CVPR2020:4D点云语义分割网络(SpSequenceNet)
2021-01-28 17:12
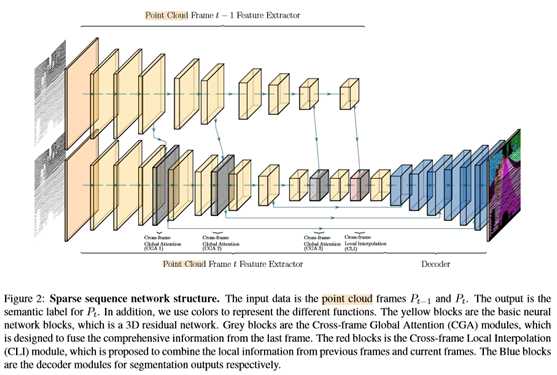
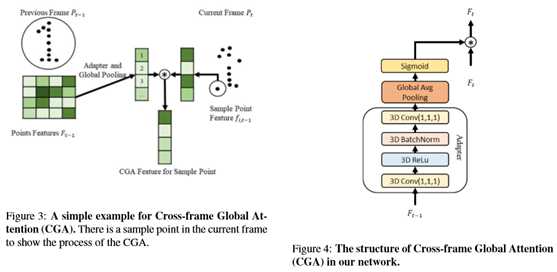
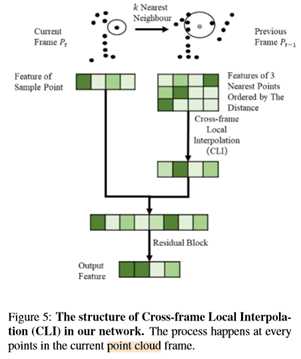
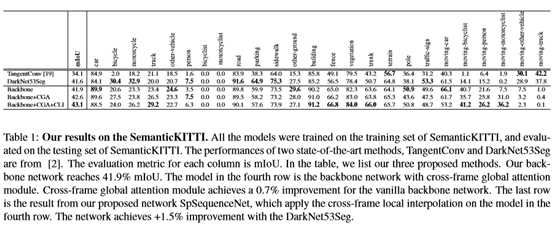
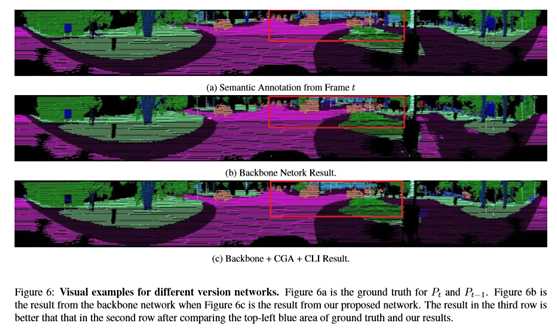
标签:设置 track 时间序列 静态对象 backbone 论文 语义 图像 可视化 CVPR2020:4D点云语义分割网络(SpSequenceNet) SpSequenceNet: Semantic Segmentation Network on 4D Point Clouds 论文地址: https://openaccess.thecvf.com/content_CVPR_2020/papers/Shi_SpSequenceNet_Semantic_Segmentation_Network_on_4D_Point_Clouds_CVPR_2020_paper.pdf 摘要 点云在许多应用中非常有用,比如自动驾驶和机器人技术,因为它们提供周围环境的自然三维信息。虽然对三维点云有着广泛的研究,但是对于一系列连续的三维点云框架的4D点云场景理解是一个新兴的课题,但尚未得到充分的研究。利用4D点云(3D点云视频),机器人系统可以利用先前帧的时间信息来增强其鲁棒性。然而,现有的4D点云语义分割方法由于其网络结构中的时空信息丢失,导致分割精度不高。本文提出SpSequenceNet来解决这个问题。该网络基于三维稀疏卷积进行设计。我们引入了两个新的模块:跨帧全局注意模块和跨帧局部插值模块,来捕捉4D点云中的时空信息。我们在SemanticKITTI上进行了大量的实验,在mIoU上获得了43.1%的最新结果,比之前的最佳方法提高了1.5%。 1.介绍 场景理解是计算机视觉中的一个基本问题。对于在现实世界中工作的自动驾驶汽车和机器人系统,场景理解的性能和鲁棒性至关重要,因为错误的决策可能会导致致命的事故。研究人员正试图利用更多的信息来提高性能和健壮性。由激光雷达或深度相机采集的三维点云提供了比二维图像更多的自然几何信息。此外,汽车和机器人总是在一段时间内连续工作,因此环境不断变化。在这个约束下,系统可以利用来自先前时间戳的时间信息作为提示和限制。语义分割是场景理解中的一项基本任务。在二维图像上,任务是一个每像素分类问题,它为图像中的每个像素分配相应的类别。受FCN[13]的启发,在这一领域取得了巨大的成就,如Deeplab V3+[3]、Re-finenet[12]和PSPNet[27]。同时,基于图像语义分割开发了许多任务,如点云分割、视频分割等。我们的工作将点云语义分割和视频语义分割结合起来,提高了场景理解的性能。4D语义分割是一个更具挑战性的任务,因为它同时涉及空间和时间信息。4D数据集具有丰富的现实世界信息。SemanticKITTI[2](图1)是最大的4D点云数据集之一,总共包含约44000个点云帧。SemanticKITTI基线法将4D语义分割简化为3D语义分割,将多个点云框架合并为一个点云,并对转换后的三维点云应用三维分割方法。在多个点云帧的合并过程中,会造成时空信息的丢失。