python爬虫-静态爬取豆瓣评论
2021-01-17 07:15
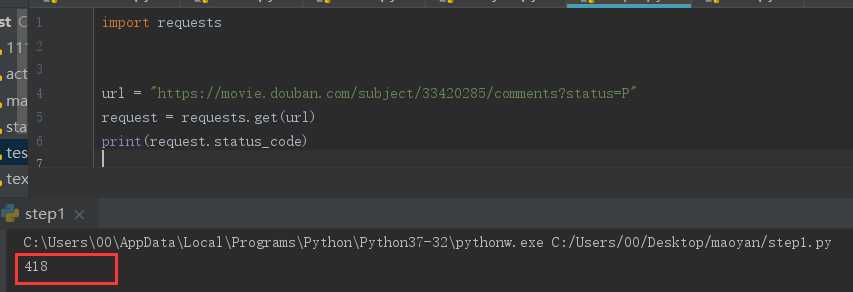
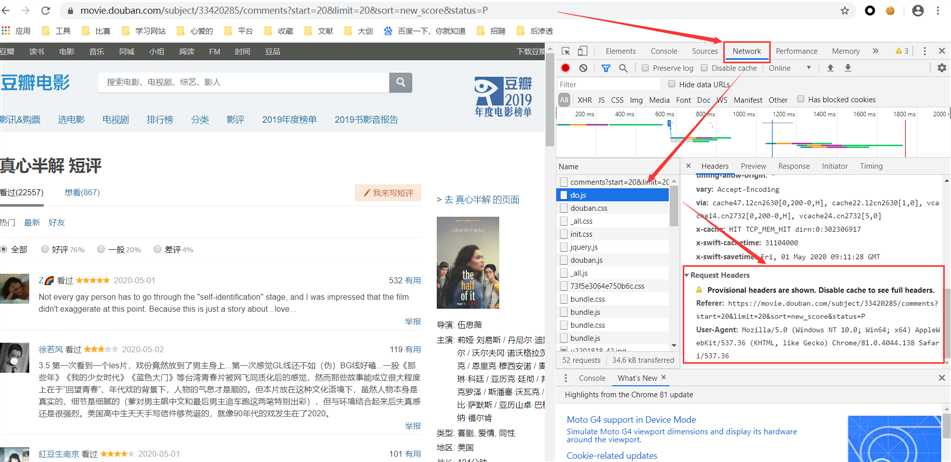
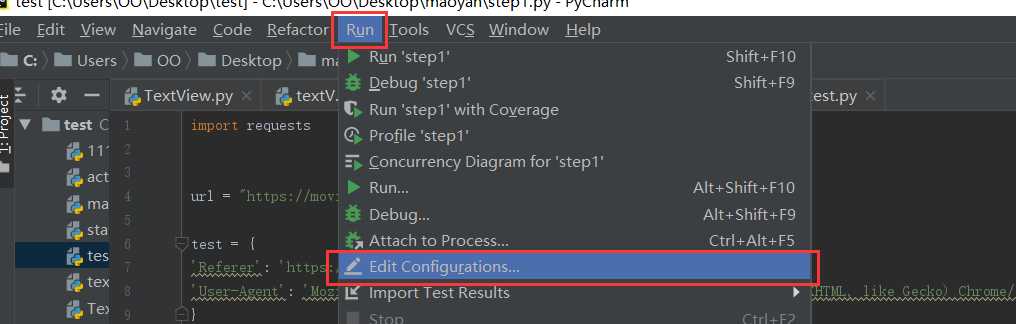
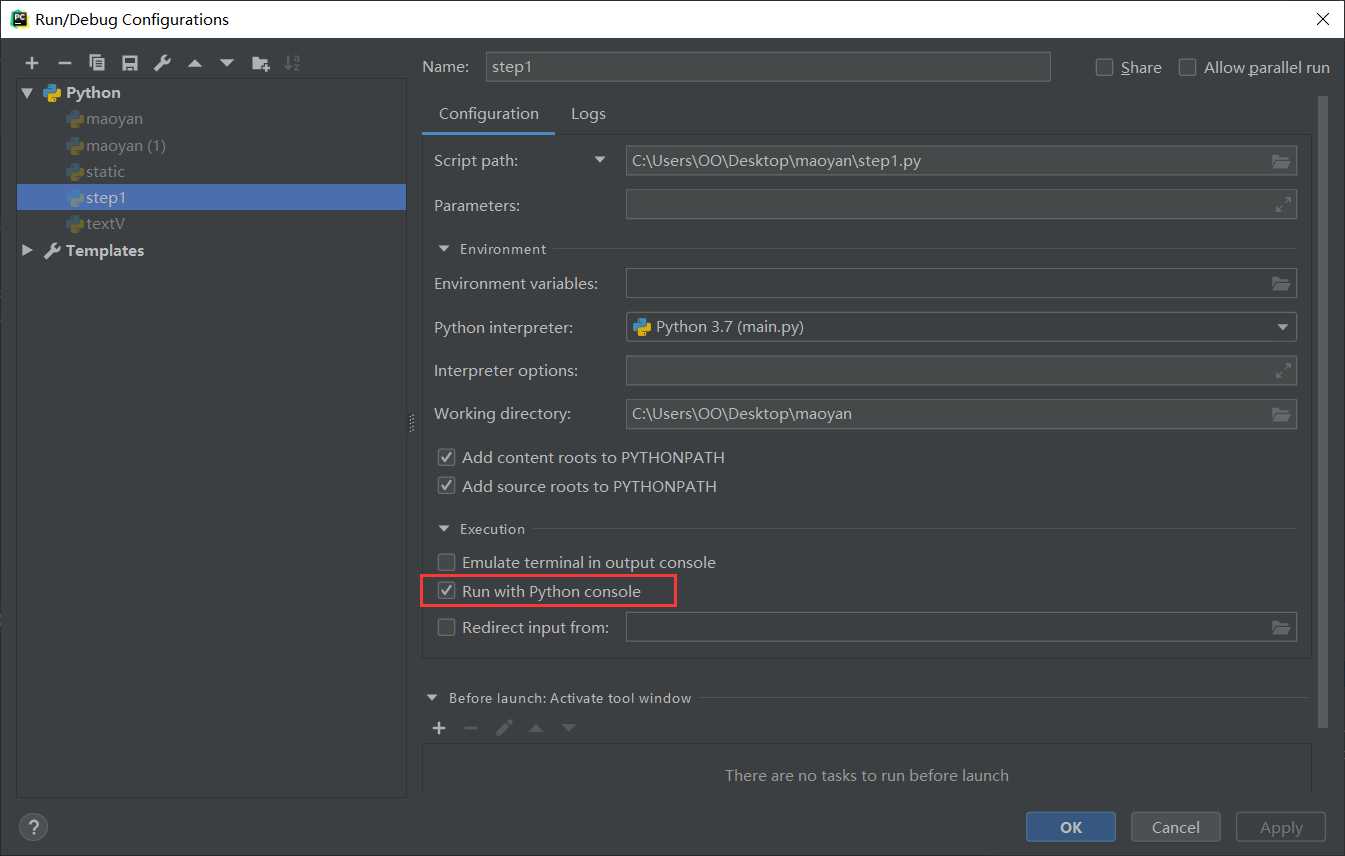
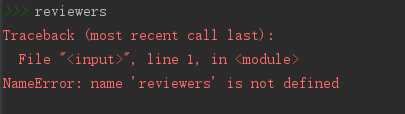
标签:safari 指定位置 分析 覆盖 技术 http status ext utf-8 分析: 我们写代码的步骤是第一步:判断是否设置反爬机制,第二步:先爬取整个网页,第三步:再提取想要的内容,第四步:最后保存到本地。明白了我们要做什么再一步一步的去做 step1:判断是否设置反爬 requests.get(url,params = None,headers = None,cookies = None,auth = None,timeout =无)发送GET请求。 返回Response对象,其存储了服务器响应的内容。 打印出响应的状态码,如果为418则是设置了反爬机制,如果是200,就ok。 可以看到状态码为418,那么就需要绕过反爬,设置head 将request headers中的User-Agent加上 此时状态码就为200了,进行下一步 step2:抓取页面内容 可以print(html),也可以在python console中查看爬取的网页源码 切换到python console运行的方法为: 选择菜单栏 然后勾选 step3:提取有效内容 F12,选择要爬取的内容,然后右键copy,得到内容为 dom.selec()将指定位置处的内容转换为文档类型,使用了一个i.getText() for i in 循环,表示将dom.select得到的列表中的每一个元素都经过getText()处理。