Web自动化测试:数据分离(类变量、yaml、excel)
2021-01-21 06:12
标签:格式 文件 安装 纠错 打开文件 简单 名称 获取 读取 一、类变量 1.1本类中调用类变量 例如:Demo类中,在类下申请一个变量name,如果这个类中的方法要引用name,需要self.name这样的格式调用。 demo_class.py class Demo(): 1.2调用其他类的类变量 other_class.py from demo_class import Demo class Demo2(): 二、yaml配置文件 2.1yaml文件的格式: account: 命令行安装:pip install pyyaml 代码导入库:import yaml 2.3读取yaml文件: 大致步骤是: 打开文件、载入文件、读取文件、关闭文件 需要注意的一点是:打开文件时,我设置了encoding格式,因为发现就算是加了引号的中文,部分字符仍然无法正确编码读取 import yaml # 打开文件 关于递归 def get_any_key_info(key_name="", yaml_data=None): 三、excel文件 3.1excel操作类的安装和引用: 引用库介绍: xlrd:读取excel xlwt:写入excel 安装: pip install xlrd pip install xlwt 引用: import xlrd import xlwt 3.2 读取excel的方法 文件的读取 xlrd.open_workbook(file_path) sheet_names() sheet_by_index(index) index:索引(从0开始) name:sheet表名 nrows # 行数 获取某行数据 cell(row, col).value def excel_table_byname(file_path, colnameindex=0, sheet_name=‘Sheet1‘): # 读取载入文件 # 获取sheet中行列数 # 获取行、列数据 # 获取单元格数据 def excel_table_byname(file_path, colnameindex=0, sheet_name=‘Sheet1‘): # 读取单个sheet表数据 sheet名称:[‘表1‘] Web自动化测试:数据分离(类变量、yaml、excel) 标签:格式 文件 安装 纠错 打开文件 简单 名称 获取 读取 原文地址:https://blog.51cto.com/14645850/2510353
一般习惯把元素定位地址作为类变量存储,因为这样对于调试纠错比较方便,书写调用也较简单。
name = "川石学院"def print_name(self):
print(self.name)
如果其他class类要引用,那需要先import这个类,然后再使用Demo.name这种形式调用。print(Demo.name)
这里引用了pyyaml这个库,用来读取.yaml格式的文件。
1,通过缩进和冒号来控制层级范围
2,如果有中文需要加引号
3,注释符号为:#
如下所示:
# 我是注释
user_1:
username:
"川石学院"
password:
meiyoumima
2.2yaml的安装与引用:
fr = open("D:/config.yaml", ‘r‘, encoding=‘gb18030‘, errors=‘ignore‘)
# 载入文件格式
data = yaml.load(fr)
# 读取文件层级
# 下面两种方法都可以获取到信息值,区别是通过get方法获取值时,如果key键不存在会返回None,通过索引[]来获取值时,key键不存在会报错。
# get_user = data["account"]["user_1"]["username"]
get_user = data.get("account").get("user_1").get("username")
print(get_user)
# 关闭文件**
fr.close()
对于yaml文件读取出来的数据是字典的格式,在读取yaml时,有时想要查找的数据藏得层级很深,要查找的话要写很多层级,将来如果层级变动又要做出调整,所以这里使用了递归写一个方法,来通过任意一个层级名称,来获取层级下的所有值。for循环字典这一层的所有key值
for i in list(yaml_data.keys()):
# 如果当前的key是我们要找的
if i == key_name:
return yaml_data[i]
**** # 如果当前的key不是我们找的key,并且是字典类型
elif type(yaml_data[i]) == dict:
# 使用递归方法,查找下一层的字典
recursion = get_any_key_info(key_name, yaml_data[i])
**** # 每层递归要返回一个值,否则函数默认返回None
return recursion
excel文件一般适合更加复杂的场景,如果只是简单的记录配置、数据,我认为还是类变量和yaml这种可以在python编辑器中读取编辑的类型更适合些。
file_path:excel文件路径
获取excel文件的sheet名:
根据sheet名/索引获取sheet表数据
sheet_by_name(name)
获取sheet表中行数、列数
ncols # 列数
根据行、列索引获取行、列数据(索引从0开始)
row_values(index)
获取某列数据
