结合puppeteer和egg.js搭建html转pdf或png的node中间层服务。
2021-01-29 09:13
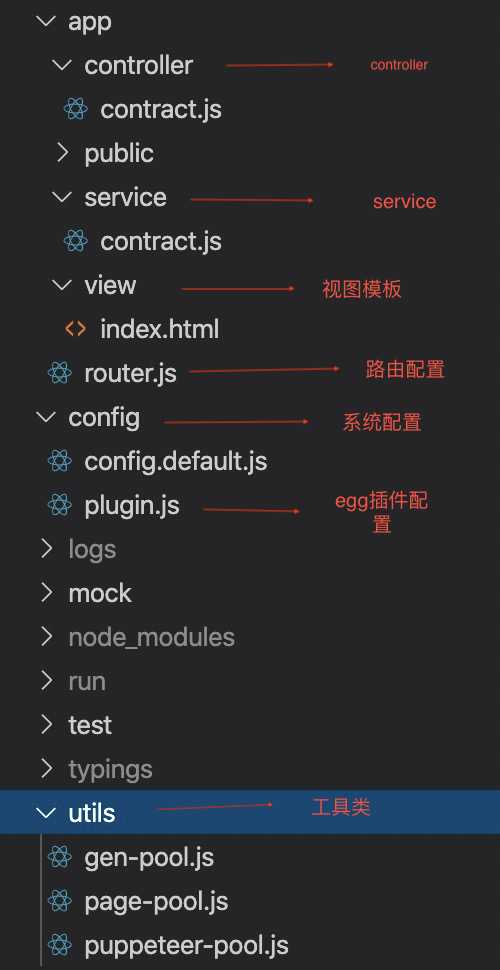
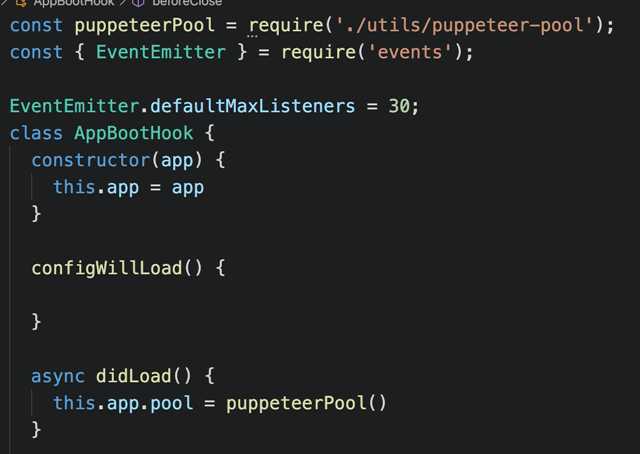
标签:chrome浏览器 模板 node imp UNC ash inter create 最小 由于项目需要搭建一个node服务器,用来做html模板渲染,以及将渲染结果转化为pdf或者png。项目已放在GitHub,查看源码,请点这里。经过一段时间的调研,主要对比了两个工具。一个是chrome官方提供的无头浏览器node包,puppeteer,另一个是命令行工具wkhtmltopdf。接下来简单介绍一下两者的区别和优缺点。 1、使用简单, 2、占用空间小,使用的是webkit engine渲染, 3、渲染效果较好,对css支持比较友好, 1、对自定义header不支持domString,只支持url 1、使用简单,官网直接有api提供 2、渲染效果好,由于使用的是chrome的无头浏览器,所以渲染效果和chrome差不多。 3、chrome官方出品的开源包,所以维护者比较多。 4、直接支持domString渲染。 1、要下载chrome浏览器,占用空间大, 2、启动chrome实例比较耗时, 后面经过使用链接池的优化,chrome的耗时成功降下来。由于项目比较看重时间损耗,所以最终选择puppeteer。接下来切入正题。本文将讲述puppeteer的一些优化措施,以及怎么结合egg.js搭建成最终的服务器。 1、开发环境: egg -v 2.15.1 node.js -v 12.16.3 egg-view-nunjucks -v 2.2.0 puppeteer -v 4.0.0 generic-pool -v 3.7.1 2、项目构建: 建议直接使用egg模板进行初始化 接下来直接npm i就可以了。然后安装我们项目所需要的一些依赖,比如我们的主角puppetter、node的一个promise链接池generic-pool、egg的模板渲染引擎egg-view-nunjucks。 egg.js 奉行『约定优于配置』,所以对项目目录什么的都有严格的要求,具体信息请查看官方文档。下面是我的目录结构 由于我们引入了模板引擎,所以需要进行一些简单的配置,首先打开config/plugin.js加上如下代码: 接下来打开config/config.default.js 加入以下代码。模板引擎的配置就完成了。 3、puppeteer的优化方案: 受到一篇关于puppeteer和generic-pool文章的启发,链接点这里,在它的基础上做了一些改动。主要是因为puppeteer启动一个chrome实例的时间成本较大。然后每启动一个页面也需要时间成本。所以考虑使用链接池来减少启动chrome实例和page页面的时间消耗,建立一个chrome实例的链接池,封装一个page页面的链接池。每次请求来了以后直接去链接池里取出实例和页面。使用page.setContent()来进行操作,可以大大地节省时间,另外关于chrome的一些启动参数修改,比如单进程模式运行 Chromium等。好的废话不多说直接上代码: pagePool。js genPool。js puppeteer-pool.js 如上所示,我们封装了一个page的链接池,在page链接池的基础上封装了一层chrome实例的链接池。项目流程是:收到http请求>从链接池中取出chrome实例>再从chrome实例的链接池中取出一个page链接>在这个链接中执行你的业务代码>返回数据。这样做的好处就是每次请求过来都可以复用之前的page,减少了开销。当然这样的缺点就是,你初始化的时候需要一些内存空间去存放这些实例。 4、结合eggjs: 在egg.js中首先启动服务器时候需要初始化这些实例,创建一个app.js然后在didLoad生命周期中初始化实例: 接下来就是写你的controller和service进行业务逻辑。基本上已经大功告成,如有问题,欢迎大家留言指正。 结合puppeteer和egg.js搭建html转pdf或png的node中间层服务。 标签:chrome浏览器 模板 node imp UNC ash inter create 最小 原文地址:https://www.cnblogs.com/marvey/p/13205117.html
工具
优点
缺点
wkhtmltopdf
puppeteer
npm init egg --type=simple
npm i generic-pool puppeteer egg-view-nunjucks
view: {
enable: true,
package: ‘egg-view‘
},
nunjucks: {
enable: true,
package: ‘egg-view-nunjucks‘
}
// add your user config here
const userConfig = {
// myAppName: ‘egg‘,
view: {
defaultViewEngine: ‘nunjucks‘,
defaultExtension: ‘.html‘,
mapping: {
‘.html‘: ‘nunjucks‘
}
}
};
const puppeteer = require(‘puppeteer‘);
const genPool = require(‘./gen-pool‘);
const pagePool = async (config, options) => {
const browser = await puppeteer.launch(options)
const factory = {
create: () => {
return browser.newPage()
.then(instance => {
instance.useCont = 0;
return instance
})
},
destroy: (instance) => {
instance.close()
},
validate: (instance) => {
return Promise.resolve(instance)
.then(valid => {