getText()代表将获取的列表提取出其中的文本,不要html等结构。 此时可以看到我们想要的单独的数据 shift+alt+e 选中区域可以单独运行选中的代码 但是现在只有第一页的数据,要怎么样才能爬取很多页的数据呢?就要用到循环 每一页的操作都是一样的,唯一不同的就是url,每一页的不同 第一页:https://movie.douban.com/subject/33420285/comments?start=0&limit=20&sort=new_score&status=P 第二页:https://movie.douban.com/subject/33420285/comments?start=20&limit=20&sort=new_score&status=P 第三页:https://movie.douban.com/subject/33420285/comments?start=40&limit=20&sort=new_score&status=P 可以看到是start值发生了变化,那么我们就可以改变start的值来循环 将start的值设为参数i,参与循环从0到100,步数20,也就是0、20、40、60、80、100,循环6次。 以下的内容都要缩进到for循环中。 要注意的一点是,都要加上reviewers+ 、dates+ 、shot_comments+ 、votes+ ,因为如果不加的话,光是 那么第二次循环就会覆盖掉前一次获取到的reviewers值,第三次循环又会覆盖掉第二次循环的值。。。所以加上reviewers表示追加,就不会覆盖掉内容了 step4:保存到本地,在代码最后加上 运行完整代码,如果提示 那么就在循环前先定义一下,reviewers = [] python爬虫-静态爬取豆瓣评论 标签:safari 指定位置 分析 覆盖 技术 http status ext utf-8 原文地址:https://www.cnblogs.com/xiaoxiaosen/p/12919043.htmlfrom bs4 import BeautifulSoup
