Python过滤敏感词汇
2021-02-01 10:14
标签:相同 search 组合 png data- return 第一个 发布会 状态 最简单也是最直接的就是直接循环敏感词,然后使用replace过滤关键词,文章和敏感词少的时候还可以,多的时候效率就真的很一般了。 有两个技术要点, 1.使用Python正则表达式的re的sub()函数; 返回结果 在网上查了下敏感词过滤方案,找到了一种名为DFA的算法,即 Deterministic Finite Automaton 算法,翻译成中文就是确定有穷自动机算法。它的基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测,所以效率比方案一高不少。 假设我们有以下5个敏感词需要检测:傻逼、傻子、傻大个、坏蛋、坏人。那么我们可以先把敏感词中有相同前缀的词组合成一个树形结构,不同前缀的词分属不同树形分支,以上述5个敏感词为例,可以初始化成如下2棵树: 把敏感词组成成树形结构有什么好处呢?最大的好处就是可以减少检索次数,我们只需要遍历一次待检测文本,然后在敏感词库中检索出有没有该字符对应的子树就行了,如果没有相应的子树,说明当前检测的字符不在敏感词库中,则直接跳过继续检测下一个字符;如果有相应的子树,则接着检查下一个字符是不是前一个字符对应的子树的子节点,这样迭代下去,就能找出待检测文本中是否包含敏感词了。 我们以文本“你是不是傻逼”为例,我们依次检测每个字符,因为前4个字符都不在敏感词库里,找不到相应的子树,所以直接跳过。当检测到“傻”字时,发现敏感词库中有相应的子树,我们把他记为tree-1,接着再搜索下一个字符“逼”是不是子树tree-1的子节点,发现恰好是,接下来再判断“逼”这个字符是不是叶子节点,如果是,则说明匹配到了一个敏感词了,在这里“逼”这个字符刚好是tree-1的叶子节点,所以成功检索到了敏感词:“傻逼”。大家发现了没有,在我们的搜索过程中,我们只需要扫描一次被检测文本就行了,而且对于被检测文本中不存在的敏感词,如这个例子中的“坏蛋”和“坏人”,我们完全不会扫描到,因此相比方案一效率大大提升了。 在python中,我们可以用dict来存储上述的树形结构,还是以上述敏感词为例,我们把每个敏感词字符串拆散成字符,再存储到dict中,可以这样存: 首先将每个词的第一个字符作为key,value则是另一个dict,value对应的dict的key为第二个字符,如果还有第三个字符,则存储到以第二个字符为key的value中,当然这个value还是一个dict,以此类推下去,直到最后一个字符,当然最后一个字符对应的value也是dict,只不过这个dict只需要存储一个结束标志就行了,像上述的例子中,我们就存了一个{‘\x00‘: 0}的dict,来表示这个value对应的key是敏感词的最后一个字符。 同理,“坏人”和“坏蛋”这2个敏感词也是按这样的方式存储起来,这里就不罗列出来了。 用dict存储有什么好处呢?我们知道dict在理想情况下可以以O(1)的时间复杂度进行查询,所以我们在遍历待检测字符串的过程中,可以以O(1)的时间复杂度检索出当前字符是否在敏感词库中,效率比方案一提升太多了。 接下来上代码。 sensitive_words.txt 运行结果 AC自动机:一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。 1.replace过滤
2.使用正则过滤
2.在正则表达式语法中,竖线“|”表示二选一或多选一。
代码参考
3.DFA过滤敏感词算法
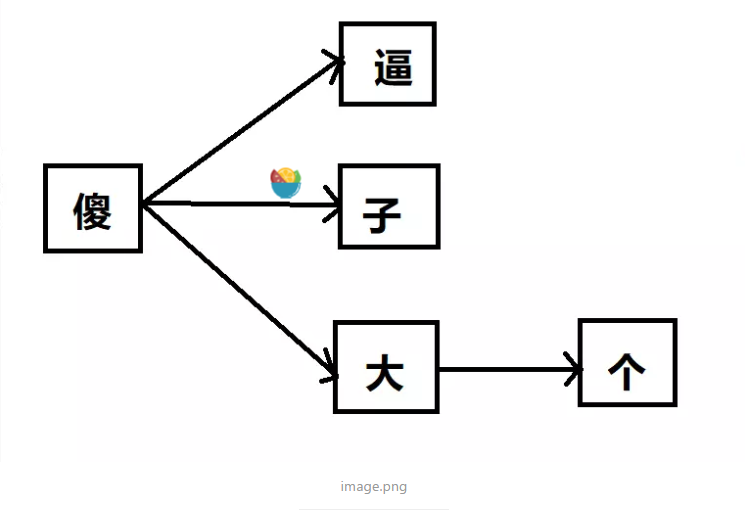
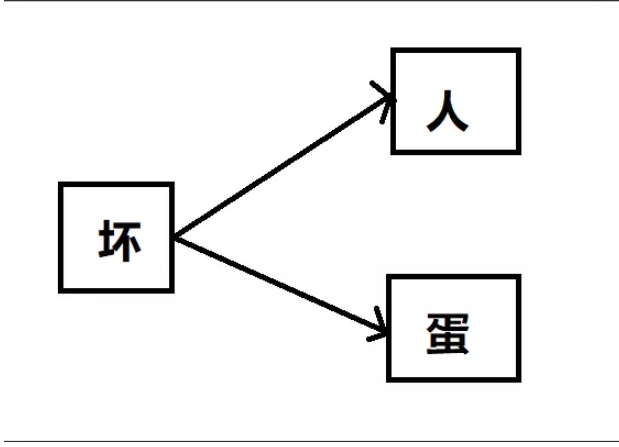
4.AC自动机过滤敏感词算法
简单地讲,AC自动机就是字典树+kmp算法+失配指针