Kafka消费者——API开发
2021-01-25 21:16
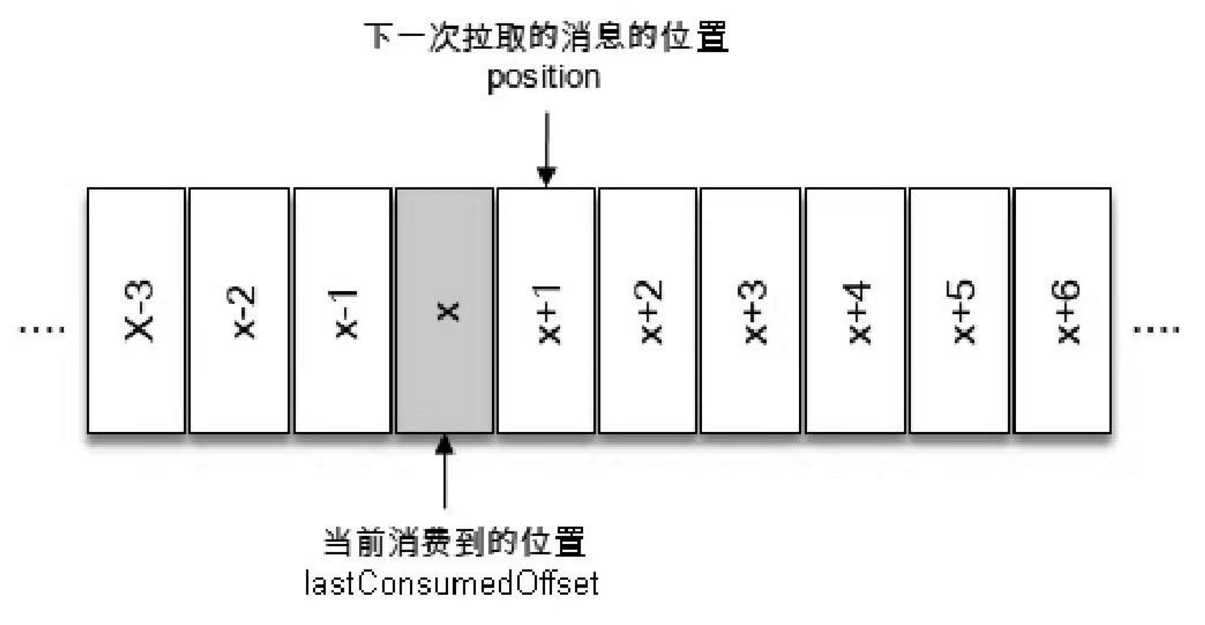
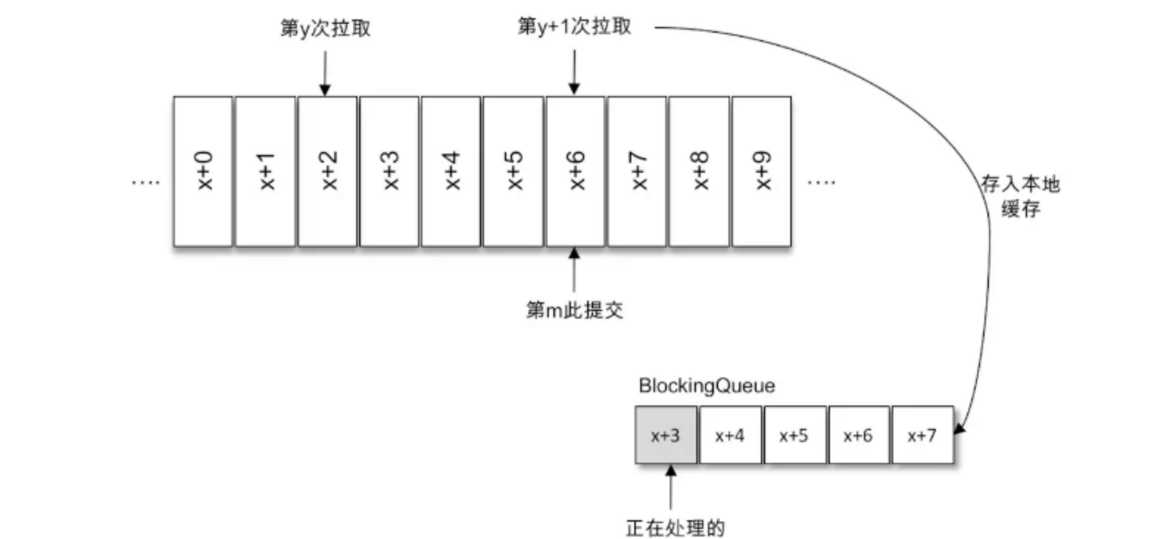
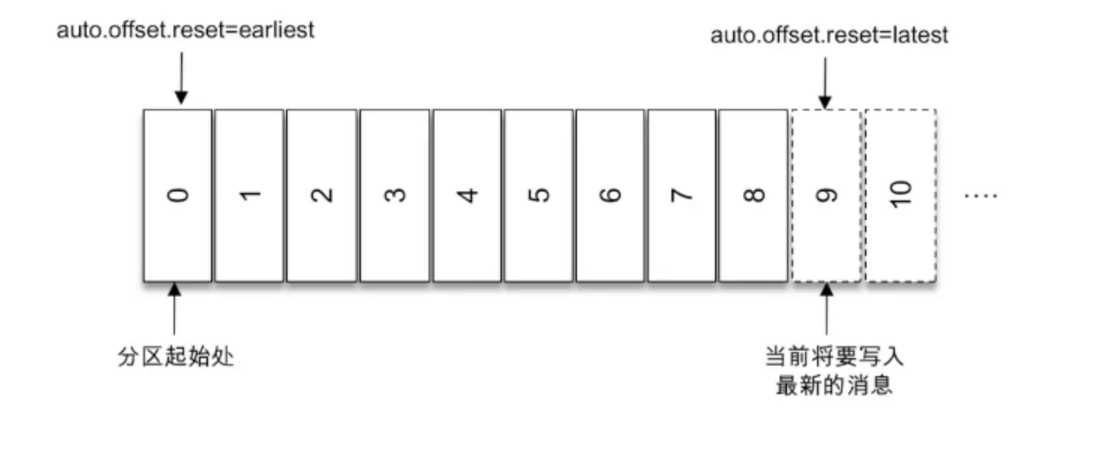
标签:轮询 副本 can pre res tor classes count() 异常 目录 消费步骤: 1、配置消费者客户端参数并创建相应的消费者实例。 2、订阅主题。 3、拉取消息并消费 4、提交消费位移 5、关闭消费者实例 通过使用subscribe()方法订阅主题,既可以以集合的形式订阅多个主题,也可以以正则表达式的形式订阅特定模式的主题。 对于消费者使用集合的方式来订阅主题而言,订阅了什么主题就消费什么主题中的消息。 但是,对于消费者采用正则表达式的方式订阅,在之后的过程中,如果创建了新的主题,并且主题名月正则表达式相匹配,那么这个消费者就可以消费到新添加的主题中的消息。如果应用程序需要消费多个主题,并且可以处理不同的类型,采取正则表达式的方式就会方便很多。 在subscriber的重载方法中,有一个参数类型ConsumerRebalanceListener 这个是用来设置再均衡监听器的。 消费者可以通过assign()方法来订阅分区 TopicPartition 类 只有两个属性:topic和partition,可以通过这两个属性进行分区映射。 如果清楚主题中的分区数,可以通过 获取 PartitionInfo ,PartitionInfo 类型为主题的分区元数据信息,结构如下 unsubscriber()方法用来取消订阅,既可以取消对于主题的订阅,也可以取消对于分区的订阅。 集合订阅方式 subscriber(Collection)、正则表达式subscriber(Pattern)和指定分区的订阅assign(Collertion)分别代表了三种不同的订阅状态:AUTO_TOPICS、AUTO_PATTERN、USER_ASSUGNED(如果没有订阅,订阅状态为NONE)。这三种状态是互斥的,在一个消费者中只能使用其中一种,否则会报错。 通过subscribe()方法订阅主题具有消费者自动再均衡的功能那个,在多个消费者的情况下可以根据分区分配策略自动分配各个消费者与分区的关系;当消费者组内的消费者增加或减少时,分区分配关系自动调整,以实现消费负载均衡和故障自动转移。 通过assign()方法订阅分区,不具备消费者自动均衡的功能。 Kafka中的消费者是基于拉模式的,也就是消费者主动向服务端发起请求来拉取消息,区别与其他类型的消息队列的推模式,也就是服务端主动将消息推送给消费者。 kafka消息消费是一个不断轮询的过程,消费者重复的调用poll()方法,返回的是所订阅主题(分区)上的一组消息。如果分区中没有可供消费的消息,那额拉取结果为空。poll()方法还有一个参数:超时时间参数timeout,用来控制poll()方法的阻塞时间,在消费者的缓冲区里没有可用数据时会发生阻塞。timeout的设置取决于应用程序对响应速度的要求,比如需要在多长时间内将控制权移交给执行轮询的应用线程。如果将timeout设置为0.poll方法会立即返回,而不管是否已经拉取了消息。如果应用线程唯一的工作就是从kafka中拉取并消费消息,则可以将这个参数设置为最大值Long.MAX_VALUE。 拉取到的消息ConsumerRecord封装到ConsumerRecords集合中 poll()方法返回值类型是ConsuerRecords,用来表示一次拉取操作所获得的的消息集合,包含多个ConsumerRecord,它提供了一个iterator()方法来循环遍历消息内部的消息。使用该方法来获取消息集中的每一个ConsumerRecord。 ConsumerRecords类提供了一个records(TopicPartition)方法获取消息集中指定分区的消息。 用过此方法,可以获取消息集中指定分区的消息。 