为了解决这一问题,我们提出了SpSequenceNet对4D点云数据进行三维立方体形式的操作,减少了空间信息的损失。同时,我们设计了一个跨帧全局注意模块和一个新的交叉帧局部插值模块来提取不同帧的时间特征。我们在SemanticKITTI上评估我们的网络[2]。主要贡献如下: 我们设计了一个网络SpSequenceNet,直接从4D点云(3D点云视频)中获取时空信息,进行语义分割。 •我们引入跨帧全局注意(CGA)模块,从先前的点云帧生成一个全局掩码,并将生成的掩码用于当前点云帧的分割。 •我们提出了交叉帧局部插值(CLI)来融合两个点云帧之间的信息。它将时空信息结合起来,提高了语义分割的质量。 •我们在SemanticKITTI[2]上获得了最新的结果,比现有方法高出1.5%。 2.相关工作 目前,关于4D语义分割的研究还很少。4D语义分割需要网络同时提取空间信息和时间信息。因此,我们将4D语义分割任务分为两个子任务,即三维语义分割中的空间感知和时间感知,这是一个值得探索的新领域。我们将在下面几节讨论这两个相关的部分。 2.1.三维语义分割 深度传感器收集点云,以反映真实世界中物体的形状。点云语义挖掘的困境在于点云数据的稀疏性和无序性。在以往的研究中,传统的三维卷积[20]使用密集计算,复杂度达到O(n3)。点云的稀疏性导致三维计算量大、资源浪费大卷积。所以在点云数据处理方面做了大量的工作,但在点云数据的利用上还存在许多分歧。一般来说,点云的处理方法主要有三种:投影法、点网法和三维卷积法。首先,基于投影的方法是二维语义分割的扩展[24,25,23]。这些方法执行投影,通常是球面投影,将三维点变换到曲面上。然后,在投影面上应用图像语义分割网络。基于投影的方法达到了实时性要求(squezeseg[24]达到13.5ms/帧),而基于投影的方法的最终性能通常低于其他方法。类似点网的方法是从新的结构PointNet[15]发展而来的。这一系列方法直接对原始点云数据进行操作,并将点的坐标和RGB特征作为输入特征。然后分别对网络上的每个共享点生成MLP预测。性能受到限制,因为它降低了局部空间关系。PointNet++[16]限制一个小区域来提取局部空间关系。PointCNN[11]重新定义了一种使用MLP和邻域权重的卷积运算,以获得灵活的局部空间信息。KPConv[21]应用了更灵活的邻居机制,并在类似点网的方法中获得了最先进的性能。点态CNN[9]使用带体素的核权重来组合局部信息。KPConv[21]后面是PointCNN和PCNN,在类似PointNet的方法中获得了最先进的性能。 最后一种方法是三维卷积网络。如本节开头所述,3D卷积的计算消耗很高。这方面的主要研究集中在有效性方面。在OctNet[17]中,加入八叉树结构来表示3D空间,并引导网络进行卷积。许多著作[18,6]都是基于这种方法发展起来的。它们将点云数据组织成立方体,并用八叉树、Kdtree等索引,这样就可以很容易地使用该索引进行卷积。此外,基于稀疏3D卷积的方法[8,4]只沿着输入中的活动体素执行3D卷积。稀疏三维卷积可以加速卷积运算,并与密集卷积共享知识库。 2.2.4D时间特征提取 4D时间特征提取主要是对时间序列中的信息进行挖掘。最近的一项研究是Minkowski卷积神经网络(MinkowskiNet)[4]。它将卷积函数从二维推广到四维,使得深度神经网络的理论无论维数如何都是共享的。4D MinkowskiNet缺乏可扩展性,因为计算量随着点和帧的增加而迅速增加。