使用Jsoup和htmlunit爬取动态网页
2021-01-16 23:12
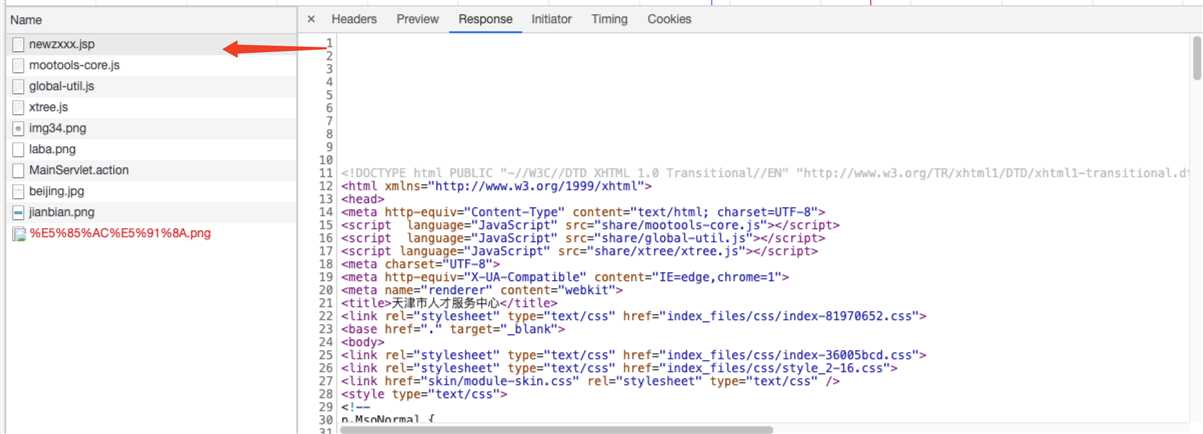
标签:回调 span soup cli 模拟浏览器 支持 取整 image load 在对http://zkgg.tjtalents.com.cn/newzxxx.jsp这个网页爬取内容时,如果只使用Jsoup进行解析的话,起内部的a href标签内容无法获取到。 但是实际上通过 获取到的文档只是newzxxx.jsp中respose的内容。 实际我们想要的内容通过js加载得到的。 所以这种情况我们可以使用htmlunit来模拟浏览器,并且等待js加载完毕后,再读取整个页面。 这样的话就能够获取全部的html页面,之后再使用Jsoup来对页面进行解析即可,这里就不放上Jsoup的代码了。 使用Jsoup和htmlunit爬取动态网页 标签:回调 span soup cli 模拟浏览器 支持 取整 image load 原文地址:https://www.cnblogs.com/silentteller/p/13373304.html

Document doc = Jsoup.connect(url).get();
function query(){
$("formzx").fid.value = "C09.01.01.05";
$("formzx").set(‘send‘,{
url: ‘MainServlet.action‘,
onRequest: function(){
},
//成功的回调函数
onSuccess: function(responseText){
$(‘listspan‘).innerHTML = responseText;
},
//失败的回调函数. 404. 500. 以及返回JSON串success为false时执行
onFailure: function(responseText){
$(‘listspan‘).innerHTML = responseText;
}
});
$("formzx").send();
}
public String getPageWaitJS (String url) throws IOException {
WebClient webClient = new WebClient();
webClient.getOptions().setJavaScriptEnabled(true); //启用JS解释器,默认为true
webClient.getOptions().setCssEnabled(false); //禁用css支持
webClient.getOptions().setThrowExceptionOnScriptError(false); //js运行错误时,是否抛出异常
HtmlPage page = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(3*1000);
String pageXml = page.asXml(); //以xml的形式获取响应文本
return pageXml;
}
文章标题:使用Jsoup和htmlunit爬取动态网页
文章链接:http://soscw.com/index.php/essay/42921.html