import requests
import pandas as pd
header = {
‘Referer‘: ‘https://movie.douban.com/subject/33420285/comments?status=P‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36‘
}
reviewers = []
dates = []
shot_comments = []
votes = []
for i in range(0,100,20):
url=f‘https://movie.douban.com/subject/33420285/comments?start={i}&limit=20&sort=new_score&status=P‘
request = requests.get(url,headers=header)
html = request.content.decode(‘utf-8‘)
dom = BeautifulSoup(html,‘lxml‘)
reviewers = reviewers + [i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > a‘)]
dates = dates + [i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > span.comment-time‘)]
shot_comments = shot_comments + [i.getText() for i in dom.select(‘#comments > div > div.comment > p > span‘)]
votes = votes+ [i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-vote > span‘)]
short = pd.DataFrame({
‘时间‘:dates,‘评论者‘:reviewers,‘留言‘:shot_comments,‘票数‘:votes
})
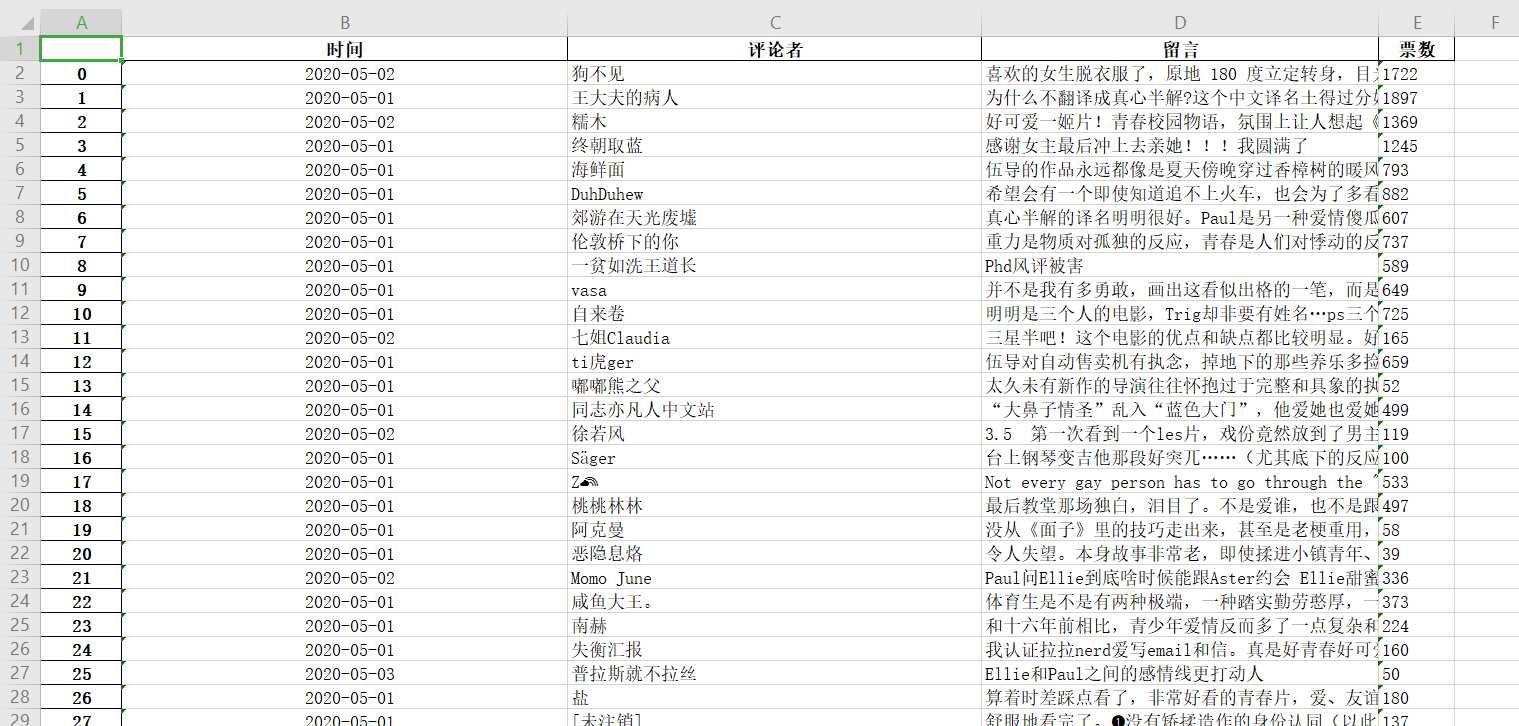
short.to_excel(‘./short.xlsx‘)import requests
url = "https://movie.douban.com/subject/33420285/comments?status=P"
request = requests.get(url)
print(request.status_code)
import requests
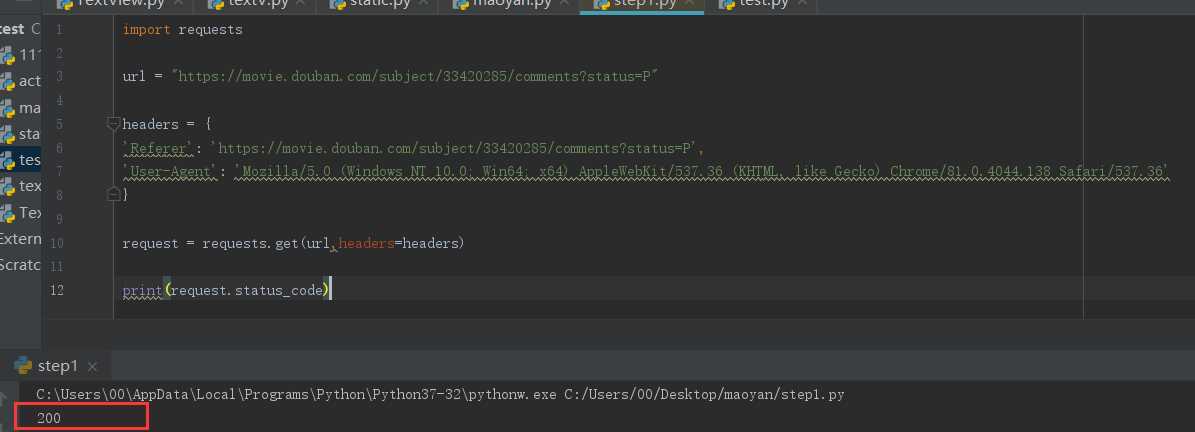
url = "https://movie.douban.com/subject/33420285/comments?status=P"
headers = {
‘Referer‘: ‘https://movie.douban.com/subject/33420285/comments?status=P‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36‘
}
request = requests.get(url,headers=headers)
print(request.status_code)
import requests
url = "https://movie.douban.com/subject/33420285/comments?status=P"
headers = {
‘Referer‘: ‘https://movie.douban.com/subject/33420285/comments?status=P‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36‘
