JS leetcode 存在重复元素 II 题解分析,记一次震惊的负向优化
2021-01-23 02:13
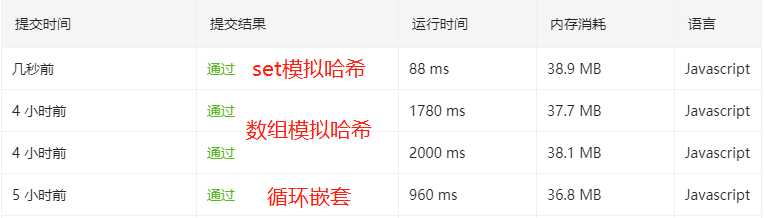
标签:for循环 绝对值 不同的 整理 ret png 思路 tco 接下来 整理下今天做的算法题,题目难度不高,但在优化角度也是费了一些功夫。题目来自219. 存在重复元素 II,问题描述如下: 给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的 绝对值 至多为 k。 示例 1: 示例 2: 示例 3: 题目意思其实很简单,看一个数组中是否有两个元素相等,且后者索引减去前者的差集,要小于等于数值k。注意不是等于k,我第一次提交就是看错了直接给挂了,接下来我们来说说怎么做。 我首先想到的自然是for循环遍历嵌套,用两个索引分别表示数组中一前一后的元素,如果两个元素相等,且后者索引减去前者索引的值 我在上篇文章中提到,如果能将时间复杂度从 在阅读了官方推荐的哈希表做法后,我实现了如下代码: 实现不难理解,我们始终维护一个大小为k的哈希表,并依次将元素加入表内,由于一开始为空,自然是加入第一个。从第二个开始判断有没有,如果有自然返回true。反之没有继续加入表内。但需要注意的是,我们的表的大小是k,一旦超过我们就得删除掉最旧的数据。 思路清晰,然后我提交了代码,一看执行时间,我人都傻了,出于怀疑我又点了一次提交(2000ms与1780ms)。 从表面上看,暴力解法用了两次循环嵌套,而哈希表做法只用了一次。其实从内部实现来看,循环嵌套做的事情要简单的多。 我们知道数组是呈线性排列的一种数据结构,当我们通过索引直接访问某条数据时,它的时间复杂度为 除此之外,我们在下方代码还做了 所以整体上来看,双循环嵌套执行次数看着虽然多,但站在时间复杂度角度来说,每一次操作单元耗时微乎其微,都是根据索引直接找到对应元素对比。而后一种实现每次遍历做的事情就非常耗时了。 奇妙的是,同样的思路,我们将数组换成set结构,速度就快了很多,只用了88ms,这里引用灵魂画手的实现: 可以看到只是单纯换了数据结构,执行用时质的提升,这里我不禁对于数据结构差异产生了兴趣,在知乎javascript 里的Set.has和Array.includes谁的效率更高?提问中,有用户做过测试,在大量数据下,set要远高于数组。但本质原因我一时无法考证了,只能在心里埋下一枚问题种子,待日后算法与数据结构的不算学习,希望能给自己一个答案。 那么到这里,本文正式结束。 JS leetcode 存在重复元素 II 题解分析,记一次震惊的负向优化 标签:for循环 绝对值 不同的 整理 ret png 思路 tco 接下来 原文地址:https://www.cnblogs.com/echolun/p/13280245.html
壹 ? 引
输入: nums = [1,2,3,1], k = 3
输出: true
输入: nums = [1,0,1,1], k = 1
输出: true
输入: nums = [1,2,3,1,2,3], k = 2
输出: false
贰 ? 暴力解法
,则返回true即可:/**
* @param {number[]} nums
* @param {number} k
* @return {boolean}
*/
var containsNearbyDuplicate = function (nums, k) {
let ans = false
for (let i = 0; i 叁 ? 震惊的负向优化
O(n2)降到O(n),那将是大大的优化,尽管上述代码遍历也并未达到n2,但我们还是可以试试。/**
* @param {number[]} nums
* @param {number} k
* @return {boolean}
*/
var containsNearbyDuplicate = function (nums, k) {
// 我们始终维护一个大小为k的哈希表
let hash = [];
for (let i = 0; i k) {
hash.shift();
};
};
return false;
};
O(1),而做查找操作就不同了,由于没有提供标识,我们只能通过线性查找一个接一个进行对比,看看当前是不是我们想要的。看看hash.includes(nums[i])这行代码,你是否意识到了什么呢?shift操作,也就是数组删除,由于数组是连续的,出现空缺就得填补,像这样: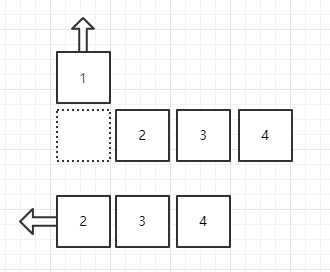
肆 ? 使用ES6 set结构
/**
* @param {number[]} nums
* @param {number} k
* @return {boolean}
*/
var containsNearbyDuplicate = function(nums, k) {
// 创建哈希表
const set = new Set();
for(let i = 0; i k) {
// 删除最旧数据
set.delete(nums[i - k]);
};
};
return false;
};
文章标题:JS leetcode 存在重复元素 II 题解分析,记一次震惊的负向优化
文章链接:http://soscw.com/index.php/essay/45695.html