count()方法可以用来计算出消息集中消息的个数。 isEmpty()方法判断消息集是否为空,返回值boolean empty() 用来获取一个空的消息集。 在Kafka中的分区中,每条消息都有唯一的offect,用来表示消息在分区中对用的位置。 在消费中也有一个offect的概念,用来表示消费到分区中某条消息的位置。在每次调用poll()方法的时候,他返回的是还没有被消费过的消息集,要做到这一点,就需要记录上一次消费时的消费位移。消费位移需要持久化保存,因为当有新的消费者接替上一个消费者进行消费的时候,能够正确的根据上一个消费者消费的位置进行继续消费。新版本的kafka试讲消费位移存储在kafka内部的主题_consumer_offects中,消费者在消费完消息之后需要执行消费位移的提交。 X表示某一次拉取操作中分区消息的最大偏移量,也就是此次操作消费到的位移,但是!本次消费结束后,将要提交位移的时候,提交的不是X,而是x+1,也就是下一条需要拉取的消息的位置。 KafkaConsumer类提供了position(TopicPartition)和conmmitted(TopicPartition)两个方法来分别获取partition(下次消费位移)和committed offect(本次提交位移)的值。 对于位移提交的具体时机很有讲究,可能会造成重复消费和消费都是的现象。 当前一次poll拉取的消息集为[x+2,x+7],当前在拉取到消息之后,就立即提交位移,也就是位移提交是x+8,当消息处理到x+5的后,出现异常,故障恢复后,重新拉取,将会从x+8进行拉取,从而造成消息丢失。 当位移提交在消息处理之后,当x+5时发生异常,故障恢复后,又重新从x+2进行拉取消息,造成了消息重复。 在kafka中,默认的消息位移提交方式为自动提交,由消费者客户端参数enable.auto.commit 配置,默认值为true。这个默认的自动提交不是每消费一条消息就提交一次,而是定期提交,这个定期的周期时间由客户端参数auto.commit.interval.ms 配置,默认值为5秒,此参数生效的前提是 enable.auto.commit 参数为 true。在默认的方式下,消费者每隔5秒会将拉取到的每个分区中最大的消息位移进行提交。自动位移提交的动作是在poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。 默认提交虽然非常简便,但也会出现重复消费和消息丢失的问题。 当刚提交一次消费位移,然后拉取一批消息进行消费,在在下一次自动提交之前,消费者出现异常,消费者恢复的时候又从上次一的分区位移进行消费,从而造成了消费重复的现象。可以通过减小自动提交的时间间隔来减小可能重复的消息大小,但不能完全避免重复消费,而且是位移提交变得频繁。 当拉取线程A不断的拉取消息到本地缓存,比如BlockingQueue,B线程从缓存中读取消息并进行相应的逻辑处理。假设进行到了第y+1次拉取,以及第m次位移提交的时候,也就是x+6位移已经确认提交,此时B线程却还在消费x+3的消息。此时B线程发生了异常,待回复后会从m位移,也就是x+6的位置开始拉取消息,那么 x+3 至 x+6 之间的消息就没有得到相应的处理,这样便发生消息丢失的现象。 自动位移提交的方式在正常情况下不会发生消息丢失或重复消费的现象,但是在编程的世界里异常无可避免,与此同时,自动位移提交也无法做到精确的位移管理。 Kafka 中还提供了手动位移提交的方式,这样可以使得开发人员对消费位移的管理控制更加灵活。很多时候并不是说拉取到消息就算消费完成,而是需要将消息写入数据库、写入本地缓存,或者是更加复杂的业务处理。在这些场景下,所有的业务处理完成才能认为消息被成功消费,手动的提交方式可以让开发人员根据程序的逻辑在合适的地方进行位移提交。开启手动提交功能的前提是消费者客户端参数 enable.auto.commit 配置为 false 手动提交可以细分为同步提交和异步提交,对应于 KafkaConsumer 中的 commitSync() 和 commitAsync() 两种类型的方法。 