pdf文件内容查看器 -- 采用wpf开发
2021-01-18 06:13
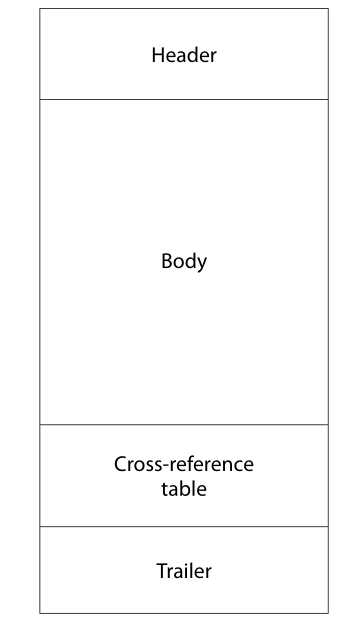
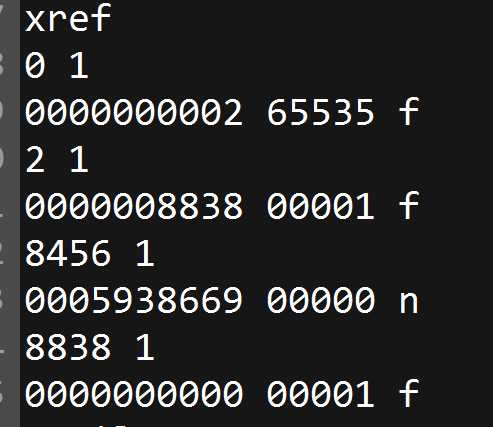
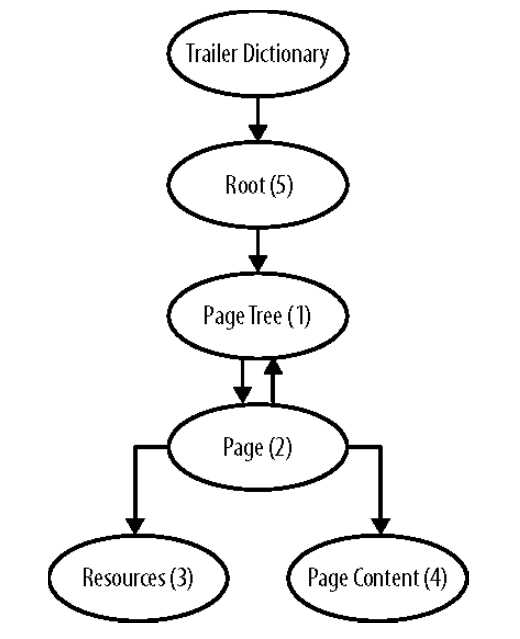
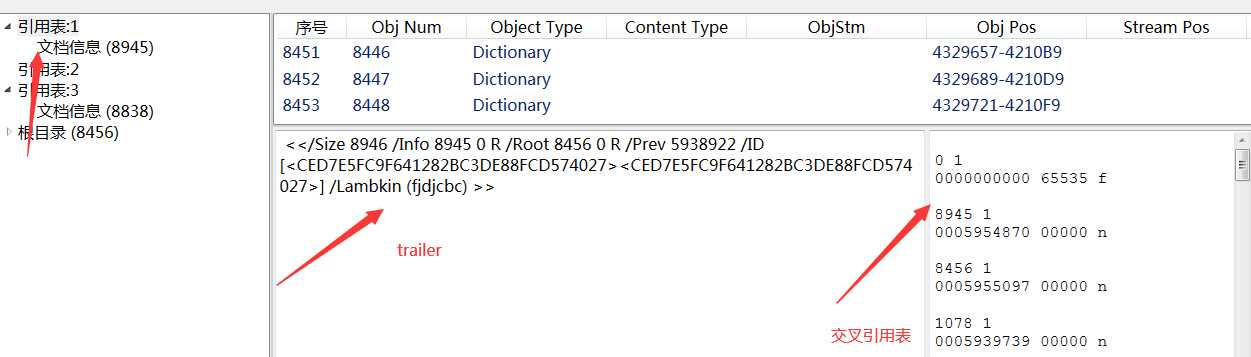
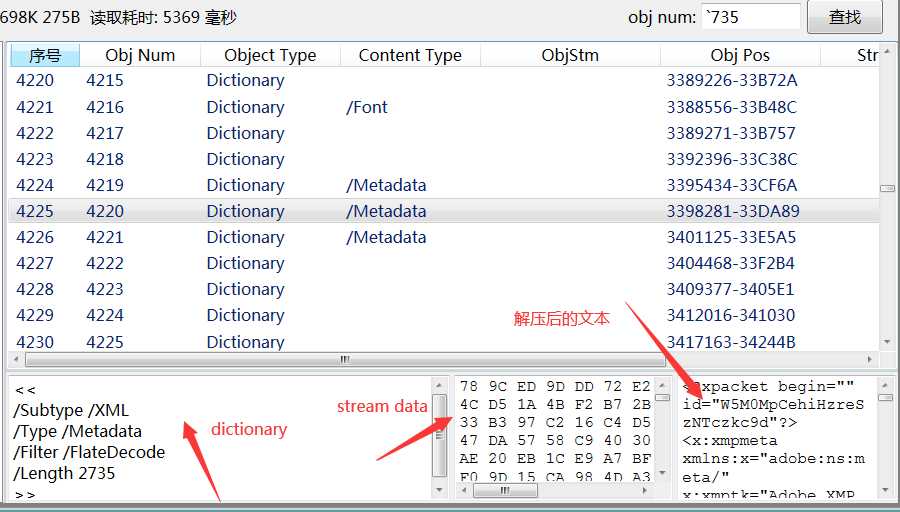
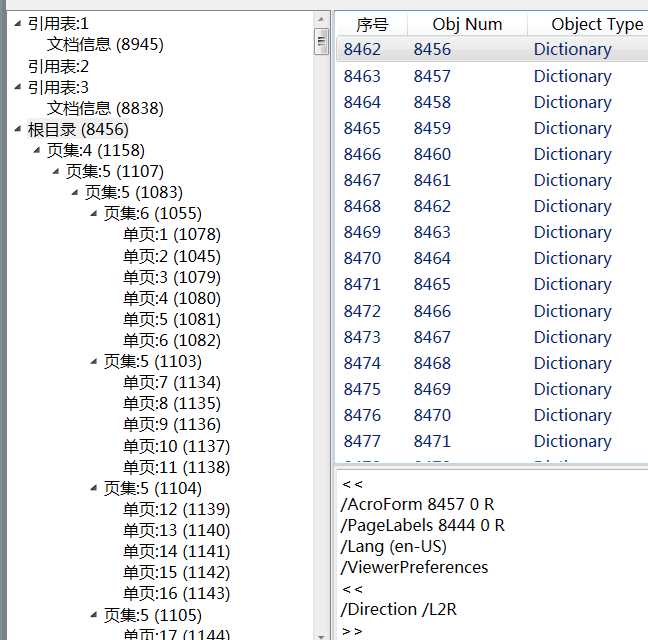
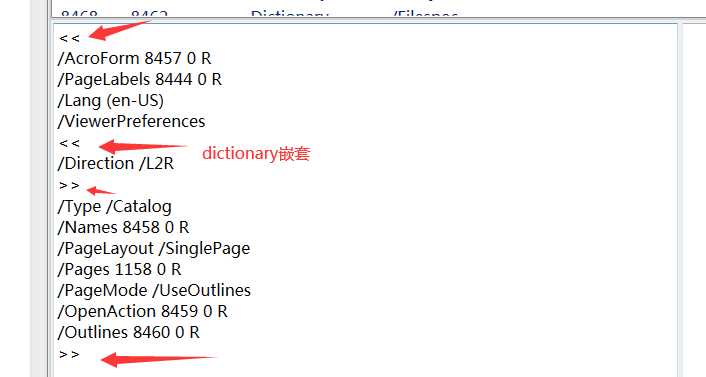
标签:集合 pdf tar logs ima 完成 image 无法 如何使用 前言 pdf是一种应用非常广的版式文档格式,已成为事实上的国际标准。关于pdf格式的文章汗牛充栋,本文也是关于pdf格式的文章,但是本文不是纸上谈兵;本人这几周一直研究pdf格式内容,不但对pfd格式的内容有所了解,同时也写了一款软件,可以方便查看pdf文件内容。使用该软件,同时结合pdf相关文章,可以很快掌握pdf格式内容。 软件截图: 软件下载地址 点我下载 pdf文件内容简要介绍 这里对pdf文件格式做个粗略介绍,只有了解了这些内容,才能知道如何使用该软件。 