col_values(index)
根据坐标位置获取单元格数据(坐标是从0开始)
row:行的索引
col:列的索引
3.3关于读取sheet表,自己封装的方法。
基于上述的方法和功能,我在想,一般的读取excel表格,都是列名和数据对应的,所以写了如下方法,可以把每一行的数据作为一个字典,通过列名来对应,每行作为一个字典来存储在整体的列表中。
"""
根据名称获取Excel表格中的数据
参数
file:Excel文件路径
colnameindex:表头列名所在行的索引
sheet_index:Sheet1名称
返回:列表,每个列表元素为列名对应的字典
"""
data = xlrd.open_workbook(file_path)
table = data.sheet_by_name(sheet_name)
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 列名行
colnames = table.row_values(colnameindex)
dic_list = []
# 从第一行到最后一行循环
for rown in range(1, nrows):
row = table.row_values(rown)
if row:
app = {}
# 单行数据组合为字典
for i in range(ncols):
app[colnames[i]] = row[i]
dic_list.append(app)
return dic_list
3.4实例演示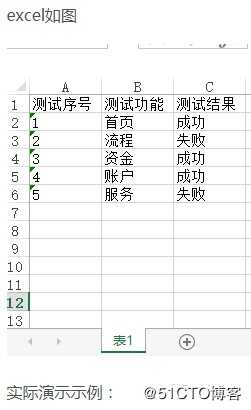
import xlrd
file = xlrd.open_workbook("F:/test.xlsx")
# 获取所有sheet名
print("sheet名称:%s" % file.sheet_names())
# 获取sheet
sheet1 = file.sheet_by_name("表1")
print(sheet1)
print("列数:%s" % sheet1.ncols)
print("行数:%s" % sheet1.nrows)
print("第1行数据:%s" % sheet1.row_values(0))
print("第1列数据:%s" % sheet1.col_values(0))
print("第2行、第2列数据:%s" % sheet1.cell(1, 1).value)
"""
根据名称获取Excel表格中的数据
参数
file:Excel文件路径
colnameindex:表头列名所在行的索引
sheet_index:Sheet1名称
返回:列表,每个列表元素为列名对应的字典
"""
data = xlrd.open_workbook(file_path)
table = data.sheet_by_name(sheet_name)
nrows = table.nrows # 行数
ncols = table.ncols # 列数
# 列名行
colnames = table.row_values(colnameindex)
dic_list = []
# 从第一行到最后一行循环
for rown in range(1, nrows):
row = table.row_values(rown)
if row:
app = {}
# 单行数据组合为字典
for i in range(ncols):
app[colnames[i]] = row[i]
dic_list.append(app)
return dic_list
print("读取excel数据....")
data_list = excel_table_byname(file_path="F:/test.xlsx",sheet_name="表1")
print(data_list)
for x in data_list:
print(x)
结果:
列数:3
行数:6
第1行数据:[‘测试序号‘, ‘测试功能‘, ‘测试结果‘]
第1列数据:[‘测试序号‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘]
第2行、第2列数据:首页
读取excel数据。。。
[{‘测试序号‘: ‘1‘, ‘测试结果‘: ‘成功‘, ‘测试功能‘: ‘首页‘}, {‘测试序号‘: ‘2‘, ‘测试结果‘: ‘失败‘, ‘测试功能‘: ‘流程‘}, {‘测试序号‘: ‘3‘, ‘测试结果‘: ‘成功‘, ‘测试功能‘: ‘资金‘}, {‘测试序号‘: ‘4‘, ‘测试结果‘: ‘成功‘, ‘测试功能‘: ‘账户‘}, {‘测试序号‘: ‘5‘, ‘测试结果‘: ‘失败‘, ‘测试功能‘: ‘服务‘}]
{‘测试序号‘: ‘1‘, ‘测试结果‘: ‘成功‘, ‘测试功能‘: ‘首页‘}
{‘测试序号‘: ‘2‘, ‘测试结果‘: ‘失败‘, ‘测试功能‘: ‘流程‘}
{‘测试序号‘: ‘3‘, ‘测试结果‘: ‘成功‘, ‘测试功能‘: ‘资金‘}
{‘测试序号‘: ‘4‘, ‘测试结果‘: ‘成功‘, ‘测试功能‘: ‘账户‘}
{‘测试序号‘: ‘5‘, ‘测试结果‘: ‘失败‘, ‘测试功能‘: ‘服务‘}
上一篇:jQuery 项目常用函数
下一篇:Egret之异步JSZIP操作
文章标题:Web自动化测试:数据分离(类变量、yaml、excel)
文章链接:http://soscw.com/index.php/essay/44856.html