批量处理+批量提交 将拉取到的消息批量存入缓存buffer,到积累到足够多的时候,也就是示例中大于等于200个的时候,再做相应的批量处理,之后再做批量提交。 这两种实例都存在消费重复的问题,在同步位移提交前,程序出现了崩溃,那么待恢复之后又只能从上一次位移提交的地方拉取消息,就会发生消费重复。 同步提交会阻塞消费者线程直至位移提交完成。 ,如果想寻求更细粒度的、更精准的提交,那么就需要使用 commitSync() 的另一个含参方法 该方法提供了一个 offsets 参数,用来提交指定分区的位移。无参的 commitSync() 方法只能提交当前批次对应的position值。如果需要提交一个中间值,比如业务每消费一条消息就提交一次位移,那么就可以使用这种方式 commitSync() 方法本身是同步执行的,会耗费一定的性能,而示例中的这种提交方式会将性能拉到一个相当低的点。更多时候是按照分区的粒度划分提交位移的界限 与 commitSync() 方法相反,异步提交的方式(commitAsync())在执行的时候消费者线程不会被阻塞,可能在提交消费位移的结果还未返回之前就开始了新一次的拉取操作。异步提交可以使消费者的性能得到一定的增强。 第二个方法和第三个方法中的callback参数,它提供了一个异步提交的回调方法,当位移提交完成后会回调 OffsetCommitCallback 中的 onComplete() 方法。 如果位移提交失败,比如,第n次消费提交位移x+1,提交失败,进行重试,然而由于异步提交,也就是x+2已经提交,此时x+1重试提交,kafka的消费位移重新变为x+1,就会造成消费重复。 为此我们可以设置一个递增的序号来维护异步提交的顺序,每次位移提交之后就增加序号相对应的值。在遇到位移提交失败需要重试的时候,可以检查所提交的位移和序号的值的大小,如果前者小于后者,则说明有更大的位移已经提交了,不需要再进行本次重试;如果两者相同,则说明可以进行重试提交。除非程序编码错误,否则不会出现前者大于后者的情况。 如果位移提交失败的情况经常发生,那么说明系统肯定出现了故障,在一般情况下,位移提交失败的情况很少发生,不重试也没有关系,后面的提交也会有成功的。重试会增加代码逻辑的复杂度,不重试会增加重复消费的概率。如果消费者异常退出,那么这个重复消费的问题就很难避免,因为这种情况下无法及时提交消费位移;如果消费者正常退出或发生再均衡的情况,那么可以在退出或再均衡执行之前使用同步提交的方式做最后的把关。 KafkaConsumer 提供了对消费速度进行控制的方法,在有些应用场景下我们可能需要暂停某些分区的消费而先消费其他分区,当达到一定条件时再恢复这些分区的消费。KafkaConsumer 中使用 pause() 和 resume() 方法来分别实现暂停某些分区在拉取操作时返回数据给客户端和恢复某些分区向客户端返回数据的操作。 KafkaConsumer 还提供了一个无参的 paused() 方法来返回被暂停的分区集合 KafkaConsumer 提供了 close() 方法来实现关闭,close() 方法有三种重载方法 第二种方法是通过 timeout 参数来设定关闭方法的最长执行时间,有些内部的关闭逻辑会耗费一定的时间,比如设置了自动提交消费位移,这里还会做一次位移提交的动作;而第一种方法没有 timeout 参数,这并不意味着会无限制地等待,它内部设定了最长等待时间(30秒);第三种方法已被标记为 @Deprecated,可以不考虑。 在 Kafka 中每当消费者查找不到所记录的消费位移时,就会根据消费者客户端参数 auto.offset.reset 的配置来决定从何处开始进行消费,这个参数的默认值为“latest”,表示从分区末尾开始消费消息。 按照默认的配置,消费者会从9开始进行消费(9是下一条要写入消息的位置),更加确切地说是从9开始拉取消息。如果将 auto.offset.reset 参数配置为“earliest”,那么消费者会从起始处,也就是0开始消费。 