Promise.resolve(valid && (config.maxUses config.maxUses))
})
}
}
const pool = genPool(factory, config)
pool.closeBrowser = () => {
return browser.close()
}
return pool
}
module.exports = pagePool
const genericPool = require(‘generic-pool‘);
const genPool = (factory, config) => {
/**
* 创建一个链接池
*/
const pool = genericPool.createPool(factory, config)
const genericAcquire = pool.acquire.bind(pool)
/**
* 消耗次数统计
*/
pool.acquire = () =>
genericAcquire()
.then((instance) => {
instance.useCont += 1;
return instance
})
/**
* 不管调用成功与否,都消耗一次实例
*/
pool.use = fn => {
let resource
return pool.acquire()
.then(res => {
resource = res
return resource
})
.then(fn)
.then(
(res) => {
pool.release(resource)
return res
},
(err) => {
pool.release(resource)
return err
}
)
}
return pool
}
module.exports = genPool
const pagePool = require(‘./page-pool‘);
const genericPool = require(‘generic-pool‘);
/**
* 生成一个puppeteer链接池
* @param {Object} [options] 创建池的配置
* @param {Object} [options.poolConfig] 链接池的配置参数
* @param {Number} [poolConfig.max = 10] 链接池的最大容量
* @param {Number} [poolConfig.min = 2] 链接池的最小活跃量
* @param {Boolean} [poolConfig.testOnBorrow = true] 在将 实例 提供给用户之前,池应该验证这些实例。
* @param {Boolean} [poolConfig.autoStart = true] 启动时候是否初始化实例
* @param {Number} [poolConfig.idleTimeoutMillis = 60*60*1000] 实例多久不使用将会被关闭(60分钟)
* @param {Number} [poolConfig.evictionRunIntervalMillis = 3*60*1000] 多久检查一次是否在使用实例(3分钟)
* @param {Object} [options.puppeteerConfig] puppeteer的启动参数配置
*/
const puppeteerPool = (options = { poolConifg: {}, puppeteerConfig: {} }) => {
const config = {
max: 10,
min: 2,
maxUses: 2048,
testOnBorrow: true,
autoStart: true,
idleTimeoutMillis: 60 * 60 * 1000,
evictionRunIntervalMillis: 3 * 60 * 1000,
...options.poolConfig
}
const launchOptions = {
ignoreHTTPSErrors: true,
headless: true,
pipe: true,
args: [
// ‘--disabled-3d-apis‘,
// ‘--block-new-web-contents‘,
// ‘--disable-databases‘,
‘–disable-dev-shm-usage‘,
// ‘--disable-component-extensions-with-background-pages‘,
‘–-no-sandbox‘,
// ‘--disable-setuid-sandbox‘,
‘–-no-zygote‘,
‘–-single-process‘,
‘--no-first-run‘,
‘--disable-local-storage‘,
// ‘--disable-media-session-api‘,
// ‘--disable-notifications‘,
// ‘--disable-pepper-3d‘,
‘--disabled-gpu‘
],
...options.puppeteerConfig
}
const factory = {
create: async() => {
const page = await pagePool(config, launchOptions)
return Promise.resolve(page)
},
destroy: async (instance) => {
if(instance.drain) {
await instance.drain()
.then(() => {
instance.clear()
})
}
instance.closeBrowser()
},
validate: (instance) => {
return Promise.resolve(true)
}
}
const pool = genericPool.createPool(factory, config)
return pool
}
module.exports = puppeteerPool
文章标题:结合puppeteer和egg.js搭建html转pdf或png的node中间层服务。
文章链接:http://soscw.com/index.php/essay/48612.html