pdf文档总结构如下: 1)header:主要包含版本信息 2)tailer:pdf树结构的入口点。 3)交叉索引表;该表包含pdf每个obj在文件中的位置,根据该表,可以快速定位和加载obj的内容。对于大文件,不必一次加载所有的内容,只需加载当前页包含的obj即可。 4) body。 包含obj对应的内容。 pdf obj树状结构 要完成对pdf文件的分析和显示,首先需要构建pdf文件的obj的树状模型。这个树状模型的入口点就是trailer,trailer包含root元素(Catalog),其下包含Pages,Page。Page中包含内容和资源。 结合软件分析pdf文件格式 用该软件打开一个pdf文件,对照示例来分析。 1)pdf header: 2)trailer和交叉引用表, 3)body 由一系列obj组成。每个obj由唯一编号,可根据编号定位到内容。 4)文档树状结构 页集是页的集合,pdf规范建议用平衡树来组织页,便于快速查找。 编程心得。 1 不能严格按照pdf标准来分析pdf。 pdf文档应用非常广,生成pdf文件的软件非常多。不是所有的pdf文档都严格符合标准。所谓“林子大了,什么鸟都有“。所以开发软件要经过大量的pfd文档测试。 2 分析obj的内容 pdf索引表只给出了obj开始文件位置。