除了查找不到消费位移,位移越界也会触发 auto.offset.reset 参数的执行 auto.offset.reset 参数还有一个可配置的值—“none”,配置为此值就意味着出现查到不到消费位移的时候,既不从最新的消息位置处开始消费,也不从最早的消息位置处开始消费,此时会报出 NoOffsetForPartitionException 异常。 如果能够找到消费位移,那么配置为“none”不会出现任何异常。如果配置的不是“latest”、“earliest”和“none”,则会报出 ConfigException 异常。 poll() 方法中的逻辑对于普通的开发人员而言是一个黑盒,无法精确地掌控其消费的起始位置。提供的 auto.offset.reset 参数也只能在找不到消费位移或位移越界的情况下粗粒度地从开头或末尾开始消费。我们需要一种更细粒度的掌控,可以让我们从特定的位移处开始拉取消息, 参数 partition 表示分区,而 offset 参数用来指定从分区的哪个位置开始消费。seek() 方法只能重置消费者分配到的分区的消费位置,而分区的分配是在 poll() 方法的调用过程中实现的。也就是说,在执行 seek() 方法之前需要先执行一次 poll() 方法,等到分配到分区之后才可以重置消费位置。 assignment() 方法是用来获取消费者所分配到的分区信息 如果将oll() 方法的参数设置为0,在此之后,会发现 seek() 方法并未有任何作用。因为当 poll() 方法中的参数为0时,此方法立刻返回,那么 poll() 方法内部进行分区分配的逻辑就会来不及实施。也就是说,消费者此时并未分配到任何分区,如此第②行中的 assignment 便是一个空列表,第③行代码也不会执行。timeout 参数设置为多少合适呢?太短会使分配分区的动作失败,太长又有可能造成一些不必要的等待。我们可以通过 KafkaConsumer 的 assignment() 方法来判定是否分配到了相应的分区 如果对未分配到的分区执行 seek() 方法,那么会报出 IllegalStateException 的异常。类似在调用 subscribe() 方法之后直接调用 seek() 方法. 如果消费组内的消费者在启动的时候能够找到消费位移,除非发生位移越界,否则 auto.offset.reset 参数并不会奏效,此时如果想指定从开头或末尾开始消费,就需要 seek() 方法 endOffsets() 方法用来获取指定分区的末尾的消息位置,是将要写入最新消息的位置。 其中 partitions 参数表示分区集合,而 timeout 参数用来设置等待获取的超时时间。如果没有指定 timeout 参数的值,那么 endOffsets() 方法的等待时间由客户端参数 request.timeout.ms 来设置,默认值为30000。与 endOffsets 对应的是 beginningOffsets() 方法,一个分区的起始位置起初是0,但并不代表每时每刻都为0,因为日志清理的动作会清理旧的数据,所以分区的起始位置会自然而然地增加。 KafkaConsumer 中直接提供了 seekToBeginning() 方法和 seekToEnd() 方法来实现这两个功能 有时候我们并不知道特定的消费位置,却知道一个相关的时间点,比如我们想要消费昨天8点之后的消息,这个需求更符合正常的思维逻辑。此时我们无法直接使用 seek() 方法来追溯到相应的位置。KafkaConsumer 同样考虑到了这种情况,它提供了一个 offsetsForTimes() 方法,通过 timestamp 来查询与此对应的分区位置。 参数 timestampsToSearch 是一个 Map 类型,key 为待查询的分区,而 value 为待查询的时间戳,该方法会返回时间戳大于等于待查询时间的第一条消息对应的位置和时间戳,对应于 OffsetAndTimestamp 中的 offset 和 timestamp 字段。 