}
request = requests.get(url,headers=headers)
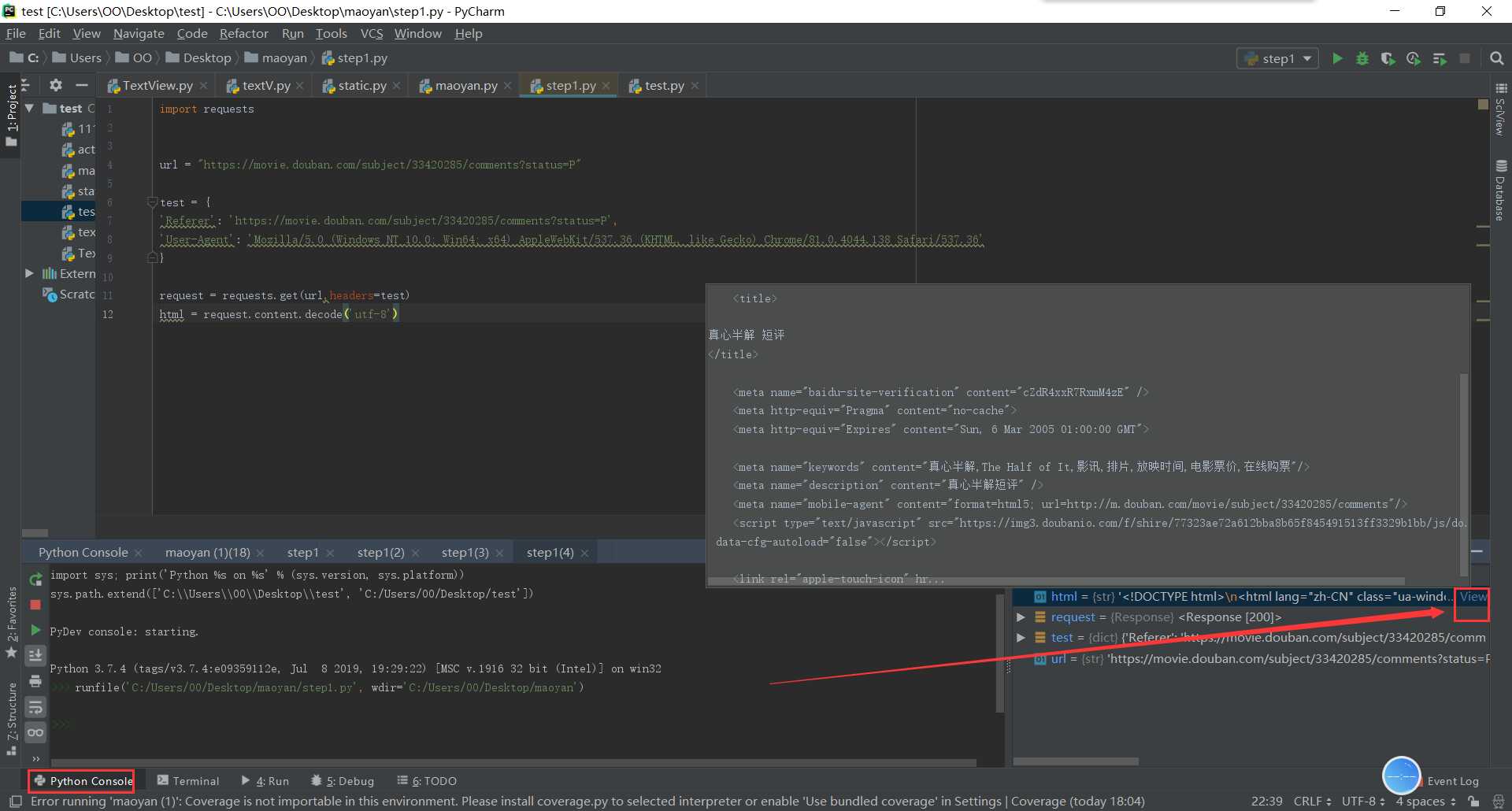
html = request.content.decode(‘utf-8‘)
html = request.content.decode(‘utf-8‘)表示将网页的html内容解码出来,右键查看源码可以看到编码格式
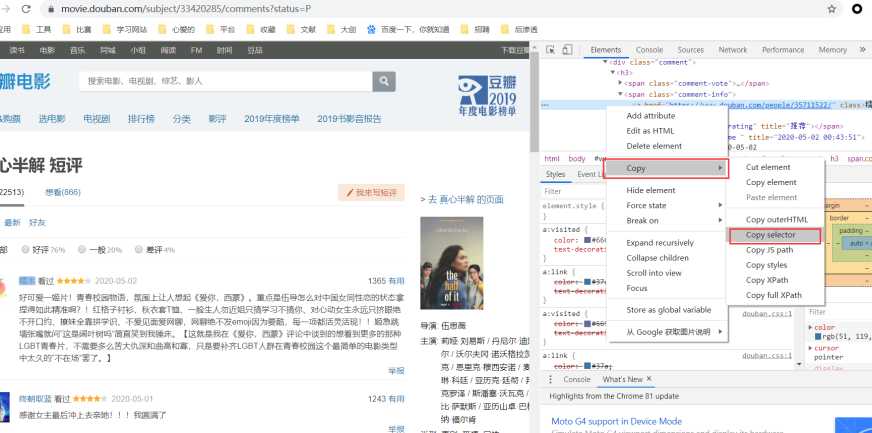
#comments > div:nth-child(1) > div.comment > h3 > span.comment-info > a 指明要爬取的内容处于html结构中的哪个位置
from bs4 import BeautifulSoup #好找到提取文本对象的工具
import requests
url = "https://movie.douban.com/subject/33420285/comments?status=P"
headers = {
‘Referer‘: ‘https://movie.douban.com/subject/33420285/comments?status=P‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36‘
}
request = requests.get(url,headers=headers)
html = request.content.decode(‘utf-8‘)
dom = BeautifulSoup(html , ‘lxml‘) #将html类型的内容转换为文档类型
reviewers =[i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > a‘)] #使用一个循环,循环dom.select列表中的每一个元素i,并用getText()提取出文本 评论者id
