全国315个城市,用python爬取肯德基老爷爷的店面信息
2021-02-03 07:14
标签:香港 城市 ddr htm 步骤 url路径 name 序列化 循环 我觉得我生活在这世上二十多年里,去过最多的餐厅就是肯德基小时候逢生日必去,现在长大了,肯德基成了我的日常零食下班后从门前路过饿了便会进去点分黄金鸡块或者小吃拼盘早上路过,会买杯咖啡。主要快捷美味且饱腹,而且到处都是总是会路过,现在只要一饿,心心念念便是肯德基的味道 python 3.6 pycharm requests csv 1、确定爬取的url路径,headers参数 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据 3、解析数据 4、保存数据 1、确定爬取的url路径,headers参数 先爬取北京的数据 2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据 3、解析数据 4、保存数据 5、全国315个城市的数据 获取拉勾网315个城市的数据 如果你处于想学Python或者正在学习Python,Python的教程不少了吧,但是是最新的吗?说不定你学了可能是两年前人家就学过的内容,在这小编分享一波2020最新的Python教程。获取方式,私信小编 “ 资料 ”,即可免费获取哦! 全国315个城市,用python爬取肯德基老爷爷的店面信息 标签:香港 城市 ddr htm 步骤 url路径 name 序列化 循环 原文地址:https://www.cnblogs.com/python0921/p/12804244.html
环境介绍
爬虫的一般思路
步骤
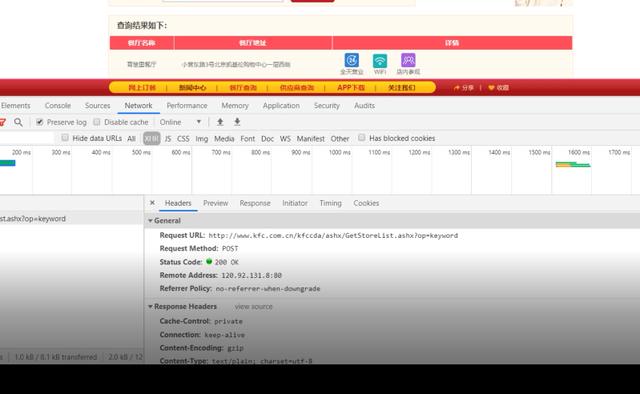
base_url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
headers = {‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36‘}
data = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: ‘北京‘,
‘pageIndex‘: ‘1‘,
‘pageSize‘: ‘10‘,
}
response = requests.post(url=base_url, headers=headers, data=data)
json_data = response.json()
# pprint.pprint(json_data)
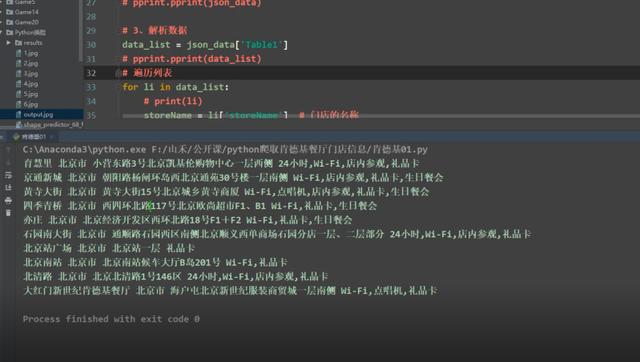
data_list = json_data[‘Table1‘]
# pprint.pprint(data_list)
# 构建循环,解析数据字段
for ls in data_list:
storeName = ls[‘storeName‘] + ‘餐厅‘ # 餐厅名称
cityName = ls[‘cityName‘] # 餐厅城市
addressDetail = ls[‘addressDetail‘] # 餐厅地址
pro = ls[‘pro‘] # 餐厅详情
# print(storeName, cityName, addressDetail, pro)
print(‘正在爬取:‘, storeName)
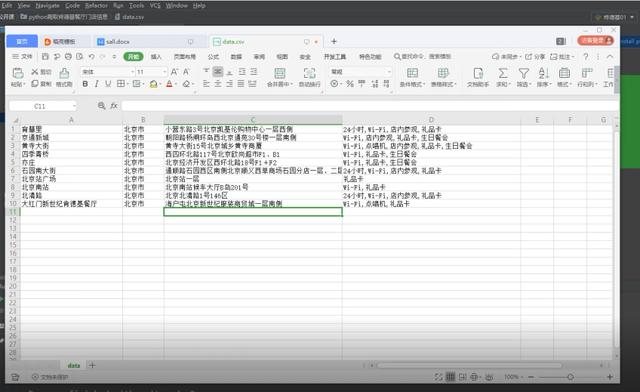
with open(‘data.csv‘, ‘a‘, newline=‘‘) as csvfile: # newline=‘‘ 指定一行一行写入
csvwriter = csv.writer(csvfile, delimiter=‘,‘) # delimiter=‘,‘ csv数据的分隔符
csvwriter.writerow([storeName, cityName, addressDetail, pro]) # 序列化数据,写入csv

# coding:utf-8
import requests
import csv
import time
import random