首先通过 offsetForTimes() 方法获取一天之前的消息位置,然后使用 seek() 方法追溯到相应位置开始消费 位移越界也会触发 auto.offset.reset 参数的执行,位移越界是指知道消费位置却无法在实际的分区中查找到 Kafka 中的消费位移是存储在一个内部主题中的,seek() 方法可以突破这一限制:消费位移可以保存在任意的存储介质中,例如数据库、文件系统等。以数据库为例,我们将消费位移保存在其中的一个表中,在下次消费的时候可以读取存储在数据表中的消费位移并通过 seek() 方法指向这个具体的位置 seek() 方法为我们提供了从特定位置读取消息的能力,我们可以通过这个方法来向前跳过若干消息,也可以通过这个方法来向后回溯若干消息,这样为消息的消费提供了很大的灵活性。seek() 方法也为我们提供了将消费位移保存在外部存储介质中的能力,还可以配合再均衡监听器来提供更加精准的消费能力。 再均衡是指分区的所属权从一个消费者转移到另一消费者的行为,它为消费组具备高可用性和伸缩性提供保障,使我们可以既方便又安全地删除消费组内的消费者或往消费组内添加消费者。不过在再均衡发生期间,消费组内的消费者是无法读取消息的。也就是说,在再均衡发生期间的这一小段时间内,消费组会变得不可用。 当一个分区被重新分配给另一个消费者时,消费者当前的状态也会丢失。比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作,之后这个分区又被分配给了消费组内的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就是发生了重复消费。一般情况下,应尽量避免不必要的再均衡的发生。 subscribe() 方法 再均衡监听器 ConsumerRebalanceListener 在 subscribe(Collection ConsumerRebalanceListener 是一个接口,包含2个方法,具体的释义如下: void onPartitionsRevoked(Collection partitions) 这个方法会在再均衡开始之前和消费者停止读取消息之后被调用。可以通过这个回调方法来处理消费位移的提交,以此来避免一些不必要的重复消费现象的发生。参数 partitions 表示再均衡前所分配到的分区。 将消费位移暂存到一个局部变量 currentOffsets 中,这样在正常消费的时候可以通过 commitAsync() 方法来异步提交消费位移,在发生再均衡动作之前可以通过再均衡监听器的 onPartitionsRevoked() 回调执行 commitSync() 方法同步提交消费位移,以尽量避免一些不必要的重复消费。 再均衡监听器还可以配合外部存储使用。我们将消费位移保存在数据库中,这里可以通过再均衡监听器查找分配到的分区的消费位移,并且配合 seek() 方法来进一步优化代码逻辑 消费者拦截器主要在消费到消息或在提交消费位移时进行一些定制化的操作。 费者拦截器需要自定义实现 org.apache.kafka.clients.consumer. ConsumerInterceptor 接口。ConsumerInterceptor 接口包含3个方法: KafkaConsumer 会在 poll() 方法返回之前调用拦截器的 onConsume() 方法来对消息进行相应的定制化操作,比如修改返回的消息内容、按照某种规则过滤消息(可能会减少 poll() 方法返回的消息的个数)。如果 onConsume() 方法中抛出异常,那么会被捕获并记录到日志中,但是异常不会再向上传递。 KafkaConsumer 会在提交完消费位移之后调用拦截器的 onCommit() 方法,可以使用这个方法来记录跟踪所提交的位移信息,比如当消费者使用 commitSync 的无参方法时,我们不知道提交的消费位移的具体细节,而使用拦截器的 onCommit() 方法却可以做到这一点。 在某些业务场景中会对消息设置一个有效期的属性,如果某条消息在既定的时间窗口内无法到达,那么就会被视为无效,它也就不需要再被继续处理了。