标签:sys spl dir update 搜索 自己 情况 需要 服务
最近由于工作原因,一直忙于公司的各种项目(大部份都是基于spring cloud的微服务项目),故有一段时间没有与大家分享总结最近的技术研究成果的,其实最近我一直在不断的深入研究学习Spring、Spring Boot、Spring Cloud的各种框架原理,同时也随时关注着.NET CORE的发展情况及最新技术点,也在极客时间上订阅相关的专栏,只要下班有空我都会去认真阅读观看,纸质书箱也买了一些,总之近一年都是在通过:微信技术公众号(.NET、JAVA、算法、前端等技术方向)、极客时间、技术书箱 不断的吸取、借鉴他人之精华,从而不断的充实提高自己的技术水平,所谓:学如逆水行舟,不进则退,工作中学习,学习后工作中运用,当然写文章分享是一种总结,同时也是“温故而知新”的最佳应用。
前面废话说得有点多了,就直奔本文的主题内容,编写一个基于Lucene.Net的搜索引擎查询通用工具类:SearchEngineUtil,Lucene是什么,见百度百科 ,重点是:Lucene是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,Lucene.NET是C#及.NET运行时下的另一种语言的实现,官网地址:http://lucenenet.apache.org/ ,具体用法就不多说了,官网以及网上都有很多,但由于Lucene.Net的原生SDK中的API比较复杂,用起来不太方便,故我进行了适当的封装,把常用的增、删、改、查(分页查)在保证灵活度的情况下进行了封装,使得操作Lucene.Net变得相对简单一些,代码本身也不复杂,贴出完整的SearchEngineUtil代码如下:
using Lucene.Net.Analysis.PanGu;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.QueryParsers;
using Lucene.Net.Search;
using Lucene.Net.Store;
using NLog;
using PanGu;
using PanGu.HighLight;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Reflection;
using System.Text;
namespace CN.Zuowenjun.Blog.Common
{
///
/// Lucene 搜索引擎实用工具类
/// Author:zuowenjun
///
public class SearchEngineUtil
{
///
/// 创建并添加索引记录
///
///
///
///
///
public static void AddIndex(string indexDir, TIndex indexData, Action setDocFiledsAction)
{
//创建索引目录
if (!System.IO.Directory.Exists(indexDir))
{
System.IO.Directory.CreateDirectory(indexDir);
}
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
bool isUpdate = IndexReader.IndexExists(directory);
if (isUpdate)
{
//如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
using (IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, IndexWriter.MaxFieldLength.UNLIMITED))
{
Document document = new Document();
setDocFiledsAction(document, indexData);
writer.AddDocument(document);
writer.Optimize();//优化索引
}
}
///
/// 删除索引记录
///
///
///
///
public static void DeleteIndex(string indexDir, string keyFiledName, object keyFileValue)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
if (!IndexReader.IndexExists(directory))
{
return;
}
using (IndexWriter iw = new IndexWriter(directory, new PanGuAnalyzer(), IndexWriter.MaxFieldLength.UNLIMITED))
{
iw.DeleteDocuments(new Term(keyFiledName, keyFileValue.ToString()));
iw.Optimize();//删除文件后并非从磁盘中移除,而是生成一个.del的文件,需要调用Optimize方法来清除。在清除文件前可以使用UndeleteAll方法恢复
}
}
///
/// 更新索引记录
///
///
///
///
///
public static void UpdateIndex(string indexDir, string keyFiledName, object keyFileValue, Document doc)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
if (!IndexReader.IndexExists(directory))
{
return;
}
using (IndexWriter iw = new IndexWriter(directory, new PanGuAnalyzer(), IndexWriter.MaxFieldLength.UNLIMITED))
{
iw.UpdateDocument(new Term(keyFiledName, keyFileValue.ToString()), doc);
iw.Optimize();
}
}
///
/// 是否存在指定的索引文档
///
///
///
///
///
public static bool ExistsDocument(string indexDir, string keyFiledName, object keyFileValue)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NativeFSLockFactory());
if (!IndexReader.IndexExists(directory))
{
return false;
}
var reader = IndexReader.Open(directory, true);
return reader.DocFreq(new Term(keyFiledName, keyFileValue.ToString())) > 0;
}
///
/// 查询索引匹配到的记录
///
///
///
///
///
///
///
///
