对 【Sequence to Sequence Learning with Neural Networks】的理解
2021-01-14 16:15
标签:图像 实现 googl https 性能提升 深度 embed 随机 获得 本文是对Sequence to Sequence Learning with Neural Networks文章阅读后的总结。 普通RNN能够有效捕捉序列数据(如文本数据)的语义信息,并映射生成新的序列数据,但RNN对长距离依赖表现不好,同时由于训练时存在梯度弥散和梯度爆炸而难以训练,因此作者使用LSTM代替RNN。 数据集使用WMT‘14 dataset,是英语到法语翻译,文中表示训练了12M的句子,共包括348M个法语词汇和304M个英语词汇,其中涉及最常用的unique英语单词160000个及unique法语单词80000个,对于词表外的单词使用 原文作者发现使用源句子在训练时,将句子的顺序逆序输入(目标句子不逆序)会获得不错的性能提升,如ppl从5.8变为4.7, BLEU score从 25.9变为30.6 LSTM使用C++实现,整个网络共8层LSTM,使用8块GPU计算,并使每块GPU跑一层LSTM, 每秒单词处理数从1700升至为6300 使用beam search来优化计算速度 对长句子及不同句子的词频rank实验 对 【Sequence to Sequence Learning with Neural Networks】的理解 标签:图像 实现 googl https 性能提升 深度 embed 随机 获得 原文地址:https://www.cnblogs.com/andre-ma/p/13417352.html零、背景及引言