除了语义分割外,还有一些关于4D时间特征提取的研究。在STCNN[28]中,一个3D U-Net和一个用于时间信息的一维编码器被注册来自动编码大脑功能磁共振成像图像。STCNN在自动编码器上定位视觉,具有4D时间特征,不能推广到语义分割任务中。OpenPose[10]专注于用4D点云跟踪人类姿势的任务。它利用四维空间数据,通过人体检测和二维回归,实时检测人手位置。PointFlowNet[1]基于类似点网的方法,融合了t帧和t-1帧的两个特征来推断每个点的运动。然后,设计不同的损失来提取自我运动。总的来说,在分割任务中直接操纵4D点云的方法很少。因此,我们也从视频语义分割方法中探索一些思路。MaskTrack和网络调制[14,26]使用来自最后一帧的信息和预测来指导当前预测。 3.稀疏序列网络 我们在图2中展示了我们提出的模型结构。一般来说,4D点云分割的问题设置与普通的三维语义分割相似。我们以RGB-D相机(r,g,b)和激光雷达(r)两个源建立了数据集。注意,我们以每个点的坐标(x,y,z)和点特征fi,t作为模型输入,其尺寸为(x,y,z,3)(RGB-D)或(x,y,z,1)(激光雷达)。 3.1.网络体系结构概述 我们的网络是基于三维卷积,它利用体素方法。我们用两个3D张量Pt和Pt−1来预测标签pi,t。该网络的设计遵循U-net的风格,由子流形稀疏卷积网络(SSCN)实现[7]。为了平衡训练和推理的速度和性能,我们对主干网进行了一些修改。具体地说,在SSCN的原始版本中,有七个编码器块具有到反褶积块的跳过路径,这形成了一个对称的结构。但是对称设计存在着表示能力有限、计算量大等缺点。因此,我们减少了跳过路径的数量。此外,我们在编码器中加入了一些块,目的是提高表达能力和调整网络。解码器是流线型的,包含跳跃路径的减少。在构建了模型之后,下一步是构建块来融合来自不同帧的信息。在编码器阶段,我们的网络通过两个不同的分支接收Pt和Pt−1。如图2所示。为了构建更好的融合特征,我们将信息分为全局信息和局部信息两部分。首先,针对全局信息设计了跨框架全局注意模块。一般来说,在不同的阶段有几个跨框架的全局注意模块。跨帧全局注意模块对特征进行选择,使主干网更关注关键特征。第二,交叉帧局部插值侧重于局部信息,用于融合编码器端部Pt−1和Pt的信息。 3.2.跨框架全局关注 如上所述,我们使用跨框架全局注意(CGA)模块提取时间全局语义。我们在图3中展示了一个关于交叉帧全局注意力模块的简单解释。受自我注意机制的启发,我们设计了跨帧全局注意模块来生成当前帧Pt的掩模。掩模包含关于Pt−1特征的外观信息。为了突出特征Ft的关键部分和抑制无关特征,cross-frame全局注意力模块利用t-1的外观信息来指导模型。全局语义分布到特征的各个层次。选取跳转路径中涉及的层,应用交叉帧全局注意。它降低了计算复杂度,提高了精度。 3.3.交叉帧局部插值 在编码阶段的最后,我们设计了一个跨帧局部内插(CLI)模块,实现了对两个点云帧之间的时间信息的局部融合。光流方法[22,29]使用来自两个不同帧的最近像素来生成局部光流并获得显著的性能。受这些方法的启发,设计了交叉帧局部插值来提取点云Pt−1和Pt之间的部分差异。交叉帧局部插值的基本思想是 如图5所示,这是为了寻找k个最近邻并生成一个新的局部特征来帮助模型融合时间信息。同时,交叉帧局部插值法总结了最近点的面积,并将空间信息与所选点的特征相融合。 