上千元的Python爬虫外包案例,学会你就赚了
2021-01-28 13:13
标签:put csv pat iter 介绍 http class @class 淘宝 前言 随着互联网时代的到来,人们更加倾向于互联网购物。某宝又是电商行业的巨头,在某宝平台中有很多商家数据。 今天带大家使用python+selenium工具获取这些公开的 适合人群: Python零基础、对爬虫数据采集感兴趣的同学! 环境介绍: python 3.6 1、安装selenium模块 2、请求网页地址 3、登录淘宝账户,并搜索商品 4、获取商品数据 如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。获取方式,私信小编 “ 资料 ”,即可免费获取哦! 上千元的Python爬虫外包案例,学会你就赚了 标签:put csv pat iter 介绍 http class @class 淘宝 原文地址:https://www.cnblogs.com/python0921/p/12838314.html
pycharm
selenium
timepip install selenium
if __name__ == ‘__main__‘:
keyword = input(‘请输入你要查询的商品数据:‘)
driver = webdriver.Chrome()
driver.get(‘https://www.taobao.com‘)
main()
def search_product(key):
"""模拟搜索商品,获取最大页数"""
driver.find_element_by_id(‘q‘).send_keys(key) # 根据id值找到搜索框输入关键字
driver.find_element_by_class_name(‘btn-search‘).click() # 点击搜索案例
driver.maximize_window() # 最大化窗口
time.sleep(15)
page = driver.find_element_by_xpath(‘//*[@id="mainsrp-pager"]/div/div/div/div[1]‘) # 获取页数的标签
page = page.text # 提取标签的文字
page = re.findall(‘(\d+)‘, page)[0]
# print(page)
return int(page)
def get_product():
divs = driver.find_elements_by_xpath(‘//div[@class="items"]/div[@class="item J_MouserOnverReq "]‘)
for div in divs:
info = div.find_element_by_xpath(‘.//div[@class="row row-2 title"]/a‘).text # 商品名称
price = div.find_element_by_xpath(‘.//strong‘).text + ‘元‘ # 商品价格
deal = div.find_element_by_xpath(‘.//div[@class="deal-cnt"]‘).text # 付款人数
name = div.find_element_by_xpath(‘.//div[@class="shop"]/a‘).text # 店铺名称
print(info, price, deal, name, sep=‘|‘)
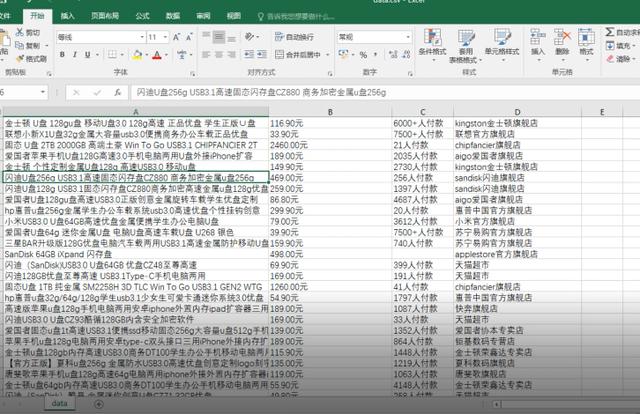
with open(‘data.csv‘, ‘a‘, newline=‘‘) as csvfile: # newline=‘‘ 指定一行一行写入
csvwriter = csv.writer(csvfile, delimiter=‘,‘) # delimiter=‘,‘ csv数据的分隔符
csvwriter.writerow([info, price, deal, name]) # 序列化数据,写入csv
def main():
search_product(keyword)
page = get_product()

上一篇:java JDK 官网下载教程
下一篇:JUC---06线程间通信(二)
文章标题:上千元的Python爬虫外包案例,学会你就赚了
文章链接:http://soscw.com/index.php/essay/48234.html