ip = [{‘HTTP‘: ‘1.199.31.213:9999‘}, {‘HTTP‘: ‘182.46.197.33:9999‘}, {‘HTTP‘: ‘58.18.133.101:56210‘},
{‘HTTP‘: ‘175.44.108.123:9999‘}, {‘HTTP‘: ‘123.52.97.90:9999‘}, {‘HTTP‘: ‘182.92.233.137:8118‘},
{‘HTTP‘: ‘223.242.225.42:9999‘}, {‘HTTP‘: ‘113.194.28.84:9999‘}, {‘HTTP‘: ‘113.194.30.115:9999‘},
{‘HTTP‘: ‘113.195.19.41:9999‘}, {‘HTTP‘: ‘144.123.69.123:9999‘}, {‘HTTP‘: ‘27.192.168.202:9000‘},
{‘HTTP‘: ‘163.204.244.179:9999‘}, {‘HTTP‘: ‘112.84.53.197:9999‘}, {‘HTTP‘: ‘117.69.13.69:9999‘},
{‘HTTP‘: ‘1.197.203.214:9999‘}, {‘HTTP‘: ‘125.108.111.22:9000‘}, {‘HTTP‘: ‘171.35.169.69:9999‘},
{‘HTTP‘: ‘171.15.173.234:9999‘}, {‘HTTP‘: ‘171.13.103.52:9999‘}, {‘HTTP‘: ‘183.166.97.201:9999‘},
{‘HTTP‘: ‘60.2.44.182:44990‘}, {‘HTTP‘: ‘58.253.158.21:9999‘}, {‘HTTP‘: ‘47.94.89.87:3128‘},
{‘HTTP‘: ‘60.13.42.235:9999‘}, {‘HTTP‘: ‘60.216.101.46:32868‘}, {‘HTTP‘: ‘117.90.137.91:9000‘},
{‘HTTP‘: ‘123.169.164.163:9999‘}, {‘HTTP‘: ‘123.169.162.230:9999‘}, {‘HTTP‘: ‘125.108.119.189:9000‘},
{‘HTTP‘: ‘163.204.246.68:9999‘}, {‘HTTP‘: ‘223.100.166.3:36945‘}, {‘HTTP‘: ‘113.195.18.134:9999‘},
{‘HTTP‘: ‘163.204.245.50:9999‘}, {‘HTTP‘: ‘125.108.79.50:9000‘}, {‘HTTP‘: ‘163.125.220.205:8118‘},
{‘HTTP‘: ‘1.198.73.246:9999‘}, {‘HTTP‘: ‘175.44.109.51:9999‘}, {‘HTTP‘: ‘121.232.194.47:9000‘},
{‘HTTP‘: ‘113.194.30.27:9999‘}, {‘HTTP‘: ‘129.28.183.30:8118‘}, {‘HTTP‘: ‘123.169.165.73:9999‘},
{‘HTTP‘: ‘120.83.99.190:9999‘}, {‘HTTP‘: ‘175.42.128.48:9999‘}, {‘HTTP‘: ‘123.101.212.223:9999‘},
{‘HTTP‘: ‘60.190.250.120:8080‘}, {‘HTTP‘: ‘125.94.44.129:1080‘}, {‘HTTP‘: ‘118.112.195.91:9999‘},
{‘HTTP‘: ‘110.243.5.163:9999‘}, {‘HTTP‘: ‘118.89.91.108:8888‘}, {‘HTTP‘: ‘125.122.199.13:9000‘},
{‘HTTP‘: ‘171.11.28.248:9999‘}, {‘HTTP‘: ‘211.152.33.24:39406‘}, {‘HTTP‘: ‘59.62.35.130:9000‘},
{‘HTTP‘: ‘123.163.96.124:9999‘}]
def get_page(keyword):
global base_url
base_url = ‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘
