FCN与U-Net语义分割算法
2021-01-20 11:13
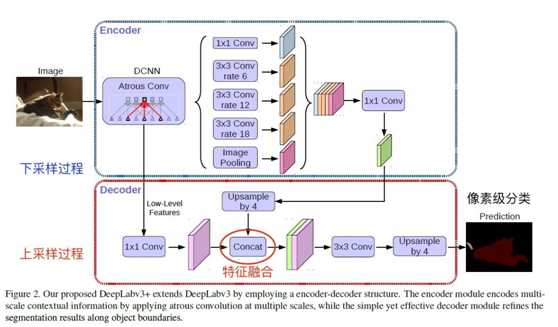
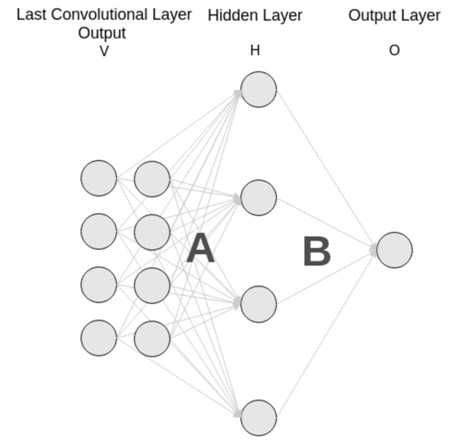
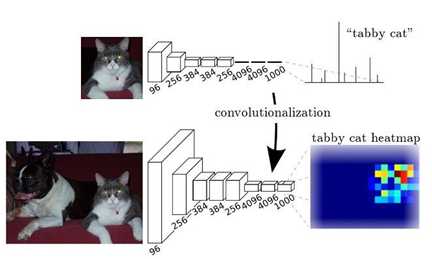
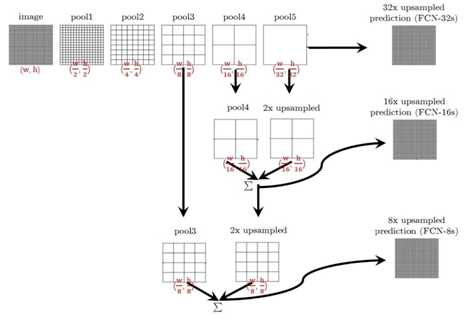
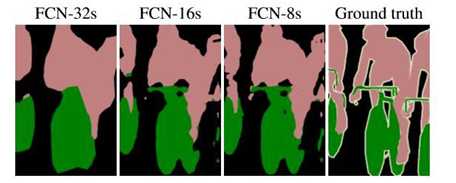
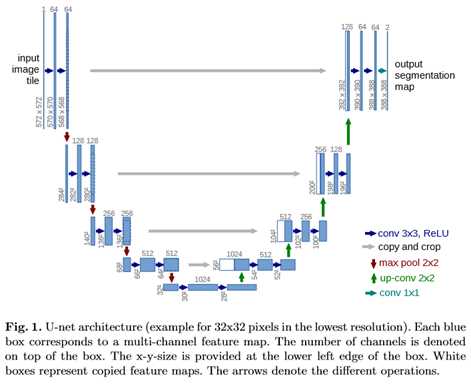
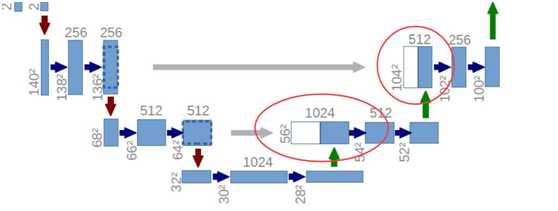
标签:ati 训练 ima 宽高 led medical 实现 ann 传递 FCN与U-Net语义分割算法 图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。 图1 自动驾驶中的图像语义分割 而截止目前,CNN已经在图像分类分方面取得了巨大的成就,涌现出如VGG和Resnet等网络结构,并在ImageNet中取得了好成绩。CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征: 1. 较浅的卷积层感知域较小,学习到一些局部区域的特征; 2. 较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。 这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。图像分类是图像级别的! 与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。图像语义分割是像素级别的!但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。 针对这个问题,Jonathan Long等人提出了Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。 一. FCN Fully Convolutional Networks for Semantic Segmentation 论文链接:https://arxiv.org/abs/1411.4038 摘要 卷积网络是一种强大的视觉模型,可以产生特征的层次结构。结果表明,经过训练的端到端、像素到像素的卷积网络在语义分割方面超过了目前的水平。的关键见解是建立“完全卷积”网络,它接受任意大小的输入,并通过有效的推理和学习产生相应大小的输出。定义并详细描述了全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并绘制了与先前模型的连接。将当代的分类网络(AlexNet、VGG网和GoogLeNet)转化为完全卷积的网络,并通过对分割任务的微调来传递它们所学习的表示。然后,定义了一个新的架构,它将来自深层、粗糙层的语义信息与来自浅层、精细层的外观信息结合起来,以产生准确和详细的分段。的全卷积网络实现了PASCAL VOC(2012年平均IU为62.2%,相对提高20%)NYUDv2和SIFT流的最新分割,而对于典型图像,推理需要三分之一秒。 FCN改变了什么? 对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。 图3 全连接层 而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题,如图4。 