爬取一张网页(retrieve)
2021-01-16 05:13
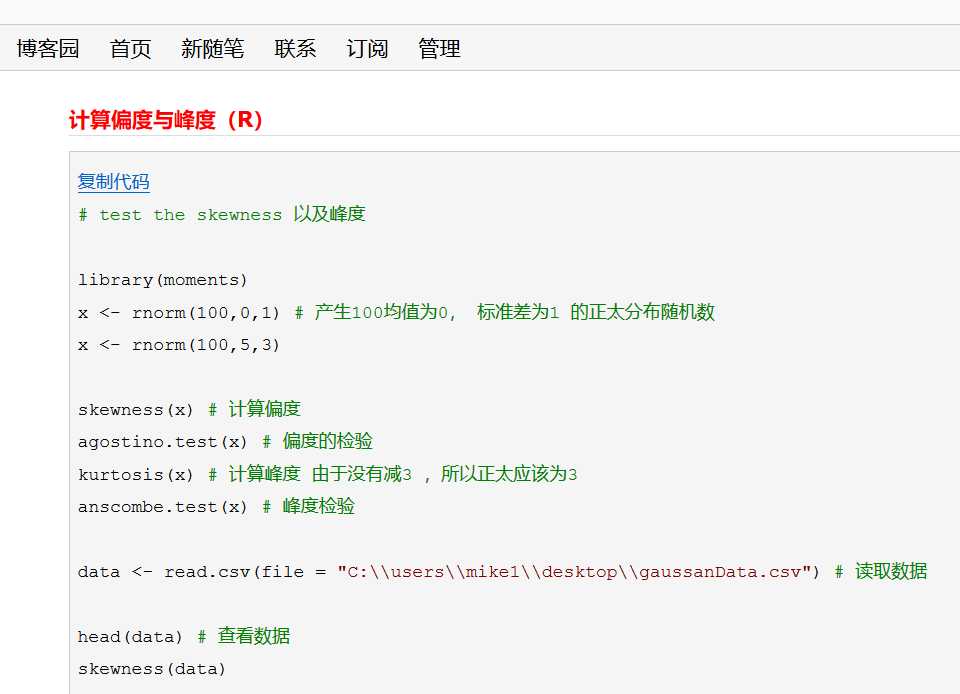
标签:hand lib color image list logs blog pool uil 下图为爬取取得html网页 爬取一张网页(retrieve) 标签:hand lib color image list logs blog pool uil 原文地址:https://www.cnblogs.com/zijidefengge/p/13383016.html# 设置爬虫的用户代理池以及ip代理池
import urllib.request
import random
def set_user_ip_proxy():
#设置用户代理池
header_list = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"]
#设置ip池
ip_pools = ["123.54.44.4:9999","110.243.13.120:9999", "183.166.97.101:9999"]
#构建ip代理以及用户代理
random_ip = random.choice(ip_pools)
creat_ip = urllib.request.ProxyHandler({"http" : random_ip})
creat_opener = urllib.request.build_opener(creat_ip)
header = ("User-Agent", random.choice(header_list))
creat_opener.addheaders = [header]
urllib.request.install_opener(creat_opener)
print("当前的header是:", header)
print("当前的ip是:",random_ip)
return 0
for i in range(2):
try:
set_user_ip_proxy()
urllib.request.urlretrieve("https://www.cnblogs.com/zijidefengge/p/12445145.html", "C:/users/mike1/desktop/" + str(i) + ".html")
except Exception as error:
continue