HTML文档解析和DOM树的构建
2021-01-26 02:12
阅读:548
YPE html>
标签:nat jpg 原理 图片 doctype 接收 渲染 结果 bsp
浏览器解析HTML文档生成DOM树的过程,以下是一段HTML代码,以此为例来分析解析HTML文档的原理
HelloWorld
picture:

A paragraph of explanatory text...
豌豆资源搜索网站 https://55wd.com
浏览器解析HTML文档,在
中发现了
首先树构建器接收到标签解析器发来的起始标签名后,会加入到栈中,图1是解析到
标签的栈中压入的内容,共有
三个标签,此时还未向DOM树中添加任何结点(图中黑色实线框代表开始标签,红色虚线框代表结束标签,结束标签不会入栈)。
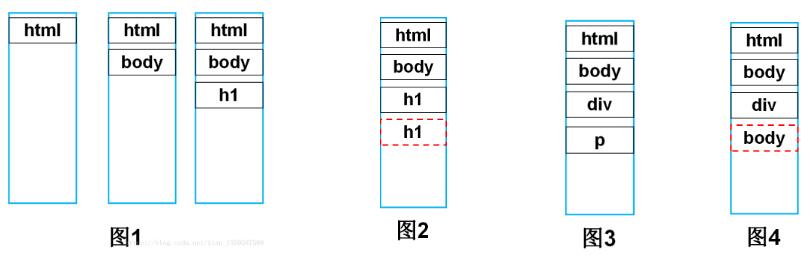
继续向下解析,接收到一个结束标签,此时查询栈顶元素,如果和传入的结束标签属于同种类型的p标签(如图2),则将栈顶元素弹出,向DOM树中加入此节点,然后继续向下解析(如图3)。
如果遇到的是没有封闭标签的元素如
依次向下解析,当栈为空,即根节点也加入到DOM树中,DOM树构建完毕。
这里需要指出的是,当某个元素缺失结束标签时,假如上述代码中第一个
标签缺失了
结束标签,即:
HelloWorld
picture:
 "example.png"/>
"example.png"/>
A paragraph of explanatory text...
那么,此时的栈如图4所示。即此时传来的结束标签是,而栈顶元素是
,两者不是同一种标签,说明div缺少了结束标签,这种情况也将栈顶元素弹出,加入到DOM树中。相当于给补了一个结束标签。
HTML文档解析和DOM树的构建
标签:nat jpg 原理 图片 doctype 接收 渲染 结果 bsp
原文地址:https://www.cnblogs.com/ypppt/p/13233351.html
评论
亲,登录后才可以留言!