下面使用消费者拦截器来实现一个简单的消息 TTL(Time to Live,即过期时间)的功能。 自定义的消费者拦截器 ConsumerInterceptorTTL 使用消息的 timestamp 字段来判定是否过期,如果消息的时间戳与当前的时间戳相差超过10秒则判定为过期,那么这条消息也就被过滤而不投递给具体的消费者。 实现自定义的 ConsumerInterceptorTTL 之后,需要在 KafkaConsumer 中配置指定这个拦截器,这个指定的配置和 KafkaProducer 中的一样,也是通过 interceptor.classes 参数实现的,此参数的默认值为“”。 Kafka消费者——API开发 标签:轮询 副本 can pre res tor classes count() 异常 原文地址:https://www.cnblogs.com/luckyhui28/p/12001816.html
消费者客户端
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.25.10:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
prop.put(ConsumerConfig.GROUP_ID_CONFIG,"test1");
KafkaConsumer consumer = new KafkaConsumer(prop);
try{
consumer.subscribe(Arrays.asList("topic1"));
ConsumerRecords订阅主题
consumer.subscribe(Arrays.asList("topic1"));
consumer.subscribe(Pattern.compile("topic-.*")); public void subscribe(Collection订阅分区
public void assign(Collectionpublic final class TopicPartition implements Serializable {
private int hash = 0;
private final int partition;
private final String topic;
public TopicPartition(String topic, int partition) {
this.partition = partition;
this.topic = topic;
}consumer.assign(Arrays.asList(new TopicPartition("topic",0)));public Listpublic class PartitionInfo {
private final String topic; //主题名称
private final int partition; /分区编号
private final Node leader; //leader副本
private final Node[] replicas; //AR集合
private final Node[] inSyncReplicas; //ISR集合取消订阅
同样的,如果把subscribe或assign的参数设置为空集合,也就等同于unsubscriber()方法。
如果没有订阅任何主题或者分区,再继续执行消费程序就会报出异常。订阅总结
消息消费
poll
ConsumerRecord
public static final long NO_TIMESTAMP = -1L;
public static final int NULL_SIZE = -1;
public static final int NULL_CHECKSUM = -1;
private final String topic;
private final int partition;
private final long offset;