global headers
headers = {
‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36‘}
data = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: keyword,
‘pageIndex‘: ‘1‘,
‘pageSize‘: ‘10‘,
}
try:
response = requests.post(url=base_url, headers=headers, data=data)
json_data = response.json()
page = json_data[‘Table‘][0][‘rowcount‘]
if page % 10 > 0:
page_num = page // 10 + 1
else:
page_num = page // 10
return page_num
except Exception as e:
print(e)
def send_request(keyword):
page_num = get_page(keyword)
try:
for page in range(1, page_num + 1):
print(‘============正在获取第{}页信息==========‘.format(page))
data = {
‘cname‘: ‘‘,
‘pid‘: ‘‘,
‘keyword‘: keyword,
‘pageIndex‘: str(page),
‘pageSize‘: ‘10‘,
}
response = requests.post(url=base_url, headers=headers, data=data, proxies=random.choice(ip),timeout=3)
json_data = response.json()
# pprint.pprint(json_data)
time.sleep(0.4)
# 3、解析数据
data_list = json_data[‘Table1‘]
# pprint.pprint(data_list)
# 构建循环,解析数据字段
for ls in data_list:
storeName = ls[‘storeName‘] + ‘餐厅‘ # 餐厅名称
cityName = ls[‘cityName‘] # 餐厅城市
addressDetail = ls[‘addressDetail‘] # 餐厅地址
pro = ls[‘pro‘] # 餐厅详情
# print(storeName, cityName, addressDetail, pro)
# 4、保存数据
print(‘正在爬取:‘, storeName)
with open(‘data5.csv‘, ‘a‘, newline=‘‘) as csvfile: # newline=‘‘ 指定一行一行写入
csvwriter = csv.writer(csvfile, delimiter=‘,‘) # delimiter=‘,‘ csv数据的分隔符
csvwriter.writerow([storeName, cityName, addressDetail, pro]) # 序列化数据,写入csv
time.sleep(0.2)
except Exception as e:
print(e)
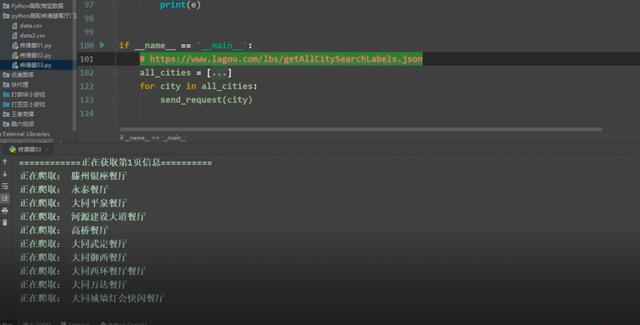
if __name__ == ‘__main__‘:
# https://www.lagou.com/lbs/getAllCitySearchLabels.json
all_cities = [‘安阳‘, ‘安庆‘, ‘鞍山‘, ‘澳门特别行政区‘, ‘安顺‘, ‘阿勒泰‘, ‘安康‘, ‘阿克苏‘, ‘阿坝藏族羌族自治州‘, ‘阿拉善盟‘, ‘北京‘, ‘保定‘, ‘蚌埠‘, ‘滨州‘,
‘包头‘, ‘宝鸡‘, ‘北海‘, ‘亳州‘, ‘百色‘, ‘毕节‘, ‘巴中‘, ‘本溪‘, ‘巴音郭楞‘, ‘巴彦淖尔‘, ‘博尔塔拉‘, ‘保山‘, ‘白城‘, ‘白山‘, ‘成都‘, ‘长沙‘,
