervjs",
"react-dom": "nervjs",
// Not necessary unless you consume a module using `createClass`
"create-react-class": "nerv-create-class"
}
}
]
],
"compact": true
}
}
运行 yarn build


(@ο@) 哇~代码终于成功运行了起来,虽然存在着许多的问题,但是至少这个 webpack 在设计如此简单的情况下已经有能力支持大部分JS框架了。感兴趣的同学也可以自己尝试写一写,或者直接从这里clone下来看
毫无疑问,Webpack 是一个非常优秀的代码模块打包工具(虽然它的官网非常低调的没有任何slogen)。一款非常优秀的工具,必然是在保持了自己本身的特性的同时,同时能够赋予其他开发者在其基础上拓展设想之外作品的能力。如果有能力深入学习这些工具,对于我们在代码工程领域的认知也会有很大的提升。
Webpack 原理浅析
标签:bundle ams pil 依赖项 loader 实验 file 接收 equal
原文地址:https://www.cnblogs.com/woshixiaowang/p/13418597.html
上一篇:web信息收集-搜索引擎