///
public static List SearchIndex(string indexDir, Func> buildQueryAction,
Func> getSortFieldsFunc, Func buildResultFunc, bool needHighlight = true, int topCount = 0)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NoLockFactory());
if (!IndexReader.IndexExists(directory))
{
return new List();
}
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
BooleanQuery bQuery = new BooleanQuery();
var keyWords = buildQueryAction(bQuery);
Sort sort = null;
var sortFields = getSortFieldsFunc();
if (sortFields != null)
{
sort = new Sort();
sort.SetSort(sortFields.ToArray());
}
topCount = topCount > 0 ? topCount : int.MaxValue;//当未指定TOP值,则设置最大值以表示获取全部
TopDocs resultDocs = null;
if (sort != null)
{
resultDocs = searcher.Search(bQuery, null, topCount, sort);
}
else
{
resultDocs = searcher.Search(bQuery, null, topCount);
}
if (topCount > resultDocs.TotalHits)
{
topCount = resultDocs.TotalHits;
}
Dictionary highlightProps = null;
List results = new List();
if (resultDocs != null)
{
for (int i = 0; i
/// 分页查询索引匹配到的记录
///
///
///
///
///
///
///
///
///
///
///
public static List SearchIndexByPage(string indexDir, Func> buildQueryAction,
Func> getSortFieldsFunc, Func buildResultFunc, int pageSize, int page, out int totalCount, bool needHighlight = true)
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexDir), new NoLockFactory());
if (!IndexReader.IndexExists(directory))
{
totalCount = 0;
return new List();
}
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher searcher = new IndexSearcher(reader);
BooleanQuery bQuery = new BooleanQuery();
var keyWords = buildQueryAction(bQuery);
Sort sort = null;
var sortFields = getSortFieldsFunc();
if (sortFields != null)
{
sort = new Sort();
sort.SetSort(sortFields.ToArray());
}
TopScoreDocCollector docCollector = TopScoreDocCollector.Create(1, true);
searcher.Search(bQuery, docCollector);
totalCount = docCollector.TotalHits;
if (totalCount highlightProps = null;
List results = new List();
int indexStart = (page - 1) * pageSize;
int indexEnd = indexStart + pageSize;
if (totalCount
/// 设置结果高亮
///
///
///
///
///
///
private static T SetHighlighter(IDictionary dicKeywords, T model, ref Dictionary props)
{
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("", "");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new Segment());
highlighter.FragmentSize = 250;
Type modelType = typeof(T);
foreach (var item in dicKeywords)
{
if (!string.IsNullOrWhiteSpace(item.Value))
{
if (props == null)
{
props = new Dictionary();
}
if (!props.ContainsKey(item.Key))
{
props[item.Key] = modelType.GetProperty(item.Key, BindingFlags.IgnoreCase | BindingFlags.Public | BindingFlags.Instance);
}
var modelProp = props[item.Key];
if (modelProp.PropertyType == typeof(string))
{
string newValue = highlighter.GetBestFragment(item.Value, modelProp.GetValue(model).ToString());
if (!string.IsNullOrEmpty(newValue))
{
modelProp.SetValue(model, newValue);
}
}
}
}
return model;
}
///
/// 拆分关键词
///
///
///
public static string GetKeyWordsSplitBySpace(string keyword)
{
PanGuTokenizer ktTokenizer = new PanGuTokenizer();
StringBuilder result = new StringBuilder();
ICollection words = ktTokenizer.SegmentToWordInfos(keyword);
foreach (WordInfo word in words)