图4 2 FCN结构 整个FCN网络基本原理如图5(只是原理示意图): 1. image经过多个conv和+一个max pooling变为pool1 feature,宽高变为1/2 2. pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4 3. pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8 4. ...... 5. 直到pool5 feature,宽高变为1/32。 图5 FCN网络结构示意图 那么: 1. 对于FCN-32s,直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。 2. 对于FCN-16s,首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。 3. 对于FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。 作者在原文种给出3种网络结果对比,明显可以看出效果:FCN-32s 使用多层feature融合有利于提高分割准确性。 图6 二.U-Net U-Net: Convolutional Networks for Biomedical Image Segmentation 论文链接:https://arxiv.org/abs/1505.04597 人们普遍认为,成功的深层网络训练需要数千个带注释的训练样本。本文提出了一种网络和训练策略,该策略依赖于数据增强的强大使用,以更有效地使用可用的注释样本。该体系结构由捕获上下文的收缩路径和支持精确定位的对称扩展路径组成。这种网络可以从很少的图像中端到端地训练,并且在电子显微镜堆栈中神经元结构分割的ISBI挑战上优于先前的最佳方法(滑动窗口卷积网络)。使用同样的传输光学显微镜图像(相位对比度和DIC)训练网络,在2015年的ISBI细胞跟踪挑战赛中以较大的优势赢得了这些类别的比赛。而且,网络速度很快。在最近的GPU上,512x512图像的分割不到一秒钟。 图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。 U-Net是原作者参加ISBI Challenge提出的一种分割网络,能够适应很小的训练集(大约30张图)。U-Net与FCN都是很小的分割网络,既没有使用空洞卷积,也没有后接CRF,结构简单。 整个U-Net网络结构如图,类似于一个大大的U字母:首先进行Conv+Pooling下采样;然后Deconv反卷积进行上采样,crop之前的低层feature map,进行融合;然后再次上采样。重复这个过程,直到获得输出388x388x2的feature map,最后经过softmax获得output segment map。总体来说与FCN思路非常类似。 为何要提起U-Net?是因为U-Net采用了与FCN完全不同的特征融合方式:拼接! 语义分割网络在特征融合时也有2种办法: FCN式的逐点相加,对应caffe的EltwiseLayer层,对应tensorflow的tf.add() U-Net式的channel维度拼接融合,对应caffe的ConcatLayer层,对应tensorflow的tf.concat() 相比其他大型网络,FCN/U-Net还是蛮简单的,就不多废话了。 总结一下,CNN图像语义分割也就基本上是这个套路: 下采样+上采样:Convlution + Deconvlution/Resize 多尺度特征融合:特征逐点相加/特征channel维度拼接 获得像素级别的segement map:对每一个像素点进行判断类别 看,即使是更复杂的DeepLab v3+依然也是这个基本套路。 FCN与U-Net语义分割算法 标签:ati 训练 ima 宽高 led medical 实现 ann 传递 原文地址:https://www.cnblogs.com/wujianming-110117/p/12901960.html




下一篇:springboot 热部署