obj一般包含dictionary和stream两部分。所以需要根据关键词来解析obj,这就需要有一定的技巧。dictionary开始和结束的关键字为“>",但是dictionary可能包含子dictionary。只靠关键字是无法确定dictionary的开始和结束位置的,需要一定的技巧。 3 读取obj的效率。 不必一次加载所有的obj,可以采取按需加载。 后记 读取pdf文件的内容,在内存中构建obj树形结构,是下一步分析和显示pdf的基础。本人通过阅读相关资料,加上编写代码,实现了对pdf文件内容的分析。理论和实践相结合,就能快速的掌握相关知识。本软件可以方便的窥探pdf内部结构,希望该软件为你了解和开发pdf有所帮助。 pdf文件内容查看器 -- 采用wpf开发 标签:集合 pdf tar logs ima 完成 image 无法 如何使用 原文地址:https://www.cnblogs.com/yuanchenhui/p/WpfPdfExplorer.html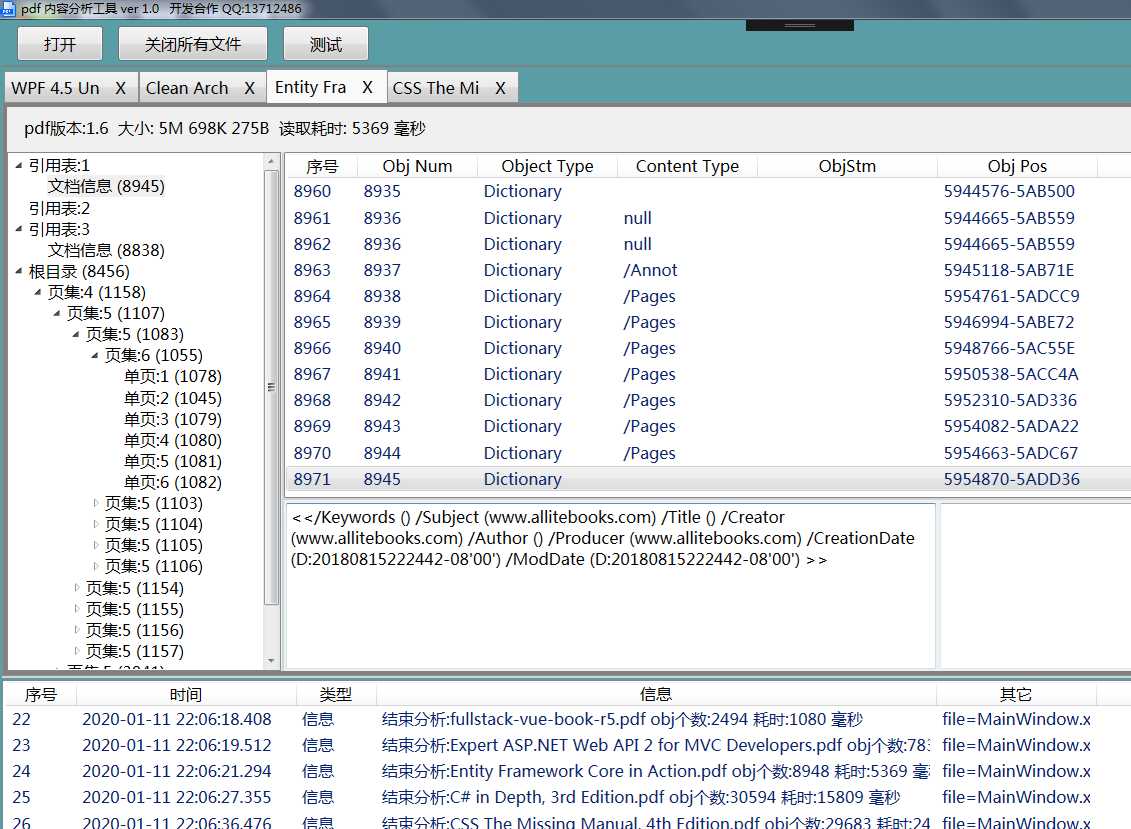



文章标题:pdf文件内容查看器 -- 采用wpf开发
文章链接:http://soscw.com/index.php/essay/43544.html