4.实验测试 基线 结果见表1。SemanticKITTI中的基线是TangentConv[19]和DarkNet53Seg。他们将坐标系从Pt−4调整到Pt−1,并将所有帧合并为一个点云作为输入。TangentConv是一种类似点网的方法,而DarkNet53Seg是一种基于投影的方法。 主干网+CGA+CLI。结构如图2所示。该网络包括主干网、跨帧全局注意和跨帧局部插值,利用前3个最近邻生成区域特征。我们的网络使用DarkNet53Seg实现+1.5%的mIoU,使用主干网达到+1.2%mIoU。综上所述,与表1中的其他高级方法相比,我们提出的方法对小目标和大静态对象的运动更为敏感,而对移动的大对象不敏感。这种现象是由我们提出的方法的特点造成的。具体地说,在所提出的网络中,它检测同一个体素系统中的特征在t−1和t之间的移动。当物体移动时,小物体的面积有显著的变化,而大物体的面积变化不大。 将原始SpSequenceNet的多帧预测重新组织为两个输出:单帧预测和运动状态。将静态目标和运动状态相结合,生成运动目标。重组预测的输出在表3中称为重组预测。结果见表3。首先,我们的网络具有改进语义切分的能力。多头网络的mIoU改善率达到1.6%,重组预测的mIoU改善率为2.7%,而骨干网的mIoU改善率为54.4%。之后,与重组后的预测结果相比,多头网络的运动状态改善了2%,但单帧任务的运动状态下降了1.1%,这表明如果模型直接将运动状态纳入训练对象中,将不利于目标的表示能力。 SpSequenceNet的有效性 我们在图6中展示了一个可视化的比较。对于主干网,我们可以将图6b与图6c进行比较,发现图6b红色框内的区域不整洁。具体而言,图6b代表了普通主干网。在图6c中,前面提到的区域比较单一。因此,交叉帧全局注意和交叉帧局部插值提高了结果的平滑度。跨框架全球关注。如表1所示,跨框架全球注意力的提高具有重要意义。具体地说,交叉帧全局关注增强了香草主干在某些类中的性能,因为它有助于主干更好地跟踪小对象。上k交叉帧局部插值。我们从最后一帧Pt−1中选取K个最近邻点作为当前帧的pi,t,生成交叉帧局部插值的特征。我们用前1、3和5个最近邻对模型进行交叉帧局部插值训练,在下一部分中称为top k CLI。对于top1cli和top3cli,我们将结果提交给SemanticKITTI进行测试。结果表明,top1cli导致mIoU下降,与预期一致。表1中top 1cli的精度甚至比backbone+CGA还要差。对于边界上的点,具有相同正确标签的最近点的可能性很低,导致下降6%。同时,前3名CLI的结果达到了最先进的水平。最后,这里不显示前5个CLI的结果,因为每个时段的验证性能都与前3个CLI相似。top 5 CLI的性能与top 3 CLI相似。因此,无需提交试验结果。根据计算量的增加,3个最近邻点适合于交叉帧局部插值。 CVPR2020:4D点云语义分割网络(SpSequenceNet) 标签:设置 track 时间序列 静态对象 backbone 论文 语义 图像 可视化 原文地址:https://www.cnblogs.com/wujianming-110117/p/13209314.html

下一篇:GEOJSON 的渲染实例
文章标题:CVPR2020:4D点云语义分割网络(SpSequenceNet)
文章链接:http://soscw.com/index.php/essay/48312.html