解密C语言编译背后的过程
2021-01-24 22:16
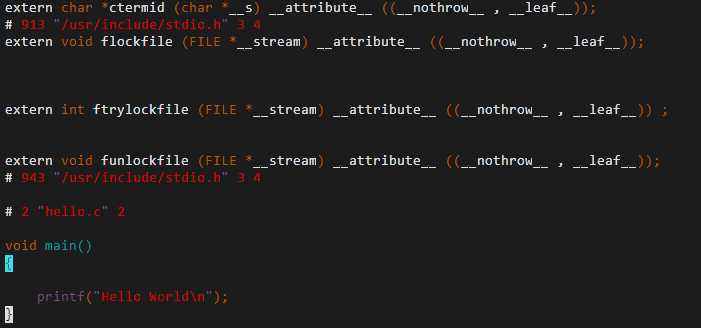
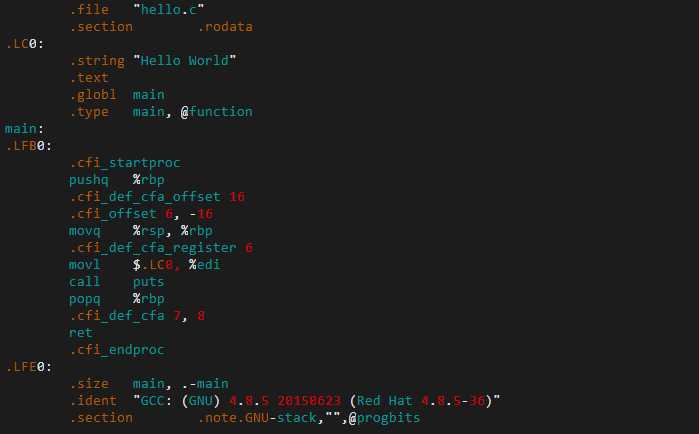
标签:绑定 技术 dash pil 注释 宏定义 通过 list 编译原理 我们大部分程序员可能都是从C语言学起的,写过几万行、几十万行、甚至上百万行的代码,但是大家是否都清楚C语言编译的完整过程呢,如果不清楚的话,我今天就带着大家一起来做个解密吧。 C语言相对于汇编语言是一种高级语言,要想在系统上运行,需要通过编译器把它转换成机器能够读懂的可执行的代码。 以Linux系统上的gcc为例,通常我们编译一个源文件都是用下面的命令: 编译成功后,目录里会生成hello这个程序,直接运行它可以看到结果。 $./hello Hello World! 但hello这个程序是怎么生成的呢,其实中间还是有好几步的。用下面这个命令重新编译一下,你可以看到所有的中间文件。 $gcc -save-temps hello.c –o hello $ls hello hello.c hello.i hello.o hello.s C编译器的编译过程主要分成四步: (1) 预处理 (2) 编译 (3) 汇编 (4) 连接 1) 预处理 Pre-prosssing 预处理生成了hello.i 的中间文件,主要完成了下面几步: 去掉所有的注释 展开所有的宏定义(也就是做字符替换) 插入#include文件的内容 处理所有的条件编译 hello.i 文件内容如下(文件较大,只展示了最下面的一块): 可以发现源代码中所有的注释被删除了,并且插入了stdio.h头文件的内容。 2)编译 Compiling 编译将 hello.i 文件编译生成一个中间文件 hello.s,打开可以看到里边都是汇编语言,所以编译的作用就是把源代码转换成汇编语言。 3)汇编 Assembly 汇编器将 hello.s 汇编成 hello.o 文件。hello.o是二进制文件,里边都是机器可以执行的代码。 4)连接 Linking 连接顾名思义起到了一个连接作用,虽然 hello.o 已经是二进制文件了,但是里边用到的比如 printf 函数需要调用别的库。连接器将我们的二进制文件和其他库做了一个绑定。可以看到连接后生成的 hello 文件要比 hello.o 大的多。 到这里 C的完整编译流程就结束了,本文的示例用的是Linux操作系统,编译器用的是 gcc,但在其他操作系统,比如 Unix、Windows,或者用其他编译器,原理都是一样的,感兴趣的同学可以去学习一下编译原理,会对编译有更深入的理解。 解密C语言编译背后的过程 标签:绑定 技术 dash pil 注释 宏定义 通过 list 编译原理 原文地址:https://www.cnblogs.com/jfzhu/p/12863076.html $gcc hello.c –o hello



上一篇:java web基础
下一篇:webdriver元素定位