{
if (word == null)
{
continue;
}
result.AppendFormat("{0}^{1}.0 ", word.Word, (int)Math.Pow(3, word.Rank));
}
return result.ToString().Trim();
}
///
/// 【辅助方法】创建盘古查询对象
///
///
///
///
public static Query CreatePanGuQuery(string field, string keyword, bool needSplit = true)
{
if (needSplit)
{
keyword = GetKeyWordsSplitBySpace(keyword);
}
QueryParser parse = new QueryParser(Lucene.Net.Util.Version.LUCENE_30, field, new PanGuAnalyzer());
parse.DefaultOperator = QueryParser.Operator.OR;
Query query = parse.Parse(keyword);
return query;
}
///
/// 【辅助方法】创建盘古多字段查询对象
///
///
///
///
public static Query CreatePanGuMultiFieldQuery(string keyword, bool needSplit, params string[] fields)
{
if (needSplit)
{
keyword = GetKeyWordsSplitBySpace(keyword);
}
QueryParser parse = new MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields, new PanGuAnalyzer());
parse.DefaultOperator = QueryParser.Operator.OR;
Query query = parse.Parse(keyword);
return query;
}
}
}
里面除了使用了Lucene.Net nuget包,还单独引用了PanGu分词器及其相关组件,因为大多数情况下我们的内容会包含中文。如上代码就不再细讲了,注释得比较清楚了。下面贴出一些实际的用法:
创建索引:
SearchEngineUtil.AddIndex(GetSearchIndexDir(), post, (doc, data) => BuildPostSearchDocument(data, doc));
private Document BuildPostSearchDocument(Post post, Document doc = null)
{
if (doc == null)
{
doc = new Document();//创建Document
}
doc.Add(new Field("Id", post.Id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.Add(new Field("Title", post.Title, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("Summary", post.Summary, Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("CreateTime", post.CreateTime.ToString("yyyy/MM/dd HH:mm"), Field.Store.YES, Field.Index.NO));
doc.Add(new Field("Author", post.IsOriginal ? (post.Creator ?? userQueryService.FindByName(post.CreateBy)).NickName : post.SourceBy, Field.Store.YES, Field.Index.NO));
return doc;
}
删除索引:
SearchEngineUtil.DeleteIndex(GetSearchIndexDir(), "Id", post.Id);
更新索引:
SearchEngineUtil.UpdateIndex(GetSearchIndexDir(), "Id", post.Id, BuildPostSearchDocument(post));
分页查询:
var keyword = SearchEngineUtil.GetKeyWordsSplitBySpace("梦在旅途 中国梦");
var searchResult = SearchEngineUtil.SearchIndexByPage(indexDir, (bQuery) =>
{
var query = SearchEngineUtil.CreatePanGuMultiFieldQuery(keyword, false, "Title", "Summary");
bQuery.Add(query, Occur.SHOULD);
return new Dictionary {
{ "Title",keyword},{"Summary",keyword}
};
}, () =>
{
return new[] { new SortField("Id", SortField.INT, true) };
}, doc =>
{
return new PostSearchInfoDto
{
Id = doc.Get("Id"),
Title = doc.Get("Title"),
Summary = doc.Get("Summary"),
Author = doc.Get("Author"),
CreateTime = doc.Get("CreateTime")
};
}, pageSize, pageNo, out totalCount);
其它的还有:判断索引中的指定文档记录存不存在、查询符合条件的索引文档等在此没有列出,大家有兴趣的可以COPY到自己的项目中测试一下。
这里可以看一下我在自己的项目中(个人全新改版的自己博客,还在开发中)应用搜索场景的效果:
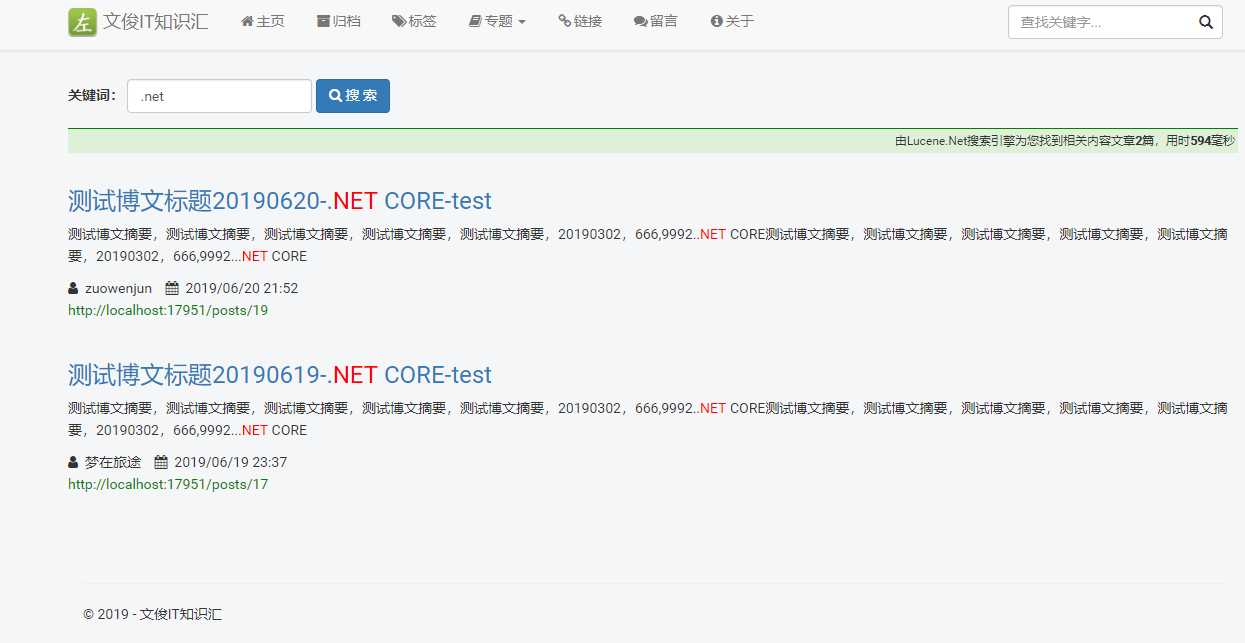
最后说明的是:Lucene并不是一个完整的全文检索引擎,但了解它对于学习elasticsearch、solr还是有一定的帮助,目前一般应用于实际的生产项目中,多半是使用更高层的elasticsearch、solr。
(本文中的代码我是今年很早前就写好了,只是今天才分享出来)
我喜欢对一些常用的组件进行封装,比如过往封装有:
基于MongoDb官方C#驱动封装MongoDbCsharpHelper类(CRUD类)
基于RabbitMQ.Client组件实现RabbitMQ可复用的 ConnectionPool(连接池)
C#编写了一个基于Lucene.Net的搜索引擎查询通用工具类:SearchEngineUtil
标签:sys spl dir update 搜索 自己 情况 需要 服务
原文地址:https://www.cnblogs.com/zuowj/p/11689563.html