private final long timestamp;
private final TimestampType timestampType;
private final int serializedKeySize;
private final int serializedValueSize;
private final Headers headers;
private final K key;
private final V value;
private volatile Long checksum;
public List位移提交
自动提交
手动提交
同步提交
ConsumerRecordsfinal int minBatchSize = 200;
Listpublic void commitSync(final Mapwhile (isRunning.get()) {
ConsumerRecordstry {
while (isRunning.get()) {
ConsumerRecords手动提交
commitAsync 方法有三个不同的重载方法public void commitAsync()
public void commitAsync(OffsetCommitCallback callback)
public void commitAsync(final Mapwhile (isRunning.get()) {
ConsumerRecordstry {
while (isRunning.get()) {
//poll records and do some logical processing.
consumer.commitAsync();
}
} finally {
try {
consumer.commitSync();
}finally {
consumer.close();
}
}控制和关闭消费
public void pause(Collectionpublic Setpublic void close()
public void close(Duration timeout)
@Deprecated
public void close(long timeout, TimeUnit timeUnit)指定位移消费
KafkaConsumer 中的 seek() 方法提供了这个功能。public void seek(TopicPartition partition, long offset)KafkaConsumerKafkaConsumerKafkaConsumerpublic Mappublic void seekToBeginning(Collectionpublic MapMap消费位移保存在DB中
consumer.subscribe(Arrays.asList(topic));
//省略poll()方法及assignment的逻辑
for(TopicPartition tp: assignment){
long offset = getOffsetFromDB(tp);//从DB中读取消费位移
consumer.seek(tp, offset);
}
while(true){
ConsumerRecords再均衡
void onPartitionsAssigned(Collection partitions) 这个方法会在重新分配分区之后和消费者开始读取消费之前被调用。参数 partitions 表示再均衡后所分配到的分区。Map
consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection消费者拦截器
public class ConsumerInterceptorTTL implements
ConsumerInterceptorprops.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG,
ConsumerInterceptorTTL.class.getName());