c# 关于抓取网页源码后中文显示乱码的原因分析和解决方法
2021-01-27 15:15
标签:如何 pre 字节数组 buffer append end 请求 方法 one 原因分析:首先,目前大多数网站为了提升网页浏览传输速率都会对网站内容在传输前进行压缩,最常用的是GZIP压缩解压解压算法,也是支持最广的一种。 因为网站传输时采用的是GZIP压缩传输,如果我们接受webrespones接受数据未按照GZIP进行解压显示,那么就会造成乱码,如何知道网站是否是GZIP或者其他压缩方式传输的呢? 我这里用360浏览器做例子,如下图 可以看到,百度传输方式为gzip,deflate方式发给客户端数据 知道了原因我们下面来解决问题 2、通过GZIP解压 方法如下,此方法作用是输入url地址,返回一个解压后的string内容字符串。 //定一个解码gzip压缩格式网页的方法 c# 关于抓取网页源码后中文显示乱码的原因分析和解决方法 标签:如何 pre 字节数组 buffer append end 请求 方法 one 原文地址:https://www.cnblogs.com/arcticfish/p/11925642.html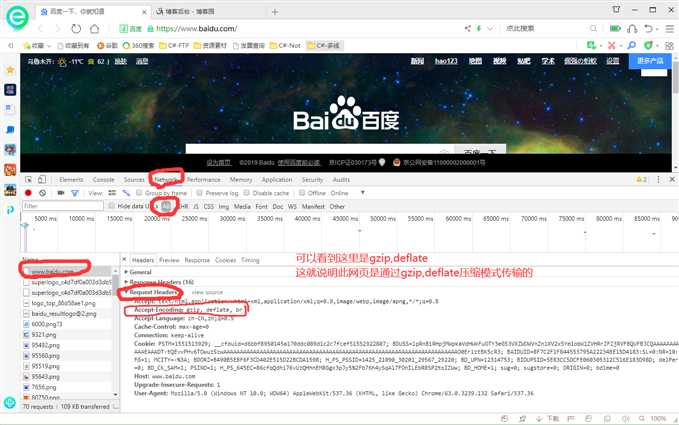
private static string getGzip(string u)
{
StringBuilder sb = new StringBuilder(204800);//200K对于频繁拼接的字符串,用stringbuilder比string节约内存和提升性能
WebClient wc = new WebClient();//定义一个发送和接收web数据的公用方法类。
wc.Headers[HttpRequestHeader.AcceptEncoding]="gzip,deflate";//接收gzip类型的数据
wc.Headers[HttpRequestHeader.AcceptLanguage]="zh-CN,zh";//指定请求头的语言类型为中文,
byte[] buffer= wc.DownloadData(u);//将 wc对象的downloaddata()方法下载到的资源存入本地buffer中
GZipStream g=new GZipStream((Stream)(new MemoryStream(buffer)),CompressionMode.Decompress);//定义一个压缩或者解压流的对象,设置为解压
byte[] tmpbuffer=new byte[20480];//定一个20K的临时字节数组
int len=g.Read(tmpbuffer,0,20480); //
while(len>0)
{
sb.Append(Encoding.Default.GetString(tmpbuffer,0,len)); //转换成相应的格式,比如使用的是GBK我们默认就是default,如果是UTF-8就写成UTF-8。这个可以通过右键查看源码找到编码格式。
len=g.Read(tmpbuffer,0,20480);
}
g.Close();
return sb.ToString();
文章标题:c# 关于抓取网页源码后中文显示乱码的原因分析和解决方法
文章链接:http://soscw.com/index.php/essay/47815.html