dates = [i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > span.comment-time‘)] #评论日期
shot_comments = [i.getText() for i in dom.select(‘#comments > div > div.comment > p > span‘)] #shift+alt+e 评论
votes = [i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-vote > span‘)] #投票数
#comments > div:nth-child(1) > div.comment > h3 > span.comment-info > a
#comments > div:nth-child(2) > div.comment > h3 > span.comment-info > a 可以看到不同位置上的id是不同的,所以这里将:nth-child()这一块删除掉就会显示所有评论者的id了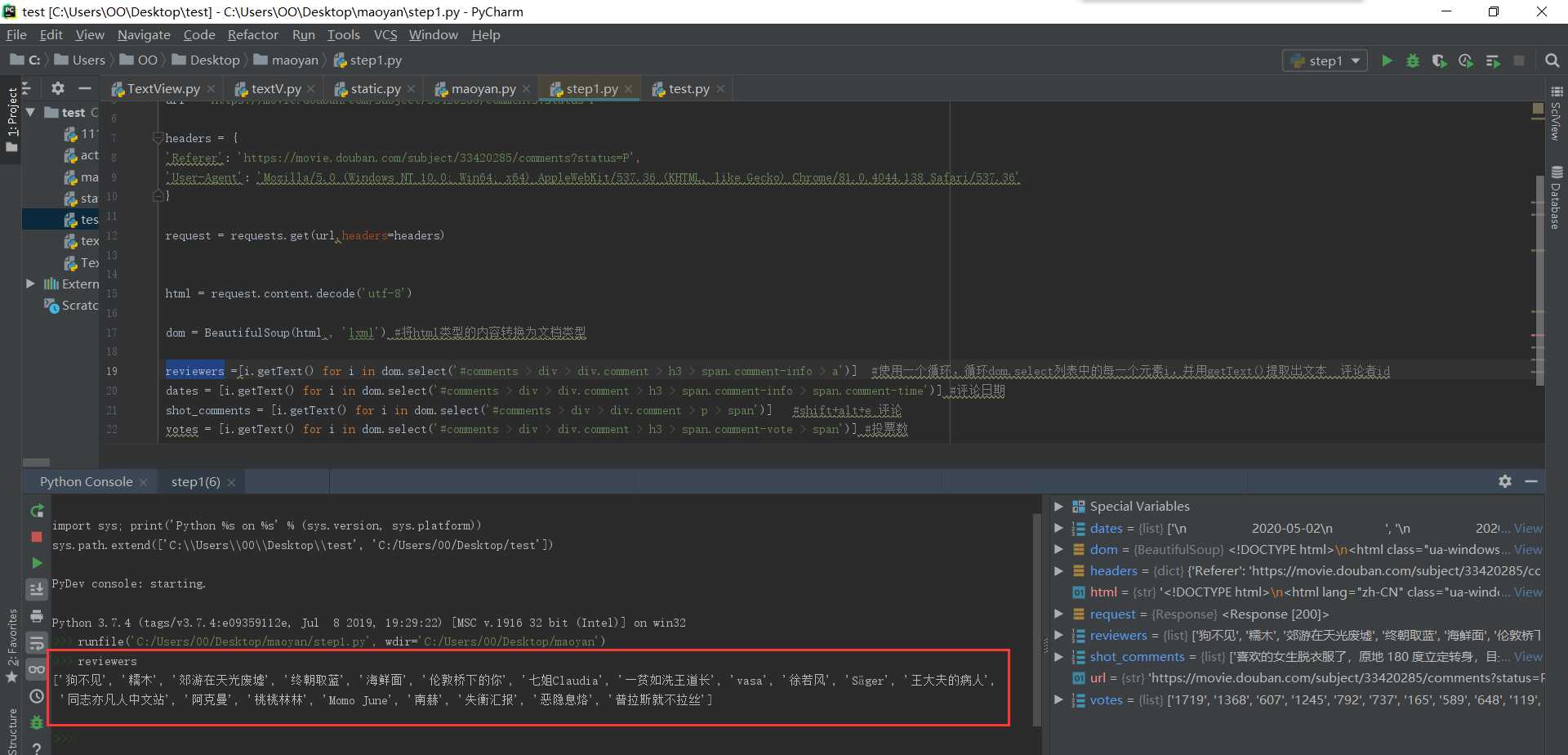
from bs4 import BeautifulSoup
import requests
url1 = "https://movie.douban.com/subject/33420285/comments?status=P"
headers = {
‘Referer‘: ‘https://movie.douban.com/subject/33420285/comments?status=P‘,
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36‘
}
for i in range(0,100,20):
url = f‘https://movie.douban.com/subject/33420285/comments?start={i}&limit=20&sort=new_score&status=P‘
request = requests.get(url,headers=headers)
html = request.content.decode(‘utf-8‘)
dom = BeautifulSoup(html , ‘lxml‘)
reviewers = reviewers +[i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > a‘)]
dates = dates+[i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > span.comment-time‘)]
shot_comments = shot_comments+[i.getText() for i in dom.select(‘#comments > div > div.comment > p > span‘)]
votes = votes+[i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-vote > span‘)]
reviewers = [i.getText() for i in dom.select(‘#comments > div > div.comment > h3 > span.comment-info > a‘)]
import pandas as pd
short = pd.DataFrame({
‘时间‘:dates,‘评论者‘:reviewers,‘留言‘:shot_comments,‘票数‘:votes
})
short.to_excel(‘./short.xlsx‘)
上一篇:C语言实验报告(六)
下一篇:常用的排序算法及其适用场景