‘重庆‘, ‘长春‘, ‘常州‘, ‘沧州‘, ‘赤峰‘, ‘郴州‘, ‘潮州‘, ‘常德‘, ‘朝阳‘, ‘池州‘, ‘滁州‘, ‘承德‘, ‘昌吉‘, ‘楚雄‘, ‘崇左‘, ‘东莞‘, ‘大连‘,
‘德州‘, ‘德阳‘, ‘大庆‘, ‘东营‘, ‘大同‘, ‘达州‘, ‘大理‘, ‘德宏‘, ‘丹东‘, ‘定西‘, ‘儋州‘, ‘迪庆‘, ‘鄂州‘, ‘恩施‘, ‘鄂尔多斯‘, ‘佛山‘,
‘福州‘, ‘阜阳‘, ‘抚州‘, ‘抚顺‘, ‘阜新‘, ‘防城港‘, ‘广州‘, ‘贵阳‘, ‘桂林‘, ‘赣州‘, ‘广元‘, ‘贵港‘, ‘广安‘, ‘固原‘, ‘甘孜藏族自治州‘, ‘杭州‘,
‘合肥‘, ‘惠州‘, ‘哈尔滨‘, ‘海口‘, ‘呼和浩特‘, ‘邯郸‘, ‘衡阳‘, ‘湖州‘, ‘淮安‘, ‘海外‘, ‘菏泽‘, ‘衡水‘, ‘河源‘, ‘怀化‘, ‘黄冈‘, ‘黄石‘,
‘黄山‘, ‘淮北‘, ‘淮南‘, ‘葫芦岛‘, ‘呼伦贝尔‘, ‘汉中‘, ‘红河‘, ‘贺州‘, ‘河池‘, ‘鹤壁‘, ‘鹤岗‘, ‘海东‘, ‘哈密‘, ‘济南‘, ‘金华‘, ‘嘉兴‘,
‘济宁‘, ‘江门‘, ‘晋中‘, ‘吉林‘, ‘九江‘, ‘揭阳‘, ‘焦作‘, ‘荆州‘, ‘锦州‘, ‘荆门‘, ‘吉安‘, ‘景德镇‘, ‘晋城‘, ‘佳木斯‘, ‘酒泉‘, ‘济源‘,
‘昆明‘, ‘开封‘, ‘克拉玛依‘, ‘喀什‘, ‘兰州‘, ‘临沂‘, ‘廊坊‘, ‘洛阳‘, ‘柳州‘, ‘六安‘, ‘聊城‘, ‘连云港‘, ‘吕梁‘, ‘泸州‘, ‘拉萨‘, ‘丽水‘,
‘乐山‘, ‘龙岩‘, ‘临汾‘, ‘漯河‘, ‘六盘水‘, ‘凉山彝族自治州‘, ‘丽江‘, ‘娄底‘, ‘莱芜‘, ‘辽源‘, ‘陇南‘, ‘临夏‘, ‘来宾‘, ‘绵阳‘, ‘茂名‘, ‘马鞍山‘,
‘梅州‘, ‘牡丹江‘, ‘眉山‘, ‘南京‘, ‘宁波‘, ‘南昌‘, ‘南宁‘, ‘南通‘, ‘南阳‘, ‘南充‘, ‘宁德‘, ‘南平‘, ‘内江‘, ‘莆田‘, ‘濮阳‘, ‘萍乡‘,
‘平顶山‘, ‘盘锦‘, ‘攀枝花‘, ‘平凉‘, ‘普洱‘, ‘青岛‘, ‘泉州‘, ‘清远‘, ‘秦皇岛‘, ‘曲靖‘, ‘衢州‘, ‘齐齐哈尔‘, ‘黔西南‘, ‘黔南‘, ‘钦州‘, ‘黔东南‘,
‘庆阳‘, ‘七台河‘, ‘日照‘, ‘深圳‘, ‘上海‘, ‘苏州‘, ‘沈阳‘, ‘石家庄‘, ‘绍兴‘, ‘汕头‘, ‘宿迁‘, ‘商丘‘, ‘三亚‘, ‘上饶‘, ‘宿州‘, ‘邵阳‘,
‘十堰‘, ‘遂宁‘, ‘韶关‘, ‘三门峡‘, ‘汕尾‘, ‘随州‘, ‘三沙‘, ‘三明‘, ‘绥化‘, ‘石嘴山‘, ‘四平‘, ‘朔州‘, ‘商洛‘, ‘松原‘, ‘天津‘, ‘太原‘,
‘唐山‘, ‘台州‘, ‘泰安‘, ‘泰州‘, ‘天水‘, ‘通辽‘, ‘铜陵‘, ‘台湾‘, ‘铜仁‘, ‘铜川‘, ‘铁岭‘, ‘塔城‘, ‘天门‘, ‘通化‘, ‘武汉‘, ‘无锡‘, ‘温州‘,
‘潍坊‘, ‘乌鲁木齐‘, ‘芜湖‘, ‘威海‘, ‘梧州‘, ‘渭南‘, ‘吴忠‘, ‘乌兰察布‘, ‘文山‘, ‘乌海‘, ‘西安‘, ‘厦门‘, ‘徐州‘, ‘新乡‘, ‘西宁‘, ‘咸阳‘,
‘许昌‘, ‘邢台‘, ‘孝感‘, ‘襄阳‘, ‘香港特别行政区‘, ‘湘潭‘, ‘信阳‘, ‘忻州‘, ‘咸宁‘, ‘宣城‘, ‘西双版纳‘, ‘湘西土家族苗族自治州‘, ‘新余‘, ‘兴安盟‘,
‘烟台‘, ‘扬州‘, ‘银川‘, ‘盐城‘, ‘宜春‘, ‘岳阳‘, ‘宜昌‘, ‘阳江‘, ‘玉溪‘, ‘玉林‘, ‘益阳‘, ‘运城‘, ‘宜宾‘, ‘榆林‘, ‘云浮‘, ‘营口‘, ‘永州‘,
‘延安‘, ‘鹰潭‘, ‘伊犁‘, ‘延边‘, ‘阳泉‘, ‘雅安‘, ‘郑州‘, ‘珠海‘, ‘中山‘, ‘株洲‘, ‘淄博‘, ‘遵义‘, ‘湛江‘, ‘肇庆‘, ‘镇江‘, ‘张家口‘, ‘周口‘,
‘驻马店‘, ‘漳州‘, ‘枣庄‘, ‘长治‘, ‘昭通‘, ‘舟山‘, ‘资阳‘, ‘张掖‘, ‘自贡‘, ‘中卫‘, ‘张家界‘]
for city in all_cities:
send_request(city)
文章标题:全国315个城市,用python爬取肯德基老爷爷的店面信息
文章链接:http://soscw.com/index.php/essay/50306.html