在不同的学习任务中,传统深度神经网络(DNN)是表现不错的强力模型,如在图像分类、语音识别领域,但DNN由于不能适应输入输出不固定的情况,导致其不能够用于序列到序列的映射任务。 在2014年,Google的三位作者提出基于端到端的序列到序列模型:本质上是由2个4层的LSTM来分别构成编码器和解码器。实验结果表明:在机器翻译领域,达到了SOTA效果,好于传统的统计机器翻译(SMT)。一、模型及训练
1.1 模型介绍
论文中的Seq2Seq模型是由2个4层的LSTM来分别构成编码器和解码器。训练时对对每个句子结尾加入标志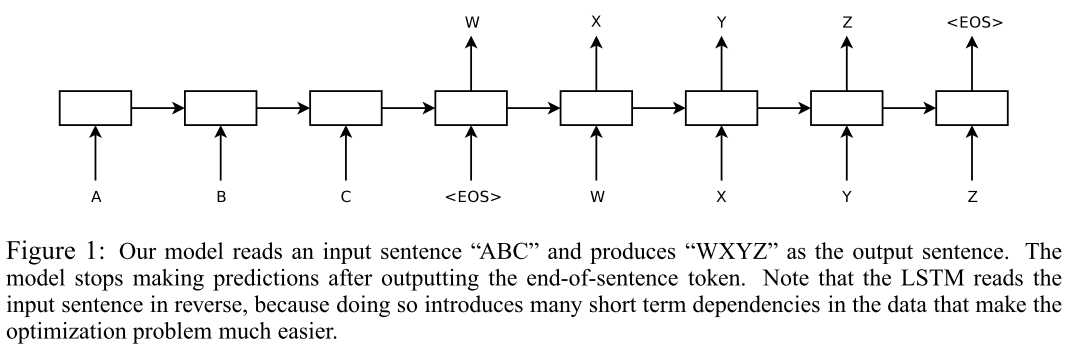
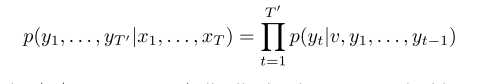
1.2 数据集及评价指标
1.3 输入句子反转
1.4 并行化
1.5 几点训练细节
二、实验结果
beam size 分别为1、2、12,并使用ensemble集成来优化结果, 具体实验结果如下图: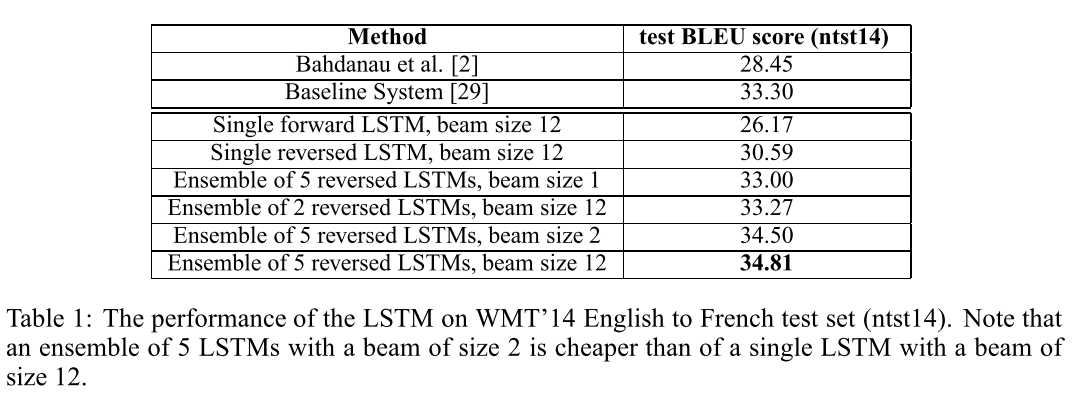
模型对长句子处理效果蛮好,对句子的词频rank测试发现翻译效果先上升后逐步下降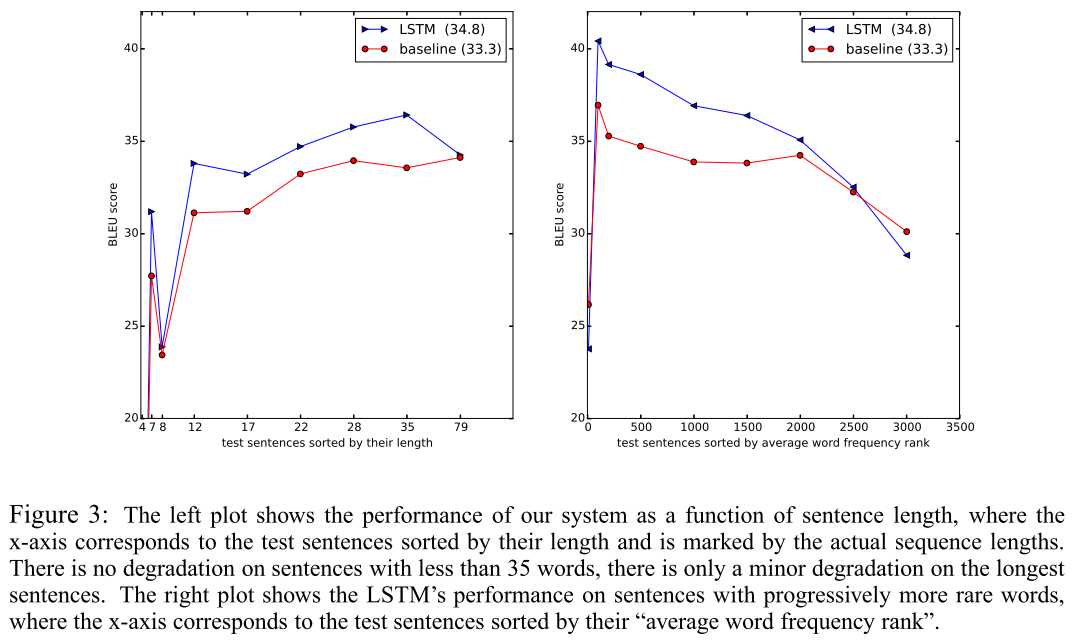
三、个人总结
四、参考
文章标题:对 【Sequence to Sequence Learning with Neural Networks】的理解
文章链接:http://soscw.com/index.php/essay/41857.html